1,000 を超えるタグが使用されるシナリオでは、タグ計算にワイドテーブルを使用するソリューションは適していません。これは、列数が増加すると更新効率が低下するためです。このトピックでは、このようなシナリオでタグ計算とプロファイル分析を実行する方法について説明します。
背景情報
Hologres は PostgreSQL エコシステムと互換性があり、Roaring ビットマップ関数 をサポートしています。タグテーブルのインデックスが作成されます。ユーザー ID はエンコードされ、ビットマップとして格納されます。リレーショナル操作は、ビットマップの積集合、和集合、差集合操作に変換され、リアルタイム計算のパフォーマンスが向上します。大量のユーザープロパティの分析が必要なシナリオでは、Roaring ビットマップを使用して、サブ秒以内にクエリに応答できます。
シナリオ
Roaring ビットマップは、次のシナリオに適しています。
大量のタグが使用されるシナリオ: このようなシナリオでは、多くの大きなテーブルに対して JOIN 操作が必要です。
BITMAP_AND関数を使用して JOIN 操作を置き換えることで、メモリ消費量を削減できます。ビットマッププラグインリポジトリは、単一命令複数データ(SIMD)ベースの最適化により、CPU 使用率を 1 ~ 2% 向上させることができます。大量のデータが含まれ、重複排除が必要なシナリオ: ビットマップは固有の重複排除機能を提供し、ユニークベクトル(UV)計算とメモリのオーバーヘッドを防ぎます。
タグの種類
プロファイリングシステムのタグは、次の種類に分類できます。タグの種類によって、計算モードが異なります。特定の種類のタグは、ビットマップに変換して格納する必要があります。
プロパティタグ: プロパティタグは、性別、都道府県、婚姻状況などのユーザープロパティを表します。プロパティタグは安定しており、正確なフィルター条件に基づいてフィルターできます。これらのタグの場合、ビットマップの圧縮率が高く、ビットマップは関連操作に適しています。
アクションタグ: アクションタグは、ユーザーのアクション特性を表し、特定の時点でのユーザーの行動を表します。ユーザーアクションには、ページビュー、購入、アクティブなログオンなどがあります。アクションデータは頻繁に更新され、範囲スキャンと集計フィルタリングが必要です。アクションタグの場合、ビットマップの圧縮率が低く、ビットマップは関連操作に適していません。
プロパティタグ
プロパティタグは、ユーザープロパティを表します。プロパティタグは安定しており、正確なフィルター条件に基づいてフィルターできます。ビットマップを使用して、効率的な圧縮と操作を行うことができます。
ソリューション
データ管理プラットフォーム(DMP)に、次の図に示すように、2 つのプロパティタグテーブルが含まれているとします。
 dws_userbase テーブルは基本的なユーザープロパティを表し、dws_usercate_prefer テーブルはユーザーの好みを表します。
dws_userbase テーブルは基本的なユーザープロパティを表し、dws_usercate_prefer テーブルはユーザーの好みを表します。[province = Beijing] & [cate_prefer = Fashion]フィルター条件を満たすユーザー数を取得する場合、関連付け、フィルタリング、重複排除操作を実行できます。ただし、大量のデータが含まれるシナリオでは、関連付け操作と重複排除操作によってパフォーマンスに大きな負担がかかる可能性があります。ビットマップベースの最適化ソリューションでは、事前に作成されたタグを含むビットマップテーブルを使用して、アドホック操作のコストを削減します。この例では、上記のテーブルのデータが列ごとに分割され、次の図に示す 2 つのビットマップテーブルが作成されます。次に、ビット単位の AND 演算を実行して、上記のフィルター条件を満たすユーザーを取得します。
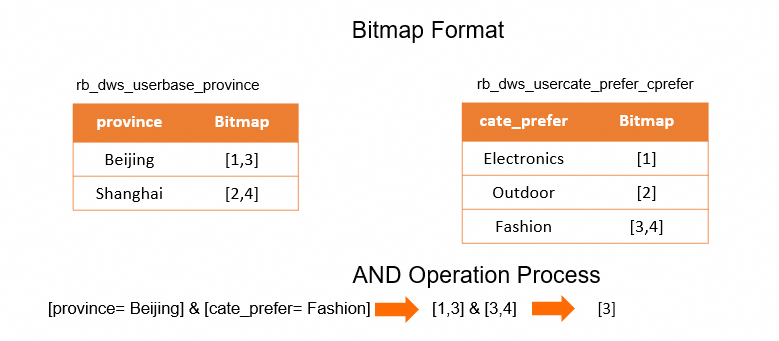 rb_dws_userbase_province テーブルは、province 列と uid 列の間のビットマップ関係を表し、rb_dws_usercate_prefer_cprefer テーブルは、cate_prefer 列と uid 列の間のビットマップ関係を表します。
rb_dws_userbase_province テーブルは、province 列と uid 列の間のビットマップ関係を表し、rb_dws_usercate_prefer_cprefer テーブルは、cate_prefer 列と uid 列の間のビットマップ関係を表します。ただし、上記のソリューションには問題があります。列に階層関係がある場合、このような分割と操作によって、次の図に示すように、計算エラーが発生する可能性があります。
