Hologres のベクトル計算は、類似検索、画像検索、シーン認識などのアプリケーションに有効です。ベクトル計算を活用することで、データの処理・分析をより効果的に行い、精度の高い検索およびレコメンデーション機能を構築できます。本トピックでは、Hologres における Proxima を用いたベクトル計算の方法を説明し、完全な実行例を示します。
操作手順
Hologres への接続
開発ツールを使用して Hologres に接続します。詳細については、「開発ツールへの接続」をご参照ください。Java Database Connectivity (JDBC) 接続を利用する場合は、Prepare Statement モードをご利用ください。
Proxima 拡張のインストール
Proxima は拡張として Hologres に接続されます。Proxima を使用する前に、スーパーユーザーが以下のコマンドを実行して Proxima 拡張をインストールする必要があります。
-- Proxima 拡張のインストール CREATE EXTENSION proxima;Proxima 拡張はデータベース単位でインストールされます。各データベースに対して 1 回のみのインストールで十分です。拡張をアンインストールするには、以下のコマンドを実行します。
DROP EXTENSION proxima;重要拡張のアンインストールには、DROP EXTENSION <extension_name> CASCADE; コマンドを実行しないでください。
CASCADEオプションを指定すると、対象の拡張に加えて、すべての拡張データおよび依存オブジェクトが削除されます。拡張データには、PostGIS データ、RoaringBitmap データ、Proxima データ、バイナリロギング (Binlog) データ、BSI データなどが含まれます。依存オブジェクトには、メタデータ、テーブル、ビュー、サーバーデータなどが含まれます。ベクトルテーブルおよびベクトルインデックスの作成
Hologres では、ベクトルは通常 FLOAT4 配列として表現されます。ベクトルテーブルを作成する構文は以下のとおりです。
説明ベクトルインデックスは、列指向テーブルおよびハイブリッド行列表(行・列混合テーブル)でのみサポートされています。行指向テーブルではサポートされていません。
ベクトルを定義する際、配列のディメンションは
1である必要があります。これは、array_ndimsおよびarray_lengthの第 2 入力パラメーターが1であることを意味します。Hologres V2.0.11 以降では、ベクトルインデックスの作成前にデータをインポートできます。この方法により、コンパクション時のファイルに対するベクトルインデックス構築を回避でき、インデックス作成時間を短縮できます。
データインポート前にベクトルインデックスを作成する:リアルタイムデータのシナリオに適しています。
-- 単一インデックスの設定 BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) -- ベクトルの定義 ); CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -- ベクトルインデックスの構築 COMMIT; -- 複数インデックスの設定 BEGIN; CREATE TABLE t1 ( f1 INT PRIMARY KEY, f2 FLOAT4[] NOT NULL CHECK(array_ndims(f2) = 1 AND array_length(f2, 1) = 4), f3 FLOAT4[] NOT NULL CHECK(array_ndims(f3) = 1 AND array_length(f3, 1) = 4) ); CALL set_table_property( 't1', 'proxima_vectors', '{"f2":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}, "f3":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT;データインポート後にベクトルインデックスを作成する:バッチ分析のシナリオに適しています。
説明Hologres V2.1.17 以降では、サーバーレスコンピューティングがサポートされています。大量のベクトルデータをバッチインポートまたはクエリするシナリオでは、サーバーレスコンピューティングを使用してこれらのタスクを実行できます。このアプローチでは、ご利用のインスタンスのリソースではなく追加のサーバーレスリソースが使用されるため、インスタンスのリソースを事前に確保する必要はありません。これにより、インスタンスの安定性が大幅に向上し、メモリ不足 (OOM) エラーの発生確率が低下します。課金は実行されたタスクに対してのみ発生します。サーバーレスコンピューティングの詳細については、「サーバーレスコンピューティング」をご参照ください。サーバーレスコンピューティングの使用方法については、「サーバーレスコンピューティングの使用ガイド」をご参照ください。
-- 単一インデックスの設定 BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) -- ベクトルの定義 ); COMMIT; -- (任意)大規模なバッチインポートおよび ETL ジョブをサーバーレスコンピューティングで実行 SET hg_computing_resource = 'serverless'; -- データのインポート INSERT INTO feature_tb ...; VACUUM feature_tb; -- ベクトルインデックスの構築 CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -- 不要な SQL ステートメントがサーバーレスリソースを使用しないよう、構成をリセットします。 RESET hg_computing_resource;
