本トピックでは、Hologres でクラスタリングキーを使用する方法について説明します。
クラスタリングキーの概要
Hologres は、クラスタリングキーに基づいてファイル内のデータをソートします。クラスタリングキーを作成すると、インデックスが付けられた列に対する範囲クエリやフィルタークエリを高速化できます。テーブルを作成する際に、次の構文を使用してクラスタリングキーを設定できます。
-- Hologres V2.1 以降でサポートされる構文
CREATE TABLE <table_name> (...) WITH (clustering_key = '[<columnName>[,...]]');
-- すべてのバージョンでサポートされる構文
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'clustering_key', '[<columnName>{:asc} [,...]]');
COMMIT;パラメーターの説明:
パラメーター | 説明 |
table_name | クラスタリングキーを設定するテーブルの名前。 |
columnName | クラスタリングキーとして使用するフィールドの名前。 |
使用上の推奨事項
クラスタリングキーは、ポイントクエリと範囲クエリに最適です。
where a = 1やwhere a > 1 and a < 5のようなフィルター操作のパフォーマンスを大幅に向上させます。クラスタリングキーとビットマップ列の両方を設定することで、最適なポイントクエリのパフォーマンスを実現できます。クラスタリングキーは、左端プレフィックス一致の原則に従います。このため、適用可能なシナリオを制限しないように、クラスタリングキーには 2 つを超えるフィールドを設定しないでください。クラスタリングキーはソートに使用されるため、キー内の列の順序が重要です。先にリストされた列ほど、ソートの優先順位が高くなります。
クラスタリングキーのフィールドを指定する際、フィールド名の後に
:ascを追加してインデックス構築のソート順を設定できます。デフォルトのソート順は昇順を指定するascです。Hologres V2.1 より前のバージョンでは、インデックス構築のソート順を降順 (desc) に設定することはできません。ソート順を降順に設定すると、クラスタリングキーがヒットせず、クエリのパフォーマンスが低下します。Hologres V2.1 以降では、次の Grand Unified Configuration (GUC) パラメーターを有効にすることで、クラスタリングキーをdescに設定できます。ただし、この機能は Text、Char、Varchar、Bytea、Int などの型のフィールドでのみサポートされています。他のデータ型のフィールドは、現在クラスタリングキーをdescに設定することをサポートしていません。set hg_experimental_optimizer_enable_variable_length_desc_ck_filter = on;行指向テーブルの場合、クラスタリングキーはデフォルトでプライマリキーになります。Hologres V0.9 より前のバージョンでは、デフォルトは設定されていませんでした。プライマリキーとは異なるクラスタリングキーを設定すると、Hologres はテーブルに対して 2 つのソート順 (1 つはプライマリキー用、もう 1 つはクラスタリングキー用) を作成します。これにより、データ冗長性が発生します。
制限事項
クラスタリングキーを変更するには、テーブルを再作成してデータをインポートする必要があります。
クラスタリングキーは、`NOT NULL` の列または `NOT NULL` の列の組み合わせである必要があります。Hologres V1.3.20 から V1.3.27 までのバージョンでは、Null 値許容のクラスタリングキーがサポートされていました。V1.3.28 以降では、データの正確性に影響を与える可能性があるため、Null 値許容のクラスタリングキーはサポートされていません。ビジネス要件で Null 値許容のクラスタリングキーが必要な場合は、SQL 文の前に次のパラメーターを追加できます。