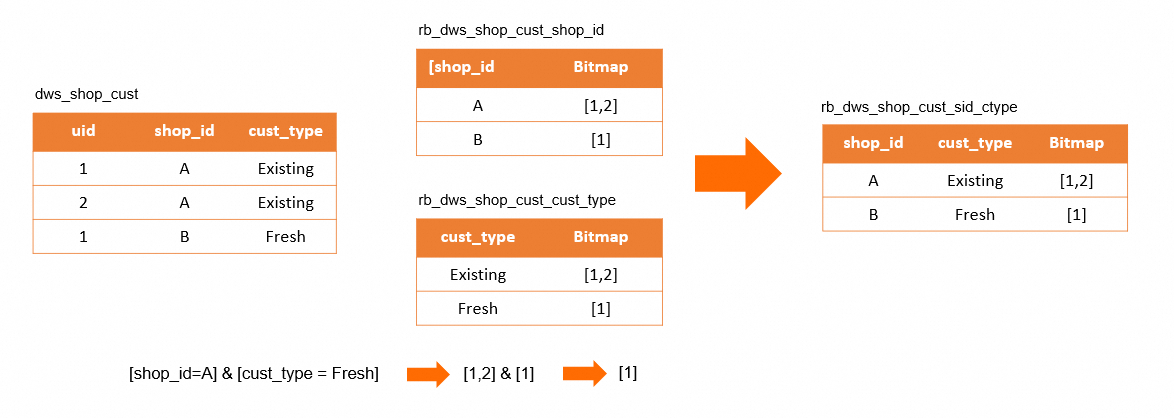 新規顧客、既存顧客、潜在顧客に関する情報を表す dws_shop_cust テーブルのデータは、列ごとに分割されます。店舗 ID を表す rb_dws_shop_cust_shop_id ビットマップテーブルと、顧客タイプを表す
新規顧客、既存顧客、潜在顧客に関する情報を表す dws_shop_cust テーブルのデータは、列ごとに分割されます。店舗 ID を表す rb_dws_shop_cust_shop_id ビットマップテーブルと、顧客タイプを表す rb_dws_shop_cust_cust_typeビットマップテーブルが作成されます。[shop_id = A] & [cust_type = Fresh]フィルター条件を満たす顧客をフィルターすると、uid[1]の結果が得られます。ただし、cust_type 列の値が Fresh に対応する uid 列の値 1 は存在しません。これは、cust_type 列と shop_id 列が相関しているためです。データウェアハウスモデルでは、cust_type は shop_id の指標であり、単独で使用することはできません。shop_id を cust_type と組み合わせて使用して rb_dws_shop_cust_sid_ctype ビットマップテーブルを作成し、このようなエラーを防ぐ必要があります。uid 値をビットマップに圧縮してから、ビット単位の AND、OR、NOT 演算を実行してタグを計算する必要があります。
手順
ユーザー情報のエンコード
ユーザー ID は文字列の場合があります。ただし、ビットマップには整数のみが含まれます。したがって、SERIAL データ型または BIGSERIAL データ型を使用して自動インクリメントフィールドを含むテーブルを作成してから、文字列型の uid 値を整数にエンコードする必要があります。詳細については、「PostgreSQL SERIAL」をご参照ください。
--辞書テーブルを作成します。 CREATE TABLE dws_uid_dict ( encode_uid bigserial, uid text primary key ); --タグテーブルから uid 値を挿入します。 INSERT INTO dws_uid_dict(uid) SELECT uid FROM dws_userbase ON conflict DO NOTHING;エンコードされたユーザー ID は連続性を維持し、ビットマップとして簡単に格納できます。次の図は、bitmap2 にスパースデータが含まれており、bitmap1 よりもストレージ効率がはるかに低い例を示しています。したがって、ユーザー ID がエンコードされている場合、ストレージコストを削減し、計算効率を向上させることができます。
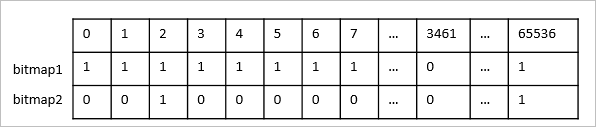
スパース数値データはエンコードできますが、パフォーマンスのオーバーヘッドが発生する可能性があります。たとえば、広告 DMP は高性能のプロファイリングだけでなく、ユーザー詳細のリアルタイム出力を必要とします。ユーザー詳細のリアルタイム出力が必要な場合、エンコードされたユーザー ID を復元するためにユーザー ID テーブルを結合する必要があり、これによりパフォーマンスのオーバーヘッドが発生します。特定のシナリオに基づいて、ユーザー ID をエンコードするかどうかを決定する必要があります。ケースごとに異なる推奨事項があります。
文字列型のユーザー ID の場合は、エンコードすることをお勧めします。
エンコードされたユーザー ID の復元を頻繁に必要とする整数型のユーザー ID の場合は、エンコードしないことをお勧めします。
エンコードされたユーザー ID の復元を頻繁に必要としない整数型のユーザー ID の場合は、エンコードすることをお勧めします。
ビットマップの処理とクエリ
dws_userbase テーブルと dws_shop_cust テーブルを、都道府県と性別列を含む 1 つのビットマップテーブルに分割します。性別列の値には、男性と女性のみが含まれます。圧縮されたビットマップは、クラスター内の 2 つのノードにのみ分散できます。その結果、コンピューティングリソースとストレージリソースが均等に分散されず、クラスタリソースが十分に活用されません。この場合、ビットマップを複数のセグメントに分割し、同時実行のためにクラスターに分散する必要があります。たとえば、次の SQL ステートメントを実行して、ビットマップを 65,536 個のセグメントに分割できます。
