Hive カタログは、Realtime Compute for Apache Flink を Hive メタストアまたは Alibaba Cloud Data Lake Formation (DLF) に接続し、各テーブルごとに DDL ステートメントを宣言することなく、Hive テーブルのクエリおよび書き込みを可能にします。Hive カタログに登録されたテーブルは、ストリーミングおよびバッチの両方のデプロイメントにおいて、ソーステーブル、結果テーブル、またはディメンションテーブルとして利用できます。
このトピックでは、以下の内容について説明します。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
Hive メタストアを使用する場合:
Hive メタストアサービスが実行中である必要があります。起動するには、
hive --service metastoreを実行します。デフォルトポート(9083)でリッスンしていることを確認するには、netstat -ln | grep 9083を実行します。また、hive-site.xmlで異なるポートを設定している場合は、9083の代わりにそのポート番号を指定してください。Hive メタストアサービスに対してホワイトリストが構成されており、Realtime Compute for Apache Flink の CIDR ブロックが追加されている必要があります。手順については、「ホワイトリストの構成」および「セキュリティグループルールの追加」をご参照ください。
Alibaba Cloud DLF を使用する場合:
お客様の Alibaba Cloud アカウントで DLF が有効化されました。
制限事項
| 制限事項 | 詳細 |
|---|---|
| サポートされるメタストアの種類 | セルフマネージド型の Hive メタストア |
| サポートされる Hive のバージョン | 2.0.0~2.3.9 および 3.1.0~3.1.3 |
| 旧バージョンの Hive(1.X、2.1.X、2.2.X) | Apache Flink 1.16 以降では非対応。Ververica Runtime (VVR) 6.X が必要です。 |
| DLF バックエンドのカタログにおける非 Hive テーブル | VVR 8.0.6 以降が必要です。 |
| Hive カタログ経由での OSS-HDFS への書き込み | VVR 8.0.6 以降が必要です。 |
Hive メタデータの構成
Hive カタログを作成する前に、Hadoop クラスターを Realtime Compute for Apache Flink が実行される仮想プライベートクラウド(VPC)に接続し、構成ファイルを Object Storage Service(OSS)にアップロードしてください。
ステップ 1:Hadoop クラスターを VPC に接続
VPC 内で Hadoop のホスト名を解決するために、Alibaba Cloud DNS PrivateZone を使用します。設定手順については、「リゾルバ」をご参照ください。
ステップ 2:hive-site.xml におけるメタストアの構成
ご使用の環境に合ったメタストアの種類を選択してください。
Hive メタストア
hive.metastore.uris が hive-site.xml で、Hive ホストの内部またはパブリック IP アドレスを指していることを確認してください。
<property>
<name>hive.metastore.uris</name>
<value>thrift://xx.yy.zz.mm:9083</value>
<description>リモートメタストアの Thrift URI。メタストアクライアントがリモートメタストアに接続するために使用されます。</description>
</property>hive.metastore.urisをホスト名(IP アドレスではなく)に設定した場合、Alibaba Cloud DNS PrivateZone を使用してそのホスト名を解決するように構成してください。DNS 解決が行われていないと、Ververica Platform(VVP)がメタストアへの接続時にUnknownHostExceptionを返します。詳細については、「プライベートゾーンへの DNS レコードの追加」をご参照ください。
Alibaba Cloud DLF
hive-site.xml に dlf.catalog.akMode のエントリが含まれている場合は、続行する前に削除してください。このエントリが残っていると、Hive カタログが DLF にアクセスできなくなります。
hive-site.xml に以下のプロパティを追加してください。
<property>
<name>hive.imetastoreclient.factory.class</name>
<value>com.aliyun.datalake.metastore.hive2.DlfMetaStoreClientFactory</value>
</property>
<property>
<name>dlf.catalog.uid</name>
<value>${YOUR_DLF_CATALOG_UID}</value>
</property>
<property>
<name>dlf.catalog.endpoint</name>