set hg_experimental_enable_nullable_clustering_key = true;次のデータ型はクラスタリングキーではサポートされていません:Float、Float4、Float8、Double、Decimal(Numeric)、Json、Jsonb、Bit、Varbit、Money、Time With Time Zone、およびその他の複雑なデータ型。
Hologres V2.1 より前のバージョンでは、インデックス構築のソート順を降順 (
desc) に設定することはサポートされていません。ソート順を降順に設定すると、クラスタリングキーがヒットせず、クエリのパフォーマンスが低下します。V2.1 以降では、次の GUC パラメーターを有効にすることで、クラスタリングキーをdescに設定できます。ただし、この機能は Text、Char、Varchar、Bytea、Int などのデータ型のフィールドでのみサポートされています。他のデータ型のフィールドは、現在クラスタリングキーをdescに設定することをサポートしていません。set hg_experimental_optimizer_enable_variable_length_desc_ck_filter = on;列指向テーブルの場合、クラスタリングキーはデフォルトで空です。ビジネスシナリオに基づいて明示的に指定する必要があります。
Hologres では、各テーブルに設定できるクラスタリングキーは 1 つだけです。つまり、テーブルを作成する際に
callコマンドは 1 回しか使用できません。コマンドを複数回実行することはできません。次の例をご参照ください:V2.1 以降でサポートされる構文:
-- 正しい例 CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a,b' ); -- 誤った例 CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a', clustering_key = 'b' );すべてのバージョンでサポートされる構文:
-- 正しい例 BEGIN; CREATE TABLE tbl (a int NOT NULL, b text NOT NULL); CALL set_table_property('tbl', 'clustering_key', 'a,b'); COMMIT; -- 誤った例 BEGIN; CREATE TABLE tbl (a int NOT NULL, b text NOT NULL); CALL set_table_property('tbl', 'clustering_key', 'a'); CALL set_table_property('tbl', 'clustering_key', 'b'); COMMIT;
技術的原則
物理ストレージの観点から、クラスタリングキーはファイル内のデータをソートします。デフォルトの順序は昇順 (asc) です。以下のセクションでは、クラスタリングキーのレイアウトの概念を説明します。
論理レイアウト
クラスタリングキーのクエリは、左端プレフィックス一致の原則に従います。クエリがプレフィックスに一致しない場合、クラスタリングキーを使用して高速化することはできません。次のシナリオは、Hologres におけるクラスタリングキーの論理レイアウトを示しています。
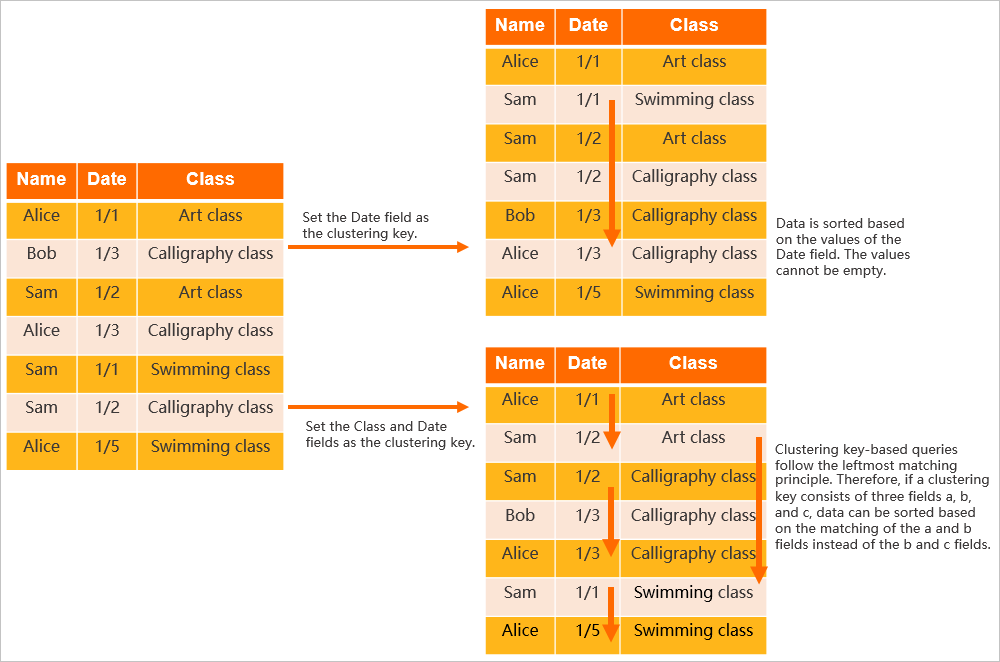
Name、Date、Class のフィールドを持つテーブルを考えます。
Date をクラスタリングキーとして設定した場合、テーブル内のデータは日付順にソートされます。
Class と Date をクラスタリングキーとして設定した場合、データはまずクラスでソートされ、次に日付でソートされます。
クラスタリングキーとして異なるフィールドを設定すると、次の図に示すように、データレイアウトが異なります。
物理ストレージレイアウト
クラスタリングキーの物理ストレージレイアウトを次の図に示します。
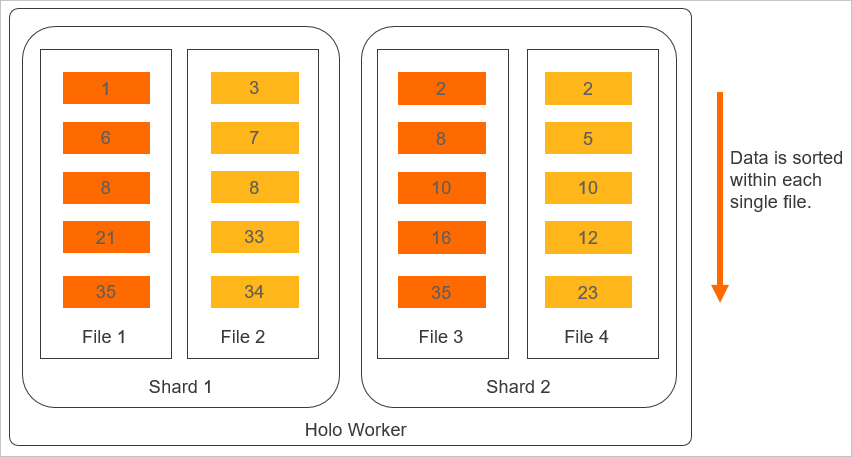
クラスタリングキーのレイアウト原則は、次のことを示しています:
クラスタリングキーは、
where date= 1/1やwhere a > 1/1 and a < 1/5のような条件を持つクエリのパフォーマンスを大幅に向上させるため、範囲フィルタリングのシナリオに適しています。クラスタリングキーのクエリは、左端プレフィックス一致の原則に従います。クエリがプレフィックスに一致しない場合、クラスタリングキーを使用して高速化することはできません。たとえば、列