-- dws_userbase という名前のワイドテーブルを作成します。 BEGIN; CREATE TABLE dws_shop_cust ( uid text not null primary key, shop_id text, cust_type text ); call set_table_property('dws_shop_cust', 'distribution_key', 'uid'); END; -- ビットマップ拡張機能を作成します。 CREATE EXTENSION roaringbitmap; BEGIN; CREATE TABLE rb_dws_userbase_province ( province text, bucket int, bitmap roaringbitmap ); call set_table_property('rb_dws_userbase_province', 'distribution_key', 'bucket'); END; BEGIN; CREATE TABLE rb_dws_shop_cust_sid_ctype ( shop_id text, cust_type text, bucket int, bitmap roaringbitmap ); call set_table_property('rb_dws_shop_cust_sid_ctype', 'distribution_key', 'bucket'); END; -- データをビットマップテーブルに書き込みます。 INSERT INTO rb_dws_userbase_province SELECT province, encode_uid / 65536 as "bucket", rb_build_agg(b.encode_uid) AS bitmap FROM dws_userbase a join dws_uid_dict b on a.uid = b.uid GROUP BY province, "bucket"; INSERT INTO rb_dws_shop_cust_sid_ctype SELECT shop_id, cust_type, encode_uid / 65536 AS "bucket", rb_build_agg(b.encode_uid) AS bitmap FROM dws_shop_cust a JOIN dws_uid_dict b ON a.uid = b.uid GROUP BY shop_id, cust_type, "bucket";[shop_id = A] & [cust_type = Fresh] & [province = Beijing]フィルター条件を満たすユーザーを取得する場合、ビットマップに対して関連する AND、OR、および NOT 演算を実行できます。次の SQL ステートメントを実行できます。SELECT SUM(RB_CARDINALITY(rb_and(ub.bitmap, uc.bitmap))) FROM (SELECT rb_or_agg(bitmap) AS bitmap, bucket FROM rb_dws_userbase_province WHERE province = 'Beijing' GROUP BY bucket) ub JOIN (SELECT rb_or_agg(bitmap) AS bitmap, bucket FROM rb_dws_shop_cust_sid_ctype WHERE shop_id = 'A' AND cust_type = 'Fresh' GROUP BY bucket) uc ON ub.bucket = uc.bucket;
アクションタグ
通常、ファクトテーブルは時間別に編成されます。たとえば、ユーザーアクションテーブルは日別に編成されます。特定の日のユーザーデータには、限られたエントリのみが含まれます。このようなデータをビットマップに圧縮すると、行指向ストレージのオーバーヘッドによってストレージスペースが浪費される可能性があります。さらに、ファクトテーブルの一般的な計算モードでは、フィルタリングのために複数日のデータを集計する必要があります。ビットマップを使用する場合は、操作のために集計する前に展開する必要があります。このようなデータは頻繁に変更され、リアルタイムの更新が必要です。[option->bitmap] ストレージ構造では、更新が必要なデータを識別できません。したがって、ビットマップは、アクションデータ、集計、またはリアルタイム更新には適していません。
アクションタグが関係するシナリオでは、Hologres は元のストレージ形式を使用できます。ファクトテーブルとプロパティテーブルを結合する必要がある場合は、ファクトテーブルのフィルター結果に対してビットマップを生成し、プロパティテーブルのビットマップインデックスと結合できます。ビットマップインデックステーブルはバケットを分散キーとして使用するため、ローカル結合操作によって結合パフォーマンスを向上させることができます。
次の SQL ステートメントを実行して、[province=Beijing] & [shop_id=A AND No purchase for 7 days] フィルター条件を満たすユーザーを取得できます。