<value>${YOUR_DLF_ENDPOINT}</value>
</property>
<property>
<name>dlf.catalog.region</name>
<value>${YOUR_DLF_CATALOG_REGION}</value>
</property>
<property>
<name>dlf.catalog.accessKeyId</name>
<value>${YOUR_ACCESS_KEY_ID}</value>
</property>
<property>
<name>dlf.catalog.accessKeySecret</name>
<value>${YOUR_ACCESS_KEY_SECRET}</value>
</property>| パラメーター | 必須 | 説明 |
|---|---|---|
dlf.catalog.uid | はい | ご利用の Alibaba Cloud アカウント ID。これは「セキュリティ設定」ページで確認できます。 |
dlf.catalog.endpoint | はい | DLF サービスのエンドポイント。ご使用のリージョンの VPC エンドポイント(例:dlf-vpc.cn-hangzhou.aliyuncs.com)をご利用ください。すべてのエンドポイント一覧については、「サポートされるリージョンとエンドポイント」をご参照ください。VPC を跨いだアクセスについては、「Realtime Compute for Apache Flink による VPC 間サービスへのアクセス方法 |
dlf.catalog.region | はい | DLF が有効化されているリージョン ID。これは dlf.catalog.endpoint のリージョンと一致させる必要があります。「サポートされるリージョンとエンドポイント」をご参照ください。 |
dlf.catalog.accessKeyId | はい | ご利用の Alibaba Cloud アカウントの AccessKey ID。「AccessKey ペアの取得」をご参照ください。 |
dlf.catalog.accessKeySecret | はい | ご利用の Alibaba Cloud アカウントの AccessKey Secret。「AccessKey ペアの取得」をご参照ください。 |
ステップ 3:hive-site.xml におけるテーブルストレージの構成
Hive カタログは、テーブルデータのストレージバックエンドとして OSS および OSS-HDFS の 2 種類をサポートしています。
OSS
hive-site.xml に以下のプロパティを追加してください。
<property>
<name>fs.oss.impl.disable.cache</name>
<value>true</value>
</property>
<property>
<name>fs.oss.impl</name>
<value>org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>${YOUR_OSS_WAREHOUSE_DIR}</value>
</property>
<property>
<name>fs.oss.endpoint</name>
<value>${YOUR_OSS_ENDPOINT}</value>
</property>
<property>
<name>fs.oss.accessKeyId</name>
<value>${YOUR_ACCESS_KEY_ID}</value>
</property>
<property>
<name>fs.oss.accessKeySecret</name>
<value>${YOUR_ACCESS_KEY_SECRET}</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>oss://${YOUR_OSS_BUCKET_DOMIN}</value>
</property>| パラメーター | 必須 | 説明 |
|---|---|---|
hive.metastore.warehouse.dir | はい | テーブルデータを格納するディレクトリ。 |
fs.oss.endpoint | はい | OSS エンドポイント。「リージョンとエンドポイント」をご参照ください。 |
fs.oss.accessKeyId | はい | AccessKey ID。「AccessKey ペアの取得」をご参照ください。 |
fs.oss.accessKeySecret | はい | AccessKey Secret。「AccessKey ペアの取得」をご参照ください。 |
fs.defaultFS | はい | テーブルデータのデフォルトファイルシステム。対象バケットの HDFS エンドポイント(例:oss://oss-hdfs-bucket.cn-hangzhou.oss-dls.aliyuncs.com/)を指定します。 |
OSS-HDFS
