このトピックでは、準リアルタイム推論シナリオについて説明します。 このトピックでは、準リアルタイム推論シナリオでオンデマンドGPU高速化インスタンスを使用する方法と、準リアルタイム推論シナリオで費用対効果の高いサービスを構築する方法についても説明します。
概要
準リアルタイム推論シナリオのワークロードには、次の1つ以上の特性があります。
スパース呼び出し
毎日の呼び出しの数は数から数万の範囲であり、GPUリソースの実際の毎日の使用時間は、通常の使用時間である8〜12時間よりもはるかに短いです。 その結果、多くのGPUリソースがアイドル状態になることがよくあります。
長い処理時間
ほとんどの場合、準リアルタイム推論の処理時間は数秒から数分の範囲です。 例えば、典型的なコンピュータビジョン (CV) タスクの処理は数秒以内に完了し、ビデオタスクおよびAI生成コンテンツ (AIGC) タスクの処理は数分以内に完了する。
耐え難い寒さの始まり
GPUのコールドスタートは許容されるか、ビジネストラフィックが変動する場合にコールドスタートの可能性が低くなります。
Function ComputeのGPU高速化インスタンスは、準リアルタイム推論のワークロードに次の利点をもたらします。
ネイティブサーバーレス
Function Computeが提供するオンデマンドGPU高速化インスタンスは、GPUリソースを自動的に管理します。 リソースは、トラフィックの変化に基づいて自動的にスケーリングできます。 オフピーク時には、リソースをゼロにスケールダウンできます。 ピーク時には、リソースを数秒でスケールアップできます。 Function Computeでビジネスをデプロイすると、インフラストラクチャはFunction Computeによって完全に管理されます。 この方法では、ビジネスの反復のみを管理する必要があります。
最適な仕様
Function Computeは、ビジネス要件を満たすためにGPU高速化インスタンスのさまざまな仕様を提供します。 さまざまな種類のグラフィックカードを選択し、カスタムvCPU、vGPU、メモリ、およびディスクの仕様を設定できます。 vGPUメモリの最小サイズは1 GBです。
最適なコスト効率
Function Computeは、従量課金と1秒あたりの課金方法をサポートしています。 これは、リソースコストの削減に役立ちます。 GPUの使用率が低いワークロードの場合、コストを70% 以上削減できます。
Burst trafficのサポート
Function Computeは豊富なGPUリソースを提供します。 ビジネスでトラフィックバーストが発生すると、Function Computeは数秒で多数のGPUコンピューティングリソースを提供します。 これにより、GPUコンピューティングパワーの供給不足や遅延によるビジネスへの悪影響を防ぐことができます。
制御ポリシー機能の動作
デフォルトでは、オンデマンドのGPUアクセラレーションインスタンスは、GPU関数をデプロイした後、準リアルタイム推論シナリオでリクエストを処理するために使用されます。 Function Computeは、プロビジョニングされたGPU高速化インスタンスも提供します。 詳細は、「インスタンスモード」をご参照ください。
推論リクエストをGPU関数のトリガーに送信できます。 たとえば、HTTPリクエストをHTTPトリガーに送信して、関数の実行をトリガーできます。 GPU関数がトリガーされると、GPUコンテナーでモデル推論が実行されて完了し、推論結果がレスポンスで返されます。 Function Computeは、ビジネス要件を満たすために、GPUリソースの自動オーケストレーションとエラスティックスケーリングを実行できます。 リクエスト処理中に使用されるGPUリソースに対してのみ料金を支払う必要があります。

コンテナのサポート
Function ComputeのGPU高速化インスタンスは、カスタムコンテナランタイムでのみ使用できます。 カスタムコンテナの詳細については、「概要」をご参照ください。
カスタムコンテナランタイムは、webサーバーモードと非webサーバーモードをサポートします。 オンライン推論シナリオでは、webサーバーモードのコンテナーが使用されます。 オフラインシナリオでは、非webサーバーモードのコンテナーが使用されます。
webサーバーモードを有効にする場合は、さまざまなコードパスとイベントベースまたはHTTPベースの関数トリガーの要件を満たすように、コンテナーイメージにwebサーバーを実装する必要があります。 Webサーバーモードは、AI学習や推論などのマルチパス要求実行シナリオに適用できます。 詳細については、「Webサーバーモード」をご参照ください。
GPU高速化インスタンスの仕様
推論シナリオでは、さまざまなGPUカードタイプを選択し、ビジネスで必要とされる計算能力に基づいてGPU高速化インスタンスの仕様を設定できます。 GPU高速化インスタンスの仕様には、GPUメモリ、メモリ、およびディスク容量が含まれます。 GPU高速化インスタンスの仕様の詳細については、「インスタンス仕様」をご参照ください。
デプロイ方法
次のいずれかの方法を使用して、Function Computeにモデルをデプロイできます。
Function Computeコンソールを使用します。 詳細については、「Function Computeコンソールを使用した関数の作成」をご参照ください。
SDKを呼び出します。 詳細については、「機能別操作一覧」をご参照ください。
Serverless Devsを使用します。 詳細については、「Serverless Devsコマンド」をご参照ください。
その他のデプロイ例については、「start-fc-gpu」をご参照ください。