-- アクションテーブルを作成します。
BEGIN;
CREATE TABLE dws_usershop_behavior
(
uid int not null,
shop_id text not null,
pv_cnt int,
trd_cnt int,
ds integer not null
);
call set_table_property('dws_usershop_behavior', 'distribution_key', 'uid');
COMMIT;
-- アクションテーブルをエンコードします。
BEGIN;
CREATE TABLE dws_usershop_behavior_bucket
(
encode_uid int not null,
shop_id text not null,
pv_cnt int,
trd_cnt int,
ds int not null,
bucket int
);
CALL set_table_property('dws_usershop_behavior_bucket', 'orientation', 'column');
call set_table_property('dws_usershop_behavior_bucket', 'distribution_key', 'bucket');
CALL set_table_property('dws_usershop_behavior_bucket', 'clustering_key', 'shop_id,encode_uid');
COMMIT;
-- ファクトデータを書き込みます。
INSERT INTO dws_usershop_behavior_bucket
SELECT *,
encode_uid,
shop_id,
pv_cnt,
trd_cnt,
encode_uid / 65536
FROM dws_usershop_behavior a JOIN dws_uid_dictionary b
on a.uid = b.uid;
-- ファクトデータとプロパティデータを結合します。
SELECT sum(rb_cardinality(bitmap)) AS cnt
FROM
(SELECT rb_and(ub.bitmap, us.bitmap) AS bitmap,
ub.bucket
FROM
(SELECT rb_or_agg(bitmap) AS bitmap,
bucket
FROM rb_dws_userbase_province
WHERE province = 'Beijing'
GROUP BY bucket) AS ub
JOIN
(SELECT rb_build_agg(uid) AS bitmap,
bucket
FROM
(SELECT uid,
bucket
FROM dws_usershop_behavior_bucket
WHERE shop_id = 'A' AND ds > to_char(current_date-7, 'YYYYMMdd')::int
GROUP BY uid,
bucket HAVING sum(trd_cnt) = 0) tmp
GROUP BY bucket) us ON ub.bucket = us.bucket) rビットマップのオフライン処理
ビットマップデータの計算がビジネスに影響を与えるのを防ぐために、ビットマップデータをオフラインで処理することを選択できます。MaxComputeまたはHiveの外部テーブルからデータを読み込むことができます。ビットマップは、オンラインとオフラインの両方で同様の方法で処理されます。データは、エンコードと集計によって生成できます。次のコードは、MaxComputeでオフラインでビットマップデータを作成する方法の例を示しています。
-- プロジェクトを選択します。
USE bitmap_demo;
-- ソース テーブルを作成します。
CREATE TABLE mc_dws_uid_dict (
encode_uid bigint,
bucket bigint,
uid string
);
CREATE TABLE mc_dws_userbase
(
uid string,
province string,
gender string,
marriaged string
);
-- uid 値をエンコードします。
-- 新しい uid 値を計算します。
WITH uids_to_encode AS
(SELECT DISTINCT(ub.uid),
CAST(ub.uid / 65336 AS BIGINT) AS bucket
FROM mc_dws_userbase ub
LEFT JOIN mc_dws_uid_dict d ON ub.uid = d.uid
WHERE d.uid IS NULL),
