2024年2月21日、Google は初のオープンモデルファミリーである Gemma を正式にリリースしました。2B と 7B のバージョンが利用可能です。Function Compute の GPU インスタンスとアイドルモードを利用することで、Gemma モデルサービスを迅速かつ低コストでデプロイできます。
前提条件
Function Compute が有効化されていること。詳細については、「クイックスタート」をご参照ください。
名前空間とイメージリポジトリが作成されていること。詳細については、「名前空間の作成」および「イメージリポジトリの作成」をご参照ください。
操作手順
Gemma モデルサービスをデプロイする際には、GPU リソース、vCPU リソース、メモリリソース、ディスク使用量、アウトバウンドインターネットトラフィック、関数呼び出しなど、使用したリソースに対して課金されます。詳細については、「課金概要」をご参照ください。
アプリケーションの作成
次の手順に従って、Container Registry (ACR) リポジトリのドメイン名とリポジトリアドレスを取得します。
Container Registry コンソールにログインし、関数が配置されているリージョンを選択してから、ターゲットの Enterprise Edition インスタンスのカードで [管理] をクリックします。
左側のナビゲーションウィンドウで、[アクセス制御] をクリックし、インターネット タブを選択します。アクセスエントリのスイッチがオフになっている場合は、オンにします。インターネット上の任意のマシンがリポジトリにログインできるようにするには、すべてのパブリック IP 許可リストを削除します。そうでない場合は、必要に応じてパブリック IP 許可リストを構成します。設定が完了したら、ACR インスタンスの [ドメイン名] を保存します。

左側のナビゲーションウィンドウで、Container Registry リポジトリ をクリックし、目的のリポジトリの[リポジトリ名]をクリックしてリポジトリ詳細ページに移動します。
リポジトリのパブリックエンドポイントを保存します。

Gemma モデルの重みをダウンロードします。モデルは Hugging Face または ModelScope からダウンロードできます。このトピックでは、ModelScope の Gemma-2b-it モデルを例として使用します。詳細については、「Gemma-2b-it」をご参照ください。
重要Git を使用してモデルをダウンロードする場合、まず Git Large File Storage (LFS) 拡張をインストールし、
git lfs installを実行して Git LFS を初期化してから、git cloneを実行してモデルをダウンロードする必要があります。そうしないと、サイズが大きいため、ダウンロードしたモデルが不完全になり、Gemma サービスが正常に動作しなくなる可能性があります。Dockerfile と
app.pyという名前のモデルサービスコードファイルを作成します。Dockerfile
FROM registry.cn-shanghai.aliyuncs.com/modelscope-repo/modelscope:fc-deploy-common-v17 WORKDIR /usr/src/app COPY . . RUN pip install -U transformers RUN pip install -U accelerate CMD [ "python3", "-u", "/usr/src/app/app.py" ] EXPOSE 9000app.py