hive-site.xmlに以下のプロパティを追加してください。パラメーター 必須 説明 hive.metastore.warehouse.dirはい テーブルデータを格納するディレクトリ。 fs.oss.endpointはい OSS エンドポイント。「リージョンとエンドポイント」をご参照ください。 fs.oss.accessKeyIdはい AccessKey ID。「AccessKey ペアの取得」をご参照ください。 fs.oss.accessKeySecretはい AccessKey Secret。「AccessKey ペアの取得」をご参照ください。 fs.defaultFSはい テーブルデータのデフォルトファイルシステム。対象バケットの HDFS エンドポイント(例: oss://oss-hdfs-bucket.cn-hangzhou.oss-dls.aliyuncs.com/)を指定します。<property> <name>fs.jindo.impl</name> <value>com.aliyun.jindodata.jindo.JindoFileSystem</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>${YOUR_OSS_WAREHOUSE_DIR}</value> </property> <property> <name>fs.oss.endpoint</name> <value>${YOUR_OSS_ENDPOINT}</value> </property> <property> <name>fs.oss.accessKeyId</name> <value>${YOUR_ACCESS_KEY_ID}</value> </property> <property> <name>fs.oss.accessKeySecret</name> <value>${YOUR_ACCESS_KEY_SECRET}</value> </property> <property> <name>fs.defaultFS</name> <value>oss://${YOUR_OSS_HDFS_BUCKET_DOMIN}</value> </property>(任意)OSS-HDFS に格納された Parquet 形式の Hive テーブルを読み取る予定がある場合は、Realtime Compute for Apache Flink に以下の構成を追加してください。
fs.oss.jindo.accessKeyId: ${YOUR_ACCESS_KEY_ID} fs.oss.jindo.accessKeySecret: ${YOUR_ACCESS_KEY_SECRET} fs.oss.jindo.endpoint: ${YOUR_JINODO_ENDPOINT} fs.oss.jindo.buckets: ${YOUR_JINDO_BUCKETS}パラメーターの詳細については、「OSS-HDFS へのデータ書き込み」をご参照ください。
ご利用のデータがすでに Realtime Compute for Apache Flink 上に格納されている場合は、ステップ 2~3 をスキップし、直接「Hive カタログの作成」に進んでください。
ステップ 4:構成ファイルを OSS にアップロード
OSS コンソール にログインし、左側のナビゲーションウィンドウで [バケット] をクリックします。
ご利用の Realtime Compute for Apache Flink ワークスペースで使用するバケットの名前をクリックします。
パス
oss://${bucket}/artifacts/namespaces/${ns}/にフォルダ${hms}を作成します。手順については、「ディレクトリの作成」をご参照ください。Realtime Compute for Apache Flink は、ワークスペースのプロビジョニング時に自動的に
/artifacts/namespaces/${ns}/ディレクトリを作成します。OSS コンソールにこのディレクトリが表示されない場合は、開発コンソールの [アーティファクト] ページで任意のファイルをアップロードして、ディレクトリの作成をトリガーしてください。変数 説明 ${bucket}ご利用の Realtime Compute for Apache Flink ワークスペースで使用するバケット ${ns}Hive カタログを作成するワークスペースの名前 ${hms}フォルダ名。作成する Hive カタログと同じ名前を使用します oss://${bucket}/artifacts/namespaces/${ns}/${hms}/内で、以下の 2 つのサブディレクトリを作成します。両方のディレクトリを作成後、OSS コンソールで [ファイル] > [プロジェクト] に移動して、ディレクトリ構造を確認し、OSS の URL をコピーしてください。hive-conf-dir/—hive-site.xmlを格納hadoop-conf-dir/— Hadoop 構成ファイルを格納
hive-site.xmlをhive-conf-dir/にアップロードします。「オブジェクトのアップロード」をご参照ください。以下のファイルを
hadoop-conf-dir/にアップロードします。「オブジェクトのアップロード」をご参照ください。hive-site.xmlcore-site.xmlhdfs-site.xmlmapred-site.xmlHive デプロイメントで使用される圧縮パッケージなど、その他の必要なファイル
Hive カタログの作成
Hive メタデータの構成が完了したら、コンソールから、または SQL ステートメントを実行して Hive カタログを作成します。コンソールからの方法を推奨します。