以下の表に、各パラメーターを示します。
カテゴリ
パラメーター
説明
例
基本ベクトルプロパティ
feature_col
ベクトル列の名前。
feature
array_ndims
ベクトルのディメンション。1 次元ベクトルのみサポートされます。
以下は、長さ 4 の 1 次元ベクトルを作成する例です。
feature float4[] check(array_ndims(feature) = 1 and array_length(feature, 1) = 4)array_length
ベクトルの長さ。最大長は 1,000,000 です。
ベクトルインデックス
proxima_vectors
ベクトルインデックスを構築することを指定します。以下のパラメーターを含みます:
algorithm:ベクトルインデックス構築に使用するアルゴリズムを指定します。現在は
Graphのみがサポートされています。distance_method:ベクトルインデックス構築に使用する距離計算方法を定義します。以下の距離関数がサポートされています:
(推奨)SquaredEuclidean:二乗ユークリッド距離。クエリ効率が最も高くなります。
pm_approx_squared_euclidean_distanceを使用するクエリに適しています。Euclidean:ユークリッド距離。ただし、
pm_approx_euclidean_distanceを使用するクエリにのみ適しています。他の距離関数を使用すると、インデックスは使用されません。(非推奨)InnerProduct:内積距離。これは基盤レイヤーでユークリッド距離計算に変換されます。これにより、インデックス構築およびインデックスクエリの両方において追加の計算オーバーヘッドが発生し、効率が低下します。ビジネス要件が強く求められない限り、この方法の使用は避けてください。
pm_approx_inner_product_distanceを使用するクエリにのみ適しています。
builder_params:インデックス構築のパラメーターを制御します。これは、以下のパラメーターを含む JSON 形式の文字列です。
min_flush_proxima_row_count:データをディスクに書き込む際にインデックスを構築するために必要な最小行数。推奨値は 1000 です。
min_compaction_proxima_row_count:データをディスク上でマージする際にインデックスを構築するために必要な最小行数。推奨値は 1000 です。
max_total_size_to_merge_mb:ディスク上のデータマージにおける最大ファイルサイズ(単位:MB)。推奨値は 2000 です。
proxima_builder_thread_count:データ書き込み時のベクトルインデックス構築に使用されるスレッド数を制御します。デフォルト値は 4 です。ほとんどのシナリオでは、この値を変更する必要はありません。
説明インデックスは特定のシナリオで最も効果的に機能します。
以下は、二乗ユークリッド距離を使用するクエリ向けにベクトルインデックスを構築する例です。
call set_table_property( 'feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph", "distance_method":"SquaredEuclidean", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}');ベクトルデータのインポート
ベクトルテーブルへは、バッチモードまたはリアルタイムモードでデータをインポートできます。 ご要件に応じて、適切な同期方法を選択してください。バッチインポート後は、クエリ効率を向上させるために VACUUM および ANALYZE コマンドを実行します。
VACUUM は、バックエンドファイルをより大きなファイルにコンパクト化してクエリ効率を向上させます。ただし、VACUUM は CPU リソースを消費します。テーブルのデータ量が大きいほど、VACUUM 操作の実行時間は長くなります。VACUUM 操作が実行中の場合は、完了までお待ちください。
VACUUM <tablename>;ANALYZE はパフォーマンス統計を収集します。クエリオプティマイザ (QO) はこれらの統計を使用して、より優れた実行計画を生成し、クエリパフォーマンスを向上させます。
analyze <tablename>;
ベクトルデータのクエリ
Hologres では、正確なベクトルクエリおよび近似ベクトルクエリの両方がサポートされています。
pm_で始まるユーザー定義関数 (UDF) は正確なクエリ用であり、pm_approx_で始まる UDF は近似クエリ用です。ベクトルインデックスを使用できるのは、pm_approx_ で始まる近似クエリのみです。ベクトルインデックスが構築されているシナリオでは、効率を高めるために近似クエリをご利用ください。ベクトルインデックスは単一テーブルクエリでのみ使用可能です。そのため、単一テーブルのベクトルクエリを使用し、結合操作は避けてください。近似クエリ(ベクトルインデックスを使用)
近似クエリではベクトルインデックスが使用可能です。大量のデータをスキャンし、高い実行効率が求められるシナリオに適しています。デフォルトの取得率は 99 % を超えます。ベクトルインデックスを使用するには、対応する距離関数に
approx_プレフィックスを付加します。サポートされる距離関数は以下のとおりです:説明二乗ユークリッド距離またはユークリッド距離を使用する近似クエリでは、
order by distance ascを指定した場合のみベクトルインデックスが使用可能です。降順はサポートされていません。内積距離を使用する近似クエリでは、
