このクイックスタートでは、Solr を利用した統合検索インスタンスを使用して、HBase データで全文検索を有効にするための完全なワークフローを説明します。このクイックスタートを完了すると、以下のことができるようになります:
HBase テーブルとフルテキストインデックスの作成
HBase と検索コレクション間のカラムマッピングの定義
HBase へのレコードの書き込みと、検索サービスを介したクエリの実行
行キーを使用した HBase からの元のレコードの取得
前提条件
開始する前に、以下が準備できていることを確認してください:
HBase 拡張版の Shell アクセスページからダウンロードし、使用手順に従って設定した最新バージョンの HBase Shell
ご利用の HBase クラスターに設定されたホワイトリスト
Web コンソールにアクセス可能な実行中の検索インスタンス
ステップ 1:HBase クラスターにテーブルを作成する
HBase Shell で次のコマンドを実行して、カラムファミリー f を持つ testTable という名前のテーブルを作成します:
hbase(main):002:0> create 'testTable', {NAME => 'f'}ステップ 2:検索インスタンスにインデックスを作成する
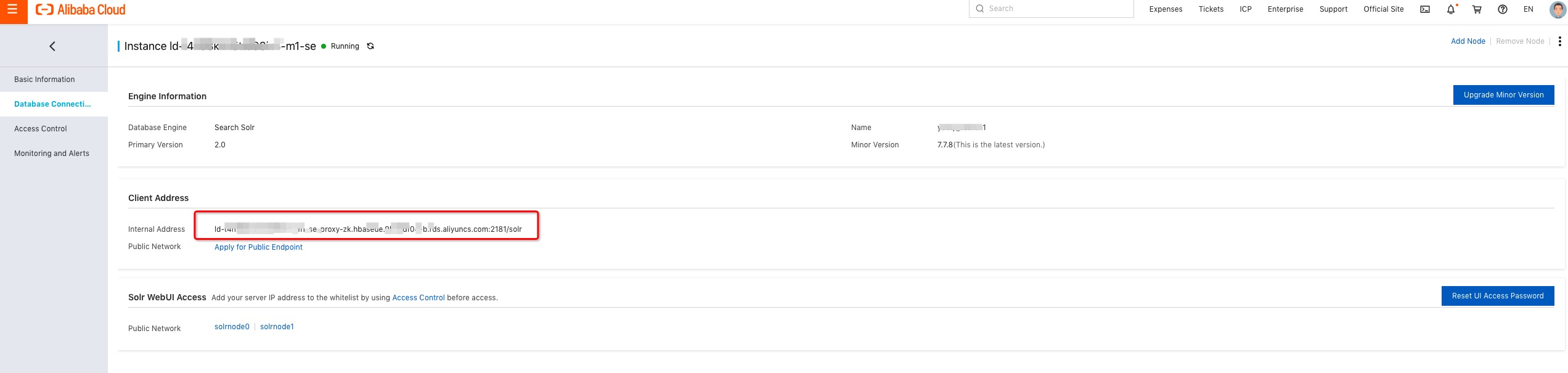
検索インスタンスの詳細ページで、[データベース接続] をクリックします。
[Web UI へのアクセス] セクションで、Web コンソールを開きます。
Web コンソールにアクセスする前に、ホワイトリストを設定し、パスワードを設定してください。
他のすべてのパラメーターはデフォルト値のまま、以下の設定でコレクションを作成します:
パラメーター 値 config set_indexer_defaultnumShardsクラスター内のノード数 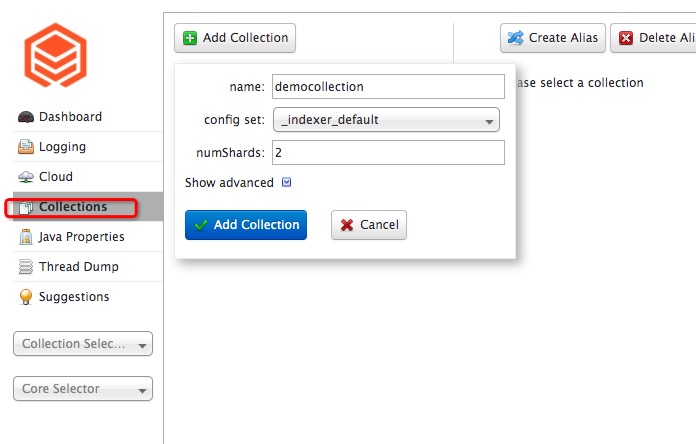
ステップ 3:マッピングの作成
マッピングは、どの HBase カラムを Solr フィールドに同期するかを定義します。この例では、testTable の f:name カラムが democollection コレクションの name_s フィールドにマッピングされます。ここで、f はカラムファミリー、name はカラム修飾子です。
schema.json という名前のファイルに、以下の内容を記述して作成します:
{
"sourceNamespace": "default",
"sourceTable": "testTable",
"targetIndexName": "democollection",
"indexType": "SOLR",
"rowkeyFormatterType": "STRING",