-- 各バケットでエンコードされる uid の数を計算します。SUM 関数を使用して、バケット オフセットを取得します。
uids_bucket_encode_offset AS
(SELECT bucket,
sum(cnt) over (ORDER BY bucket ASC) - cnt AS bucket_offset
FROM
(SELECT count(1) AS cnt,
bucket
FROM uids_to_encode
GROUP BY bucket) x),
-- エンコードされた uid の最大数を計算します。
dict_used_id_offset AS
(SELECT max(encode_uid) AS used_id_offset FROM mc_dws_uid_dict)
-- 新しい uid = エンコードされた uid の最大数 + バケット オフセット + 行番号
INSERT INTO mc_dws_uid_dict
SELECT
COALESCE((SELECT used_id_offset FROM dict_used_id_offset),0) + bucket_offset + rn,
bucket,
uid
FROM
(SELECT row_number() OVER (partition BY ub.bucket ORDER BY ub.uid) AS rn,
ub.bucket,
bo.bucket_offset,
uid
FROM uids_to_encode ub
JOIN uids_bucket_encode_offset bo ON ub.bucket = bo.bucket) j
-- ビットマップ関連の関数を作成します。
add jar function_jar_dir/mc-bitmap-functions.jar as mc_bitmap_func.jar -f;
create function mc_rb_cardinality as com.alibaba.hologres.RbCardinalityUDF using mc_bitmap_func.jar;
create function mc_rb_build_agg as com.alibaba.hologres.RbBuildAggUDAF using mc_bitmap_func.jar;
-- ビットマップ テーブルを作成し、テーブルにデータを書き込みます。
CREATE TABLE mc_rb_dws_userbase_province
(
province string,
bucket int,
bitmap string
);
INSERT INTO mc_rb_dws_userbase_province
SELECT province,
b.bucket_num,
mc_rb_build_agg(b.encode_uid) AS bitmap
FROM mc_dws_userbase a join mc_dws_uid_dict b on a.uid = b.uid
GROUP BY province, b.bucket_num;Hologresで次のステートメントを実行します。
-- MaxComputeテーブルを作成します。
CREATE TABLE mc_rb_dws_userbase_province (
province text,
bucket int,
bitmap text
) server odps_server options(project_name 'bitmap_demo', table_name 'mc_rb_dws_userbase_province');
-- MaxComputeテーブルからHologresにビットマップデータを書き込みます。
INSERT INTO rb_dws_userbase_province
SELECT province,
bucket::INT,
roaringbitmap_text(bitmap, FALSE)
FROM mc_rb_dws_userbase_province;上記の手順を実行した後、データはHologresにロードされます。その後、ビット演算を実行してクエリを高速化できます。
ビットマップのリアルタイム処理
リアルタイムコンピューティングのシナリオでは、Hologres を Flink と組み合わせて使用することで、Roaring ビットマップに基づいてユーザタグのリアルタイム重複排除を実行できます。次の手順を実行します。
ユーザー ID ディクショナリテーブルをディメンションテーブルとして使用し、Hologres の INSERT ON CONFLICT ステートメントを使用してユーザー ID を追加します。次に、Flink でディメンションテーブルとアクションテーブルを結合します。
結果のテーブルをタグごとに Roaring ビットマップで集計します。
結果のビットマップを Hologres のビットマップテーブルに書き込みます。