a,b,cをクラスタリングキーとして設定した場合、a,b,cまたはa,bに対するクエリはクラスタリングキーにヒットします。a,cをクエリした場合、aのみがクラスタリングキーにヒットします。b,cをクエリした場合、クラスタリングキーはヒットしません。
次の例では、列 uid,class,date がクラスタリングキーとして設定されています。
V2.1 以降でサポートされる構文:
CREATE TABLE clustering_test ( uid int NOT NULL, name text NOT NULL, class text NOT NULL, date text NOT NULL, PRIMARY KEY (uid) ) WITH ( clustering_key = 'uid,class,date' ); INSERT INTO clustering_test VALUES (1,'田中 一郎','1','2022-10-19'), (2,'鈴木 次郎','3','2022-10-19'), (3,'佐藤 三郎','2','2022-10-20'), (4,'高橋 四郎','2','2022-10-20'), (5,'伊藤 五郎','2','2022-10-18'), (6,'渡辺 六郎','3','2022-10-17'), (7,'山本 七郎','3','2022-10-20');すべてのバージョンでサポートされる構文:
BEGIN; CREATE TABLE clustering_test ( uid int NOT NULL, name text NOT NULL, class text NOT NULL, date text NOT NULL, PRIMARY KEY (uid) ); CALL set_table_property('clustering_test', 'clustering_key', 'uid,class,date'); COMMIT; INSERT INTO clustering_test VALUES (1,'田中 一郎','1','2022-10-19'), (2,'鈴木 次郎','3','2022-10-19'), (3,'佐藤 三郎','2','2022-10-20'), (4,'高橋 四郎','2','2022-10-20'), (5,'伊藤 五郎','2','2022-10-18'), (6,'渡辺 六郎','3','2022-10-17'), (7,'山本 七郎','3','2022-10-20');
uid列のみのクエリは、クラスタリングキーにヒットします。SELECT * FROM clustering_test WHERE uid > '3';実行計画 (explain SQL) を確認すると、計画に
Cluster Filterオペレーターが含まれています。これは、クラスタリングキーがヒットし、クエリが高速化されたことを示します。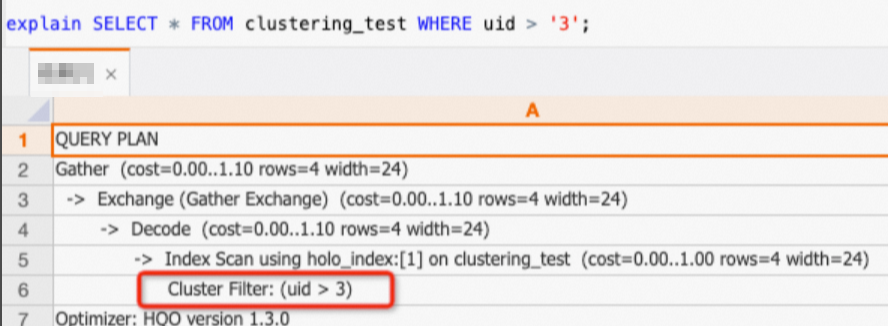
uid,class列のクエリは、クラスタリングキーにヒットします。SELECT * FROM clustering_test WHERE uid = '3' AND class >'1' ;実行計画 (explain SQL) を確認すると、計画に
Cluster Filterオペレーターが含まれています。これは、クラスタリングキーがヒットし、クエリが高速化されたことを示します。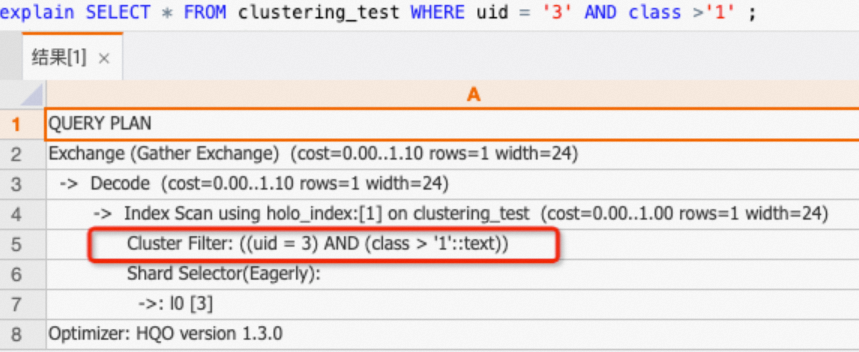
uid,class,date列のクエリは、クラスタリングキーにヒットします。SELECT * FROM clustering_test WHERE uid = '3' AND class ='2' AND date > '2022-10-17';実行計画 (explain SQL) を確認すると、計画に
Cluster Filterオペレーターが含まれています。これは、クラスタリングキーがヒットし、クエリが高速化されたことを示します。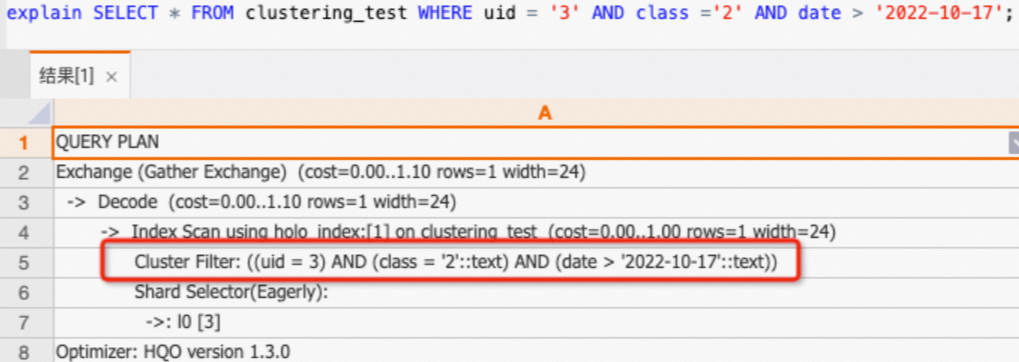