同時要求
GPU関数がリージョンで処理できる同時リクエストの最大数は、GPUアクセラレーションインスタンスの同時実行性と使用できるグラフィックカードの最大数に基づいています。
GPU高速化インスタンスの同時実行性
デフォルトでは、GPUアクセラレーションインスタンスの同時実行性は1に設定されています。 つまり、GPUアクセラレーションインスタンスは一度に1つのリクエストしか処理できません。 Function Computeコンソールまたはサーバーレスデバイスを使用して、GPUアクセラレーションインスタンスの同時実行性を変更できます。 詳細については、「インスタンス同時実行の設定」をご参照ください。 ビジネス要件に基づいて、GPU高速化インスタンスの同時実行設定を構成することを推奨します。
計算集約型推論アプリケーション: デフォルト値1を使用することを推奨します。
リクエストのバッチ集約をサポートする推論アプリケーション: バッチで集約できる推論リクエストの数に基づいて同時実行設定を構成することを推奨します。
物理GPUカードの最大数
GPUの最大数の詳細については、「GPUカードの制限」をご参照ください。
コールドスタート
リクエストが一定期間処理されていない場合、すべてのオンデマンドGPUアクセラレーションインスタンスはFunction Computeによってリリースされます。 この場合、最初の新しいリクエストが送信されたときにclodスタートが発生し、Function Computeはリクエストを処理するためにインスタンスをプルするためにより多くの時間を必要とします。 これには、GPUリソースの準備、コンテナイメージの取得、GPUコンテナの起動、アルゴリズムモデルの読み込みと初期化、推論アプリケーションの起動が含まれます。 詳細については、「コールドスタートの待ち時間を短縮するためのベストプラクティス」をご参照ください。
AIアプリケーションのコールドスタートの期間は、画像サイズ、モデルサイズ、および初期化にかかる時間によって異なります。 モニタリング指標を使用して、コールドスタートにかかる時間を観察し、コールドスタートの確率を推定できます。
コールドスタート
次の図は、Function ComputeのGPUアクセラレーションインスタンスの一般的なモデルのエンドツーエンドのコールドスタートの期間を示しています。
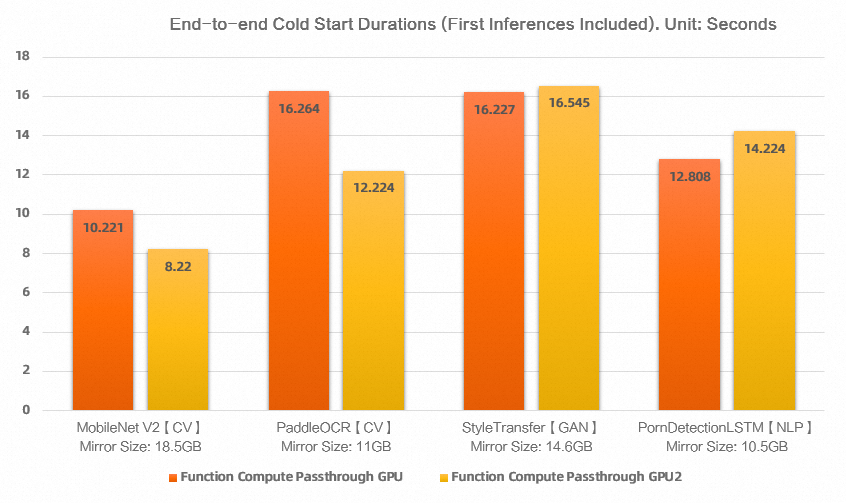
エンドツーエンドのコールドスタートに必要な時間は、10〜30秒の範囲です。 時間は、コールドスタートと最初のリクエストの処理によって消費される合計時間です。
コールドスタートの確率
Function ComputeのサーバーレスGPUのコールドスタートは、数秒以内に完了できます。 KubernetesベースのプラットフォームでGPUをコールドスタートするには、数分かかります。 Function Computeインスタンスのコールドスタートの確率は、インスタンスの同時実行性が高くなるにつれて低下します。 コールドスタートが少ないと、ビジネスへの影響が少なくなります。
コスト評価
以下の例で提供される単価は、参考のためだけのものである。 ビジネスマネージャーが提供する実際の価格が優先されます。
Function Computeを使用する前の毎日のGPU使用率が低いほど、Function Computeを使用した後のコストを節約できます。
次の例では、ECS (Elastic Compute Service) のGPU高速化インスタンスをFunction ComputeのGPU高速化インスタンスと比較します。 どちらのインスタンスもTesla T4グラフィックカードを使用しています。 同じ仕様のGPUアクセラレーションECSインスタンスの単価は約です。 USD 2 /時間。 課金の詳細については、「Elastic GPUサービスの課金」をご参照ください。
例 1
GPU関数に対して1日あたり1秒間持続する3,600の呼び出しが開始されるとします。 この関数は、メモリが4 GB、モデルサイズが3 GBのGPUアクセラレーションインスタンスを使用します。
毎日のGPU使用率は4.1% です。 GPU使用率は、以下の式を使用することによって計算される: 3,600/86,400 = 0.041。 この場合、GPUのメモリ使用量は除外されます。
ECSでGPUリソースを使用するために請求される1日あたりの料金はUSD 48です。 料金は次の式を使用して計算されます: 2 × 24 = 48。
Function Computeの1日あたりの平均GPUリソース料金=3,600秒 × 4 GB × USD 0.000105/ GB秒= USD 1.512
ECSと比較して、Function Computeはコストを95% 削減します。
例 2
それぞれ1秒間続く50,000の呼び出しが、GPU関数に対して1日あたりに開始されると仮定します。 この関数は、メモリが4 GB、モデルサイズが3 GBのGPUアクセラレーションインスタンスを使用します。
毎日のGPU使用率は57% です。 GPU使用率は、以下の式を使用することによって計算される: 50,000/86,400 = 0.57。 この場合、GPUのメモリ使用量は除外されます。
ECSでGPUリソースを使用するために請求される1日あたりの料金はUSD 48です。 料金は次の式を使用して計算されます: 2 × 24 = 48。
Function Computeの1日あたりの平均GPUリソース料金=50,000秒 × 4 GB × USD 0.000105/ GB秒= USD 21
ECSと比較して、Function Computeはコストを55% 削減します。