Hive カタログを作成した後は、その構成を変更することはできません。パラメーターを変更する場合は、カタログを削除してから再作成してください。
コンソールから Hive カタログを作成
Realtime Compute for Apache Flink コンソール にログインします。ワークスペースを見つけ、[コンソール] を [操作] 列からクリックします。
[カタログ] をクリックします。
[カタログ一覧] ページで、[カタログの作成] をクリックします。ダイアログボックスで、[組み込みカタログ] タブに移動し、[カタログタイプの選択] ステップで [Hive] を選択し、[次へ] をクリックします。
[カタログの構成] ステップで、以下のパラメーターを設定します。
パラメーター 必須 説明 catalog nameはい Hive カタログの名前 hive-versionはい Hive メタストアのバージョン。サポートされているバージョン: 2.0.0~2.3.9、3.1.0~3.1.3。インストールされているバージョンをマッピングします: 2.0.X または 2.1.X → 2.2.0; 2.2.X →2.2.0; 2.3.X →2.3.6; 3.1.X →3.1.2default-databaseはい デフォルトデータベースの名前 hive-conf-dirはい hive-site.xmlを含むディレクトリへの OSS パス。ステップ 4 で作成済み。フルマネージドストレージの場合、プロンプトに従ってファイルをアップロードします。hadoop-conf-dirはい Hadoop 構成ファイルを含むディレクトリへの OSS パス。ステップ 4 で作成済み。フルマネージドストレージの場合、プロンプトに従ってファイルをアップロードします。 hive-kerberosいいえ Kerberos 認証を有効にし、登録済みの Kerberized Hive クラスターと Kerberos プリンシパルを関連付けます。「Kerberized Hive クラスターを登録する [確認] をクリックします。
[カタログ一覧] ページの左側にある [カタログ] ペインで、新しいカタログが表示されていることを確認します。
SQL ステートメントを実行して Hive カタログを作成
[スクリプト] ページで、以下のステートメントを実行します。
パラメーター 必須 説明 ${HMS Name}はい Hive カタログの名前 typeはい コネクタの種類。値を hivedefault-databaseはい デフォルトデータベースの名前 hive-versionはい Hive メタストアのバージョン。サポートされるバージョン:2.0.0~2.3.9、3.1.0~3.1.3。インストール済みのバージョンに応じてマッピングを行います:2.0.X または 2.1.X → 2.2.0;2.2.X →2.2.0;2.3.X →2.3.6;3.1.X →3.1.2hive-conf-dirはい hive-site.xml を含むディレクトリへの OSS パス。 hive-site.xmlの詳細については、「Hive メタデータの設定hadoop-conf-dirはい Hadoop 構成ファイルを含むディレクトリの OSS パス。「Hive メタデータの構成 CREATE CATALOG ${HMS Name} WITH ( 'type' = 'hive', 'default-database' = 'default', 'hive-version' = '<hive-version>', 'hive-conf-dir' = '<hive-conf-dir>', 'hadoop-conf-dir' = '<hadoop-conf-dir>' );CREATE CATALOGステートメントを選択し、[実行] をクリックします。
カタログが作成されると、そのカタログ内のテーブルは、DDL ステートメントを宣言せずにドラフト内で結果テーブルまたはディメンションテーブルとして利用可能になります。テーブル名の形式は ${hive-catalog-name}.${hive-db-name}.${hive-table-name} です。
Hive カタログの使用
以下のすべての例では、カタログ名を flinkexporthive、データベース名を flinkhive とします。
Hive テーブルの作成
UI メソッド
コンソールから:
Realtime Compute for Apache Flink コンソール にログインし、ワークスペースを見つけ、[コンソール] を [操作] 列からクリックします。
[カタログ] をクリックしてください。
[カタログ一覧] ページで、対象のカタログを見つけ、[表示] を [操作] 列からクリックします。
対象のデータベースを見つけ、[表示] を [操作] 列からクリックします。
[テーブルの作成] をクリックします。
[テーブルの作成] ダイアログボックスの [組み込み] タブで、[接続タイプ] ドロップダウンリストからテーブルタイプを選択し、コネクタタイプを選択して、[次へ] をクリックします。
テーブル作成ステートメントを入力し、パラメーターを構成します。
CREATE TABLE `${catalog_name}`.`${db_name}`.`${table_name}` ( id INT, name STRING ) WITH ( 'connector' = 'hive' );[OK] をクリックします。
SQL コマンドメソッド
SQL ステートメントを実行して:
[スクリプト] ページで、CREATE TABLE ステートメントを実行し、その後選択して [実行] をクリックします。
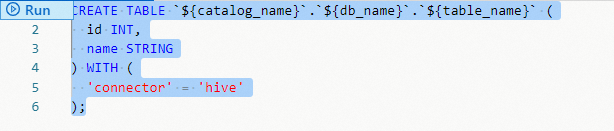
例 — flink_hive_test テーブルを flinkhive データベース内、flinkexporthive カタログ下に作成します。
-- flinkexporthive カタログ下の flinkhive データベースに flink_hive_test という名前のテーブルを作成します。
CREATE TABLE `flinkexporthive`.`flinkhive`.`flink_hive_test` (
id INT,
name STRING
) WITH (
'connector' = 'hive'
);Hive テーブルの変更
[スクリプト] ページで、ALTER TABLE ステートメントを実行します。
-- Hive テーブルにカラムを追加します。
ALTER TABLE `${catalog_name}`.`${db_name}`.`${table_name}`
ADD column type-column;
-- Hive テーブルからカラムを削除します。
ALTER TABLE `${catalog_name}`.`${db_name}`.`${table_name}`
DROP column;例 — color カラムを flink_hive_test テーブルに追加し、その後削除します。
-- Hive テーブルに color フィールドを追加します。
ALTER TABLE `flinkexporthive`.`flinkhive`.`flink_hive_test`
ADD color STRING;
-- Hive テーブルから color フィールドを削除します。
ALTER TABLE `flinkexporthive`.`flinkhive`.`flink_hive_test`
DROP color;Hive テーブルからのデータ読み取り
INSERT INTO ${other_sink_table}
SELECT ...
FROM `${catalog_name}`.`${db_name}`.`${table_name}`;Hive テーブルへのデータ書き込み
INSERT INTO `${catalog_name}`.`${db_name}`.`${table_name}`
SELECT ...
FROM ${other_source_table};Hive テーブルの削除
UI メソッド
コンソールから:
Realtime Compute for Apache Flink コンソール にログインし、ワークスペースを見つけ、[コンソール] を [操作] 列からクリックします。
[カタログ] をクリックします。
[カタログ] ペインで、対象のカタログおよびデータベース下の対象テーブルに移動します。
テーブルの詳細ページで、[削除] を [操作] 列からクリックします。
確認ダイアログで、[OK] をクリックします。
SQL コマンドメソッド
SQL ステートメントを実行して:
[スクリプト] ページで、以下のステートメントを実行します。
-- Hive テーブルを削除します。
DROP TABLE `${catalog_name}`.`${db_name}`.`${table_name}`;例:
-- Hive テーブルを削除します。
DROP TABLE `flinkexporthive`.`flinkhive`.`flink_hive_test`;Hive カタログの表示
Realtime Compute for Apache Flink コンソール にログインし、ワークスペースを見つけ、[コンソール] を [操作] 列からクリックします。
[カタログ] をクリックします。
[カタログ一覧] ページで、カタログの [名前] および [タイプ] 列を確認します。
カタログ内のデータベースおよびテーブルを表示するには、[表示] を [操作] 列からクリックします。
Hive カタログの削除
Hive カタログを削除しても、実行中のデプロイメントには影響しません。ただし、未公開のドラフトや、一時停止および再開が必要なデプロイメントには影響します。必要に応じてのみカタログを削除してください。
コンソールから Hive カタログを削除
Realtime Compute for Apache Flink コンソール にログインし、ワークスペースを見つけ、[コンソール] を [操作] 列からクリックします。
[カタログ] をクリックします。
[カタログ一覧] ページで、対象のカタログを見つけ、[削除] を [操作] 列からクリックします。
確認ダイアログで、[削除] をクリックします。
[カタログ] ペインにカタログが表示されなくなったことを確認します。
SQL ステートメントを実行して Hive カタログを削除
[スクリプト] ページで、以下のステートメントを実行します。
DROP CATALOG ${HMS Name};${HMS Name}は、Realtime Compute for Apache Flink の開発コンソールに表示されるカタログ名です。ステートメントを右クリックし、ショートカットメニューから [実行] を選択します。
[カタログ] ペインにカタログが表示されなくなったことを確認します。