uid,date列のクエリは、左端プレフィックス一致の原則に従っていません。したがって、uidのみがクラスタリングキーにヒットします。date列は通常のフィルターで処理されます。SELECT * FROM clustering_test WHERE uid = '3' AND date > '2022-10-17';実行計画 (explain SQL) を確認すると、uid 列のみに
Cluster Filterオペレーターが含まれていることがわかります。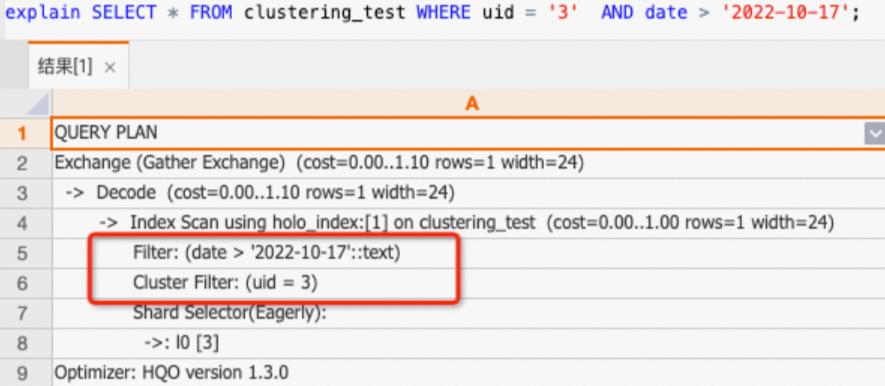
class,date列のみのクエリは、左端プレフィックス一致の原則に従っていないため、クラスタリングキーにヒットしません。SELECT * FROM clustering_test WHERE class ='2' AND date > '2022-10-17';実行計画 (explain SQL) を確認すると、以下に示す計画に
Cluster Filterオペレーターが含まれていないことがわかります。これは、クラスタリングキーがヒットしなかったことを示します。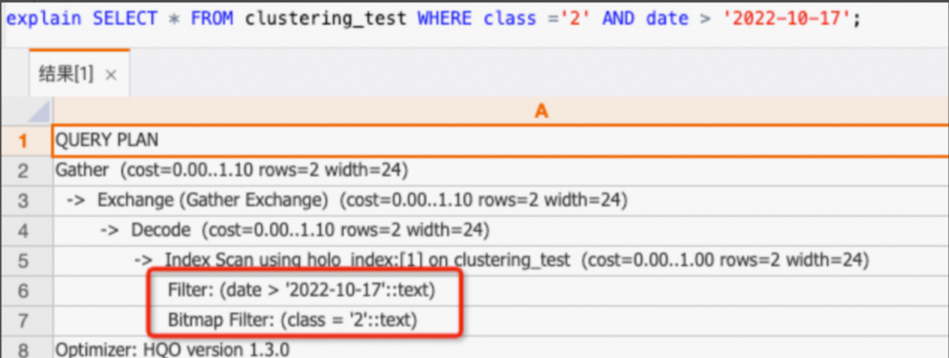
使用例
例 1:クラスタリングキーがヒットするシナリオ。
V2.1 以降でサポートされる構文:
CREATE TABLE table1 ( col1 int NOT NULL, col2 text NOT NULL, col3 text NOT NULL, col4 text NOT NULL ) WITH ( clustering_key = 'col1,col2' ); --上記の SQL 文で作成されたテーブルに対して、次のクエリは高速化できます: -- 高速化可能 select * from table1 where col1='abc'; -- 高速化可能 select * from table1 where col1>'xxx' and col1<'abc'; -- 高速化可能 select * from table1 where col1 in ('abc','def'); -- 高速化可能 select * from table1 where col1='abc' and col2='def'; -- 高速化不可 select col1,col4 from table1 where col2='def';すべてのバージョンでサポートされる構文:
begin; create table table1 ( col1 int not null, col2 text not null, col3 text not null, col4 text not null ); call set_table_property('table1', 'clustering_key', 'col1,col2'); commit; --上記の SQL 文で作成されたテーブルに対して、次のクエリは高速化できます: -- 高速化可能 select * from table1 where col1='abc'; -- 高速化可能 select * from table1 where col1>'xxx' and col1<'abc'; -- 高速化可能 select * from table1 where col1 in ('abc','def'); -- 高速化可能 select * from table1 where col1='abc' and col2='def'; -- 高速化不可 select col1,col4 from table1 where col2='def';
例 2:クラスタリングキーを asc/desc に設定する。
V2.1 以降でサポートされる構文:
CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a:desc,b:asc' );すべてのバージョンでサポートされる構文:
BEGIN; CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ); CALL set_table_property('tbl', 'clustering_key', 'a:desc,b:asc'); COMMIT;
高度なチューニング方法