from flask import Flask, request from transformers import AutoTokenizer, AutoModelForCausalLM model_dir = '/usr/src/app/gemma-2b-it' app = Flask(__name__) tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto") @app.route('/invoke', methods=['POST']) def invoke(): request_id = request.headers.get("x-fc-request-id", "") print("FC Invoke Start RequestId: " + request_id) text = request.get_data().decode("utf-8") print(text) input_ids = tokenizer(text, return_tensors="pt").to("cuda") outputs = model.generate(**input_ids, max_new_tokens=1000) response = tokenizer.decode(outputs[0]) print("FC Invoke End RequestId: " + request_id) return str(response) + "\n" if __name__ == '__main__': app.run(debug=False, host='0.0.0.0', port=9000)Function Compute がサポートするすべての HTTP ヘッダーの詳細については、「共通リクエストヘッダー」をご参照ください。
このステップを完了すると、コードディレクトリは次の構造になります。
. |-- app.py |-- Dockerfile `-- gemma-2b-it |-- config.json |-- generation_config.json |-- model-00001-of-00002.safetensors |-- model-00002-of-00002.safetensors |-- model.safetensors.index.json |-- README.md |-- special_tokens_map.json |-- tokenizer_config.json |-- tokenizer.json `-- tokenizer.model 1 directory, 12 files次のコマンドを実行して、コンテナイメージをビルドおよびプッシュします。
{REPO_ENDPOINT}をステップ 1 で取得したターゲットイメージリポジトリのパブリックエンドポイントに、{REGISTRY}を ACR インスタンスの[ドメイン名]に置き換えます。IMAGE_NAME={REPO_ENDPOINT}:gemma-2b-it docker login --username=mu****@test.aliyunid.com {REGISTRY} docker build -f Dockerfile -t $IMAGE_NAME . docker push $IMAGE_NAME重要Apple シリコン搭載の Mac でイメージをビルドする場合、Function Compute 互換のイメージをビルドするには、3 行目の
docker buildコマンドを次のコマンドに置き換えてください。docker build --platform linux/amd64 -f Dockerfile -t $IMAGE_NAME .関数を作成します。
Function Compute コンソールにログインし、左側のナビゲーションウィンドウで関数をクリックします。
トップナビゲーションバーでリージョンを選択し、関数 ページで 関数を作成 をクリックします。
「関数の作成」ページで、コンテナーイメージ を選択し、次のパラメーターを設定してから、作成 をクリックします。
次の表に、主要なパラメーターを示します。その他のパラメーターはデフォルト値を使用してください。
パラメーター
説明
イメージ設定
イメージ選択モード
Container Registry イメージの使用 を選択します。
コンテナーイメージ
下にあるContainer Registry のイメージを選択をクリックし、コンテナーイメージの選択 パネルで、手順 3 でプッシュしたイメージを選択します。
リスニングポート
このパラメーターを 9000 に設定します。
詳細設定
GPU を使用するかどうか
GPU を使用する を選択します。
GPU カードタイプ