order by distance descを指定した場合のみベクトルインデックスが使用可能です。昇順はサポートされていません。
FLOAT4 pm_approx_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_inner_product_distance(FLOAT4[], FLOAT4[])クエリで使用される関数は、テーブル作成時に指定された
distance_methodのproxima_vectorパラメーターと一致する必要があります。次の例では、上位 N 件の結果をクエリする方法を示します。近似クエリでは、2 番目のパラメーターは定数値である必要があります。説明インデックスクエリはロスの伴う処理であり、精度の一部を失う可能性があります。デフォルトの取得率は通常 99 % を超えます。
-- 二乗ユークリッド距離による TOP K の計算。テーブル作成時に proxima_vector パラメーターの distance_method は SquaredEuclidean である必要があります。 SELECT pm_approx_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- ユークリッド距離による TOP K の計算。テーブル作成時に proxima_vector パラメーターの distance_method は Euclidean である必要があります。 SELECT pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 内積距離による TOP K の計算。テーブル作成時に proxima_vector パラメーターの distance_method は InnerProduct である必要があります。 SELECT pm_approx_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;正確なクエリ(ベクトルインデックスを使用しない)
正確なクエリは、SQL ステートメントが少量のデータをスキャンし、高い取得率が求められるシナリオに適しています。以下の 3 つの距離関数は、それぞれユークリッド距離、二乗ユークリッド距離、内積距離の計算方法に対応しています:
FLOAT4 pm_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_inner_product_distance(FLOAT4[], FLOAT4[])ターゲットベクトルに対する上位 K 個の最近傍を取得するには、以下の SQL ステートメントを使用します。
説明この例の SQL ステートメントは正確な取得計算を実行します。実行プロセスは以下のとおりです: feature 列内のすべてのベクトルをスキャンして距離を計算し、結果をソートしてから上位 10 件のレコードを返します。このタイプの SQL ステートメントは、データ量が少なく、非常に高い取得率が求められるシナリオに適しています。
-- 二乗ユークリッド距離による上位 10 個の最近傍の取得 SELECT pm_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- ユークリッド距離による上位 10 個の最近傍の取得 SELECT pm_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 最大の内積距離を持つ上位 10 個の近傍の取得 SELECT pm_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;
完全な実行例
この例では、Proxima インデックスを使用して、100,000 4 次元のベクターテーブルから、二乗ユークリッド距離に基づいて 40 個の最も近いベクターを取得する方法を示します。
ベクトルテーブルの作成
CREATE EXTENSION proxima; BEGIN; -- shard_count = 4 のテーブルグループを作成 CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE feature_tb ( id BIGINT, feature FLOAT4[] CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = 4) ); CALL set_table_property ('feature_tb', 'table_group', 'test_tg_shard_4'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params": {"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT;データのインポート
-- (任意)大規模なバッチインポートおよび ETL ジョブをサーバーレスコンピューティングで実行 SET hg_computing_resource = 'serverless'; INSERT INTO feature_tb SELECT i, ARRAY[random(), random(), random(), random()]::FLOAT4[] FROM generate_series(1, 100000) i; ANALYZE feature_tb; VACUUM feature_tb; -- 不要な SQL ステートメントがサーバーレスリソースを使用しないよう、構成をリセットします。 RESET hg_computing_resource;クエリの実行