MySQL や SQL Server などの従来のデータベースのクラスター化インデックスとは異なり、Hologres はテーブル全体ではなく、ファイル内でのみデータをソートします。したがって、クラスタリングキーに対して order by 操作を実行するには、依然としてある程度のオーバーヘッドがあります。
Hologres V1.3 以降には、クラスタリングキーのシナリオでより良いパフォーマンスを提供するための多くのパフォーマンス最適化が含まれています。主な最適化は、次の 2 つのシナリオに対するものです。1.3 より前のバージョンをご利用の場合は、フィードバックを送信できます。詳細については、「一般的なアップグレード準備の失敗」をご参照ください。また、Hologres DingTalk グループに参加してフィードバックを送信することもできます。詳細については、「オンラインサポートをさらに受けるにはどうすればよいですか?」をご参照ください。
クラスタリングキーに対する Order By シナリオ
Hologres では、ファイル内のデータはクラスタリングキーの定義に従ってソートされます。V1.3 より前では、オプティマイザーはこのソート順を使用して最適な実行計画を生成できませんでした。さらに、Shuffle ノードを通過するデータはソートされたままであることが保証されていませんでした (多重マージ)。これにより、計算量が増加し、クエリ時間が長くなることがよくありました。Hologres V1.3 はこのプロセスを最適化します。生成された実行計画がクラスタリングキーのソート順を使用し、Shuffle ノード間でその順序を維持できるようにすることで、クエリのパフォーマンスを向上させます。次の点にご注意ください:
テーブルがクラスタリングキーでフィルターされていない場合、システムはデフォルトで SeqScan を実行し、IndexScan は実行しません。IndexScan のみがクラスタリングキーのソート済みプロパティを使用します。
オプティマイザーは、常にクラスタリングキーのソート順に基づいて実行計画を生成するわけではありません。これは、ソート順を使用することにはある程度のオーバーヘッドがあるためです。データはファイル内でソートされますが、メモリ内で追加のソートが必要になります。
以下に例を示します。
テーブルの DDL は次のとおりです。
V2.1 以降でサポートされる構文:
DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys; CREATE TABLE test_use_sort_info_of_clustering_keys ( a int NOT NULL, b int NOT NULL, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys SELECT i%500, i%100, i::text FROM generate_series(1, 1000) as s(i); ANALYZE test_use_sort_info_of_clustering_keys;すべてのバージョンでサポートされる構文:
DROP TABLE if exists test_use_sort_info_of_clustering_keys; BEGIN; CREATE TABLE test_use_sort_info_of_clustering_keys ( a int NOT NULL, b int NOT NULL, c text ); CALL set_table_property('test_use_sort_info_of_clustering_keys', 'distribution_key', 'a'); CALL set_table_property('test_use_sort_info_of_clustering_keys', 'clustering_key', 'a,b'); COMMIT; INSERT INTO test_use_sort_info_of_clustering_keys SELECT i%500, i%100, i::text FROM generate_series(1, 1000) as s(i); ANALYZE test_use_sort_info_of_clustering_keys;クエリ文。