[NVIDIA T4] を選択します。
仕様
GPU メモリの仕様: 16 GB.
vCPU 仕様: 2 vCPU。
メモリ仕様: 16 GB.
関数のステータスが [OK] に変わったら、関数のアイドルモードを有効にします。

関数詳細ページで、設定 タブをクリックします。左側のナビゲーションウィンドウで、プロビジョニング済みインスタンス をクリックし、次に リザーブドインスタンス数ポリシーの作成 をクリックします。
リザーブドインスタンス数ポリシーの作成 パネルで、バージョンまたはエイリアス を LATEST に設定し、リザーブドインスタンスの数 を 1 に設定し、アイドルモード を 有効化 に設定してから、OK をクリックします。
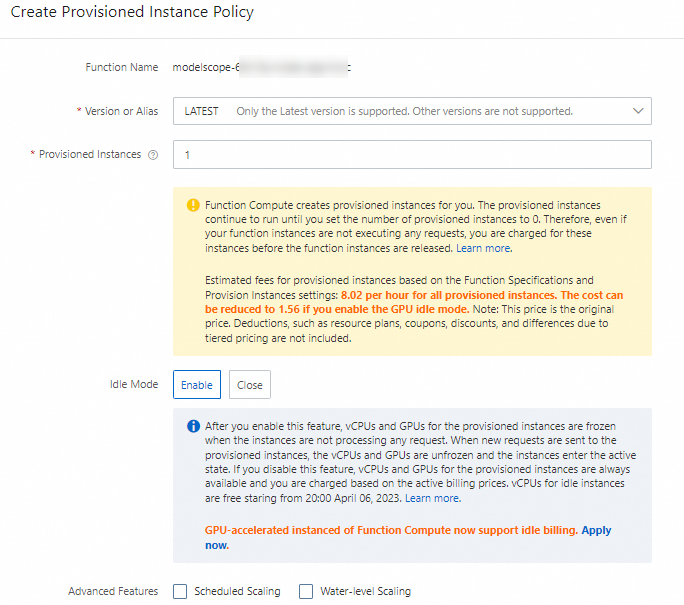
現在のリザーブドインスタンス が 1 に変わり、アイドルモードがオンになりました メッセージが表示されると、GPU で高速化された関数のプロビジョニング済みインスタンスが正常に起動します。

Google Gemma サービスの使用
関数詳細ページで、設定 タブをクリックします。左側のナビゲーションウィンドウで、トリガー をクリックします。[トリガー] ページで、トリガー URL を取得します。
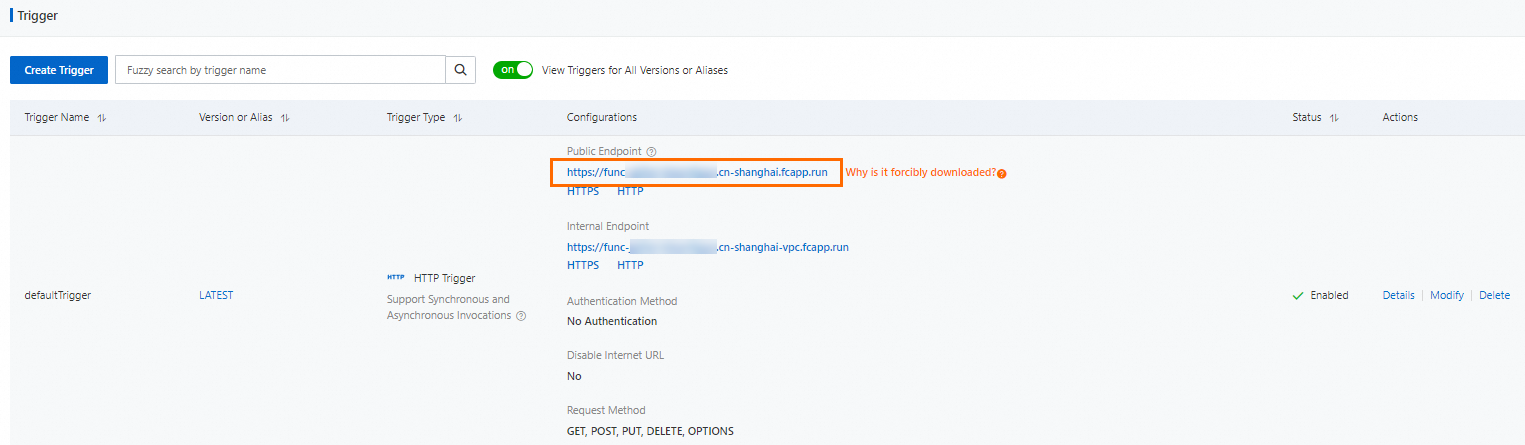
次のコマンドを実行して、関数を呼び出します。
curl -X POST -d "who are you" https://func-i****-****.cn-shanghai.fcapp.run/invoke想定される出力:
<bos>who are you? I am a large language model, trained by Google. I am a conversational AI that can understand and generate human language, and I am able to communicate and provide information in a comprehensive and informative way. What can I do for you today?<eos>「関数詳細」ページで、インスタンス タブをクリックします。ターゲットインスタンスを見つけ、操作 列の インスタンスのメトリクス をクリックします。インスタンスのメトリクス タブで、メトリックを表示します。
関数呼び出しが発生しない場合、インスタンスの GPU メモリ使用量がゼロに低下することがわかります。新しい関数呼び出しリクエストが到着すると、Function Compute は必要な GPU メモリリソースを迅速に復元して割り当てます。これにより、コストを削減できます。
説明インスタンスメトリックを表示するには、まずインスタンスのログ機能を有効にする必要があります。詳細については、「ログの設定」をご参照ください。
関数呼び出しが完了すると、Function Compute は自動的に GPU インスタンスをアイドルモードにします。手動での操作は必要ありません。次の呼び出しリクエストが到着すると、Function Compute はインスタンスを起動してアクティブ状態にし、リクエストを処理します。
リソースの削除
この関数を今後使用しない場合は、追加料金が発生しないようにリソースを削除してください。このアプリケーションを長期間使用する予定の場合は、このセクションをスキップしてください。
Function Compute コンソールの概要ページに戻ります。左側のナビゲーションウィンドウで、関数 をクリックします。
削除する関数を探し、操作 列で を選択します。表示されるダイアログボックスで、[上記のリソースとこの関数を削除することを確認します。削除後、これらのリソースは復元できないことを理解しています。] を選択し、[関数の削除] をクリックします。
課金
参考
Google のオープンモデルファミリーである Gemma の詳細については、「gemma-open-models」をご参照ください。
GPU インスタンスのアイドルモードと課金の例の詳細については、「課金概要」をご参照ください。