-- (任意)大規模なベクトルクエリジョブをサーバーレスコンピューティングで実行 SET hg_computing_resource = 'serverless'; SELECT pm_approx_squared_euclidean_distance (feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance LIMIT 40; -- 不要な SQL ステートメントがサーバーレスリソースを使用しないよう、構成をリセットします。 RESET hg_computing_resource;
パフォーマンス最適化
ベクトルインデックスを設定するシナリオ
データ量が少ない(例:数万件程度)場合、インデックスを設定せずに直接距離を計算できます。また、ご利用のインスタンスに十分なリソースがあり、クエリ対象のデータ量が小さい場合も、直接計算が可能です。ただし、直接計算ではレイテンシーまたはスループットの要件を満たせない場合は、Proxima インデックスの使用を検討してください。その際、以下の点に注意してください。
Proxima はロスの伴うインデックスであり、結果の正確性を保証しません。計算された距離にはバイアスが生じる可能性があります。
Proxima インデックスでは、取得されるレコード数が不足する場合があります。たとえば、
limit 1000を指定しても、500 件しか返らない場合があります。Proxima インデックスの使用は難しい場合があります。
適切な Shard Count の設定
Shard 数が多いほど、Proxima インデックスファイルの数も増加し、クエリスループットが低下します。実際には、ご利用のインスタンスのリソースに応じて、妥当な Shard Count を設定してください。通常、ワーカー数に合わせて Shard Count を設定できます。たとえば、64 コアのインスタンスの場合、Shard Count を 4 に設定できます。単一クエリのレイテンシーを低減するには Shard Count を減らすことも可能ですが、書き込みパフォーマンスも低下します。
-- ベクトルテーブルを作成し、shard_count = 4 のテーブルグループに配置 BEGIN; CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE proxima_test ( id BIGINT NOT NULL, vectors FLOAT4[] CHECK (array_ndims(vectors) = 1 AND array_length(vectors, 1) = 128), PRIMARY KEY (id) ); CALL set_table_property ('proxima_test', 'proxima_vectors', '{"vectors":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params":{}, "searcher_init_params":{}}}'); CALL set_table_property ('proxima_test', 'table_group', 'test_tg_shard_4'); COMMIT;(推奨)フィルター条件なしのクエリシナリオ
whereフィルター条件があると、インデックスの使用に影響を与え、パフォーマンスが劣化する可能性があります。そのため、フィルター条件なしのクエリの使用を推奨します。フィルター条件なしのベクトル検索では、理想的には各シャードに 1 つのベクトルインデックスファイルのみが存在します。これにより、クエリは単一のシャード上で処理されます。フィルター条件なしのクエリシナリオでは、通常以下のようにテーブルを作成できます。
BEGIN; CREATE TABLE feature_tb ( uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) -- ベクトルの定義 ); CALL set_table_property ('feature_tb', 'shard_count', '?'); -- Shard Count を指定します。ご要件に応じて適切に設定してください。不要な場合は省略可能です。 CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}'); -- ベクトルインデックスの構築 END;フィルター条件ありのクエリシナリオ
フィルター条件ありのベクトル検索では、以下の一般的なフィルタリングシナリオに分類できます。
クエリシナリオ 1:文字列列をフィルター条件として使用
以下はサンプルクエリです。一般的なシナリオとして、組織内での対応するベクトルデータを検索することが挙げられます(例:特定のクラス内の顔データを検索)。
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE uuid = 'x' ORDER BY d limit 10;以下の最適化を推奨します。
uuid を分散キーとして設定します。これにより、同じフィルター条件を持つデータが同一のシャードに格納され、クエリが単一のシャード上で処理されます。
uuid をテーブルのクラスタリングキーとして設定します。これにより、ファイル内でクラスタリングキーに基づいてデータが並べ替えられます。
クエリシナリオ 2:時刻フィールドをフィルター条件として使用
以下はサンプルクエリです。通常、時刻フィールドは対応するベクトルデータをフィルターするために使用されます。time_field をテーブルのセグメントキーとして設定できます。これにより、データが格納されているファイルを迅速に特定できます。
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE time_field BETWEEN '2020-08-30 00:00:00' AND '2020-08-30 12:00:00' ORDER BY d limit 10;
したがって、フィルター条件ありのベクトル検索では、通常以下のようにテーブルを作成できます。
BEGIN; CREATE TABLE feature_tb ( time_field timestamptz NOT NULL, uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) ); CALL set_table_property ('feature_tb', 'distribution_key', 'uuid'); CALL set_table_property ('feature_tb', 'segment_key', 'time_field'); CALL set_table_property ('feature_tb', 'clustering_key', 'uuid'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}}'); COMMIT; -- 時刻によるフィルターを行わない場合は、time_field に関連するインデックスを削除できます。
よくある質問
エラー:
ERROR: function pm_approx_inner_product_distance(real[], unknown) does not exist原因:このエラーは、Proxima 拡張を初期化するためにデータベースで
create extension proxima;ステートメントが実行されていない場合に発生します。解決策:
create extension proxima;ステートメントを実行して Proxima 拡張を初期化してください。エラー:
Writing column: feature with array size: 5 violates fixed size list (4) constraint declared in schema原因:feature ベクトル列に書き込まれたデータのディメンションが、テーブルで定義されたディメンションと一致していないためです。
解決策:ダーティデータを確認してください。
エラー:
The size of two arrays must be the same in DistanceFunction, size of left array: 4, size of right array:原因:
pm_xx_distance(left, right)内で、`left` のディメンションが `right` のディメンションと一致しません。解決策:
pm_xx_distance(left, right)で `left` のディメンションと `right` のディメンションが一致することを確認してください。リアルタイム書き込みエラー:
BackPressure Exceed Reject Limit ctxId: XXXXXXXX, tableId: YY, shardId: ZZ原因:リアルタイム書き込みジョブでボトルネックが発生し、バックプレッシャー例外が発生しています。この例外は、書き込みジョブのオーバーヘッドが高く、処理が遅いことを示しています。通常、min_flush_proxima_row_count の値が小さく、リアルタイム書き込み速度が高い場合に発生します。これにより、リアルタイムインデックス構築のオーバーヘッドが高まり、リアルタイム書き込みプロセスがブロックされます。
解決策:min_flush_proxima_row_count の値を増加させてください。
Java を使用したベクトルデータの書き込み方法
以下は、Java を使用したベクトルデータの書き込み例です。
private static void insertIntoVector(Connection conn) throws Exception { try (PreparedStatement stmt = conn.prepareStatement("insert into feature_tb values(?,?);")) { for (int i = 0; i < 100; ++i) { stmt.setInt(1, i); Float[] featureVector = {0.1f,0.2f,0.3f,0.4f}; Array array = conn.createArrayOf("FLOAT4", featureVector); stmt.setArray(2, array); stmt.execute(); } } }実行計画から Proxima インデックスの使用状況を確認する方法
実行計画に
Proxima filter: xxxxが含まれている場合、インデックスが使用されています(下図参照)。含まれていない場合は、インデックスが使用されていません。この問題は、通常、テーブル作成ステートメントとクエリステートメントが一致していないことが原因です。
距離関数の説明
Hologres では、以下の 3 つのベクトル距離関数がサポートされています:
二乗ユークリッド距離(SquaredEuclidean)。数式は以下のとおりです。
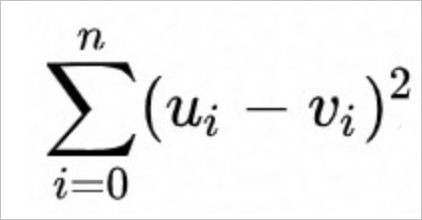
ユークリッド距離(Euclidean)。数式は以下のとおりです。
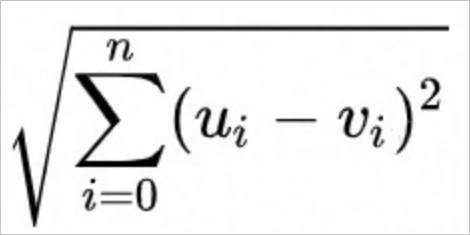
内積距離(InnerProduct)。数式は以下のとおりです。
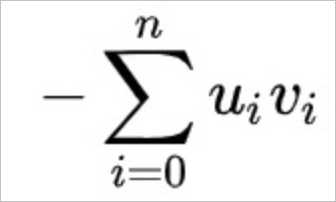
ベクトル計算でユークリッド距離を使用する場合、二乗ユークリッド距離はユークリッド距離よりも平方根計算が 1 回少なく、同じ上位 K 個のレコードを生成します。したがって、二乗ユークリッド距離の方がパフォーマンスが優れています。二乗ユークリッド距離が機能要件を満たす場合は、こちらの使用を推奨します。