explain select * from test_use_sort_info_of_clustering_keys where a > 100 order by a, b;実行計画の比較
V1.3 より前のバージョン (V1.1) の実行計画は次のとおりです。
explainSQL 文を実行できます。Sort (cost=0.00..0.00 rows=797 width=11) -> Gather (cost=0.00..2.48 rows=797 width=11) Sort Key: a, b -> Sort (cost=0.00..2.44 rows=797 width=11) Sort Key: a, b -> Exchange (Gather Exchange) (cost=0.00..1.11 rows=797 width=11) -> Decode (cost=0.00..1.11 rows=797 width=11) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys (cost=0.00..1.00 rows=797 width=11) Cluster Filter: (a > 100)V1.3 の実行計画は次のとおりです。
Gather (cost=0.00..1.15 rows=797 width=11) Merge Key: a, b -> Exchange (Gather Exchange) (cost=0.00..1.11 rows=797 width=11) Merge Key: a, b -> Decode (cost=0.00..1.11 rows=797 width=11) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys (cost=0.00..1.01 rows=797 width=11) Order by: a, b Cluster Filter: (a > 100)
以前のバージョンの計画と比較して、V1.3 の実行計画は、テーブルのクラスタリングキーのソート順を使用して、直接マージ出力を実行します。これにより、実行全体をパイプライン化でき、大量のデータを扱う際の遅いソートを防ぐことができます。実行計画の比較から、V1.3 は Hashagg よりも複雑さが低く、パフォーマンスが優れた Groupagg を生成することがわかります。
クラスタリングキーでの結合シナリオ (ベータ版)
Hologres V1.3 では SortMergeJoin 結合タイプが導入されました。この結合タイプは、実行計画がクラスタリングキーのソート順を使用して計算量を削減し、パフォーマンスを向上させることを保証します。次の点にご注意ください:
この機能はベータ版であり、デフォルトでは無効になっています。有効にするには、クエリの前に次のパラメーターを追加します。
-- マージ結合を有効にする set hg_experimental_enable_sort_merge_join=on;テーブルがクラスタリングキーでフィルターされていない場合、システムはデフォルトで SeqScan を実行し、IndexScan は実行しません。IndexScan のみがクラスタリングキーのソート済みプロパティを使用します。
オプティマイザーは、常にクラスタリングキーのソート順に基づいて実行計画を生成するわけではありません。これは、ソート順を使用することにはある程度のオーバーヘッドがあるためです。データはファイル内でソートされますが、メモリ内で追加のソートが必要になります。
以下に例を示します。
テーブルの DDL は次のとおりです。
V2.1 以降でサポートされる構文:
DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys1; CREATE TABLE test_use_sort_info_of_clustering_keys1 ( a int, b int, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys1 SELECT i % 500, i % 100, i::text FROM generate_series(1, 10000) AS s(i); ANALYZE test_use_sort_info_of_clustering_keys1; DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys2; CREATE TABLE test_use_sort_info_of_clustering_keys2 ( a int, b int, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys2 SELECT i % 600, i % 200, i::text FROM generate_series(1, 10000) AS s(i); ANALYZE test_use_sort_info_of_clustering_keys2;すべてのバージョンでサポートされる構文:
drop table if exists test_use_sort_info_of_clustering_keys1; begin; create table test_use_sort_info_of_clustering_keys1 ( a int, b int, c text ); call set_table_property('test_use_sort_info_of_clustering_keys1', 'distribution_key', 'a'); call set_table_property('test_use_sort_info_of_clustering_keys1', 'clustering_key', 'a,b'); commit; insert into test_use_sort_info_of_clustering_keys1 select i%500, i%100, i::text from generate_series(1, 10000) as s(i); analyze test_use_sort_info_of_clustering_keys1; drop table if exists test_use_sort_info_of_clustering_keys2; begin; create table test_use_sort_info_of_clustering_keys2 ( a int, b int, c text ); call set_table_property('test_use_sort_info_of_clustering_keys2', 'distribution_key', 'a'); call set_table_property('test_use_sort_info_of_clustering_keys2', 'clustering_key', 'a,b'); commit; insert into test_use_sort_info_of_clustering_keys2 select i%600, i%200, i::text from generate_series(1, 10000) as s(i); analyze test_use_sort_info_of_clustering_keys2;クエリ文は次のとおりです。
explain select * from test_use_sort_info_of_clustering_keys1 a join test_use_sort_info_of_clustering_keys2 b on a.a = b.a and a.b=b.b where a.a > 100 and b.a < 300;実行計画の比較
V1.3 より前のバージョン (V1.1) の実行計画は次のとおりです。
Gather (cost=0.00..3.09 rows=4762 width=24) -> Hash Join (cost=0.00..2.67 rows=4762 width=24) Hash Cond: ((test_use_sort_info_of_clustering_keys1.a = test_use_sort_info_of_clustering_keys2.a) AND (test_use_sort_info_of_clustering_keys1.b = test_use_sort_info_of_clustering_keys2.b)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3993 