"fields": [
{
"source": "f:name",
"targetField": "name_s",
"type": "STRING"
}
]
}スキーマの主要なフィールド:
| フィールド | 説明 |
|---|---|
sourceNamespace | HBase の名前空間。デフォルトの名前空間には "default" を使用します。 |
sourceTable | HBase のソーステーブル名。 |
targetIndexName | Solr コレクション名。 |
indexType | インデックスのタイプ。"SOLR" に設定します。 |
rowkeyFormatterType | 行キーのフォーマット。文字列の行キーには "STRING" を設定します。 |
fields[].source | <カラムファミリー>:<カラム修飾子> フォーマットの HBase カラム。 |
fields[].targetField | ターゲットの Solr フィールド名。 |
fields[].type | フィールドのデータ型。 |
サポートされているパラメーターの完全なリストについては、「HBase のフルテキストインデックスの管理」をご参照ください。
以下を実行してマッピングを適用します:
hbase(main):006:0> alter_external_index 'testTable', 'schema.json'コマンドが実行されると、ソースカラムと送信先カラム間のマッピングが作成されます。
ステップ 4:HBase にデータを書き込む
testTable にサンプルレコードを書き込みます:
hbase(main):008:0> put 'testTable', 'row1', 'f:name', 'foo'
Took 0.1697 secondsステップ 5:検索インスタンスでデータをクエリする
検索サービスの Web コンソールを開きます。
democollectionインデックスを選択します。[クエリ] をクリックしてデータを検索します。
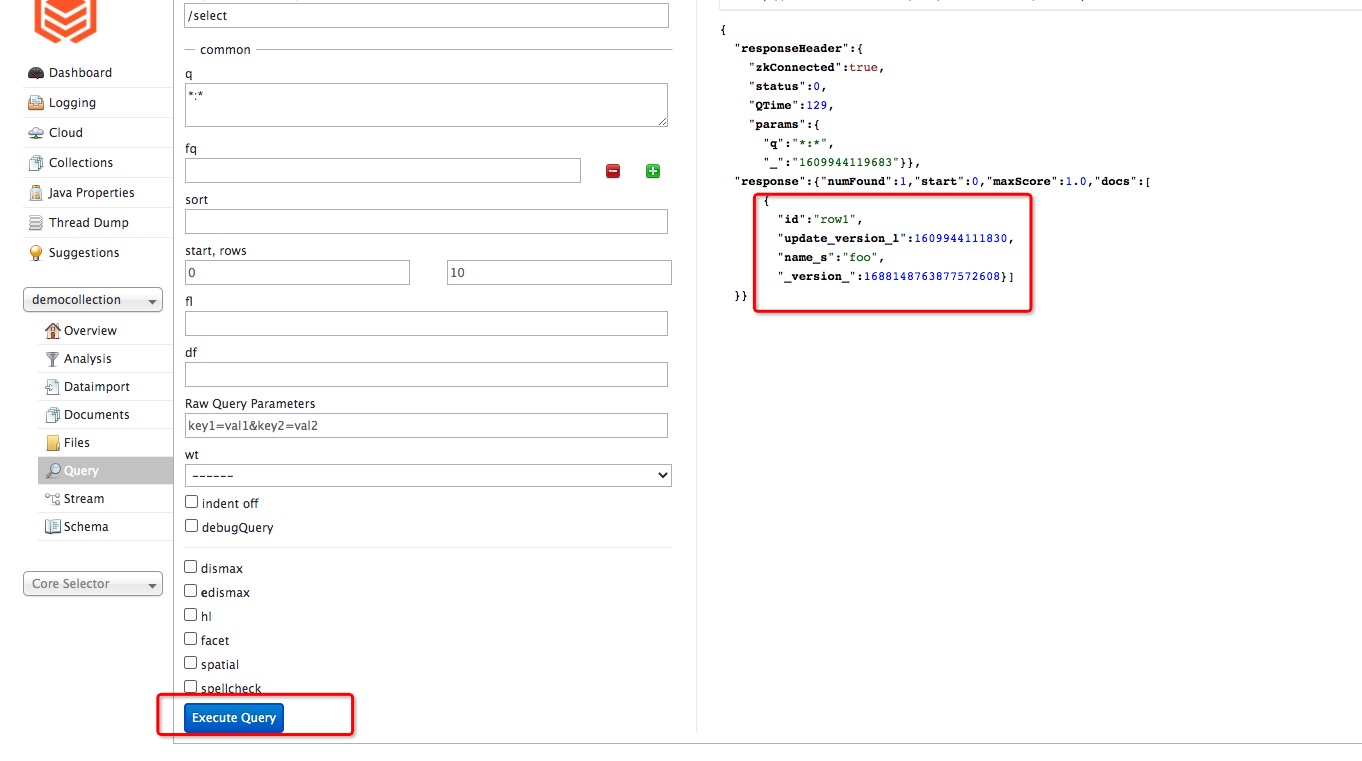
ステップ 4 で書き込んだレコードが結果に表示されます。各結果には ID フィールドが含まれており、これは HBase の対応する行の行キーです。
ステップ 6:元の HBase レコードを検索する
検索サービスは、マッピングファイルで定義されたカラムのみを同期し、HBase の行全体は同期しません。完全なレコードを取得するには、検索結果の ID 値を行キーとして使用し、HBase に直接クエリを実行します。
次のステップ
高度なマッピングオプションについては、「HBase のフルテキストインデックスの管理」をご参照ください。