width=12) -> Decode (cost=0.00..1.14 rows=3993 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys1 (cost=0.00..1.01 rows=3993 width=12) Cluster Filter: ((a > 100) AND (a < 300)) -> Hash (cost=1.13..1.13 rows=3386 width=12) -> Exchange (Gather Exchange) (cost=0.00..1.13 rows=3386 width=12) -> Decode (cost=0.00..1.13 rows=3386 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys2 (cost=0.00..1.01 rows=3386 width=12) Cluster Filter: ((a > 100) AND (a < 300))V1.3 の実行計画は次のとおりです。
Gather (cost=0.00..2.88 rows=4762 width=24) -> Merge Join (cost=0.00..2.46 rows=4762 width=24) Merge Cond: ((test_use_sort_info_of_clustering_keys2.a = test_use_sort_info_of_clustering_keys1.a) AND (test_use_sort_info_of_clustering_keys2.b = test_use_sort_info_of_clustering_keys1.b)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3386 width=12) Merge Key: test_use_sort_info_of_clustering_keys2.a, test_use_sort_info_of_clustering_keys2.b -> Decode (cost=0.00..1.14 rows=3386 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys2 (cost=0.00..1.01 rows=3386 width=12) Order by: test_use_sort_info_of_clustering_keys2.a, test_use_sort_info_of_clustering_keys2.b Cluster Filter: ((a > 100) AND (a < 300)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3993 width=12) Merge Key: test_use_sort_info_of_clustering_keys1.a, test_use_sort_info_of_clustering_keys1.b -> Decode (cost=0.00..1.14 rows=3993 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys1 (cost=0.00..1.01 rows=3993 width=12) Order by: test_use_sort_info_of_clustering_keys1.a, test_use_sort_info_of_clustering_keys1.b Cluster Filter: ((a > 100) AND (a < 300))
以前のバージョンの計画と比較して、V1.3 の実行計画はクラスタリングキーのソート順を使用します。各シャード内でマージソートを実行し、その後直接 SortMergeJoin を実行します。これにより、実行全体をパイプライン化できます。また、ハッシュ側が大きすぎてメモリに収まらない場合に HashJoin で発生する可能性のある OOM (メモリ不足) の問題を回避できます。
参考
Hologres 内部テーブルのデータ定義言語 (DDL) 文の詳細については、次のトピックをご参照ください: