Flink SQL を使用してリアルタイムデータ処理を行う際、順序が正しくないチェンジログイベントは、気づかないうちに結果の不整合を引き起こす可能性があります。具体的には、レコードが存在すべきなのに削除されたり、更新が誤った順序で適用されたりします。このトピックでは、順序が正しくないイベントが発生する理由、SinkUpsertMaterializer がそれをどのように修正するのか、そしてパフォーマンスが重要な場合にこの演算子をチューニングまたは回避する方法について説明します。
基本概念
チェンジログとストリームタイプ
MySQL などのリレーショナルデータベースでは、バイナリログ (binlog) がすべての INSERT、UPDATE、DELETE 操作をキャプチャします。Flink SQL はチェンジログと呼ばれる同様のメカニズムを使用してデータの変更を追跡し、ストリーミングパイプライン全体で増分処理を可能にします。
チェンジログストリームは、次の 2 つのカテゴリのいずれかに分類されます。
| ストリームタイプ | イベントタイプ | 説明 |
|---|---|---|
| アペンドオンリーストリーム | +I のみ | INSERT イベントのみを含みます。更新や削除はありません。非更新ストリームとも呼ばれます。 |
| 更新ストリーム | +I、+U、-U、-D | 挿入に加えて、更新または削除イベントを含みます。グループ集約や重複排除などの演算子がこのタイプを生成します。 |
すべての演算子が更新ストリームを消費できるわけではありません。Over 集計演算子や Interval Join 演算子は、入力としてアペンドオンリーストリームのみを受け付けます。
チェンジログイベントのタイプ
Flink SQL は、Apache Flink API の RowKind enum に基づいて、4 種類のイベントタイプを使用します。
| 短縮名 | 完全名 | セマンティクス |
|---|---|---|
+I |
INSERT | 新しい行を挿入します。 |
-U |
UPDATE_BEFORE | 更新された行の以前の内容を取り消します。常に +U イベントとペアになります。 |
+U |
UPDATE_AFTER | 更新された行の新しい内容を含みます。常に -U イベントとペアになります。 |
-D |
DELETE | 行を削除します。 |
Flink が UPDATE_BEFORE (-U) と UPDATE_AFTER (+U) を複合 UPDATE イベントにまとめるのではなく、個別のイベントタイプとして保持しているのには、2 つの理由があります。
-
統一された構造:両方のイベントは同じ行構造を共有し、
RowKindプロパティによってのみ区別されます。複合イベントタイプでは、構造が不均一になったり、INSERT イベントと DELETE イベント間で特別な調整が必要になったりします。 -
分散シャッフル:並列パイプラインでは、Join や集計操作によってタスク間でデータがシャッフルされます。複合 UPDATE イベントは、正確性を維持するためにシャッフル中に個別のイベントに分割される必要があるため、最初から分離しておくことでモデルが簡素化されます。
順序が正しくないイベントの発生メカニズム
このトピックでは、以下の例を用いて問題と解決策を説明します。
-- CDC ソーステーブル
CREATE TEMPORARY TABLE s1 (
id BIGINT,
level BIGINT,
PRIMARY KEY(id) NOT ENFORCED
) WITH (...);
CREATE TEMPORARY TABLE s2 (
id BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
) WITH (...);
-- シンクテーブル
CREATE TEMPORARY TABLE t1 (
id BIGINT,
level BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
) WITH (...);
-- s1 と s2 を結合し、結果を t1 に書き込みます
INSERT INTO t1
SELECT s1.*, s2.attr
FROM s1 JOIN s2
ON s1.level = s2.id;テーブル s1 のレコード (id=1, level=10) が時刻 t0 に挿入され、時刻 t1 に (id=1, level=20) に更新されると、3 つの変更ログイベントが生成されます:
| イベント | タイプ |
|---|---|
+I (id=1, level=10) |
INSERT |
-U (id=1, level=10) |
UPDATE_BEFORE |
+U (id=1, level=20) |
UPDATE_AFTER |
s1 の主キーは id ですが、JOIN 句は level 列でデータをシャッフルします。Join 演算子の並列度が 2 の場合、これら 3 つのイベントは 2 つの異なるタスクにルーティングされる可能性があります。1 つは level=10 を処理し、もう 1 つは level=20 を処理します。
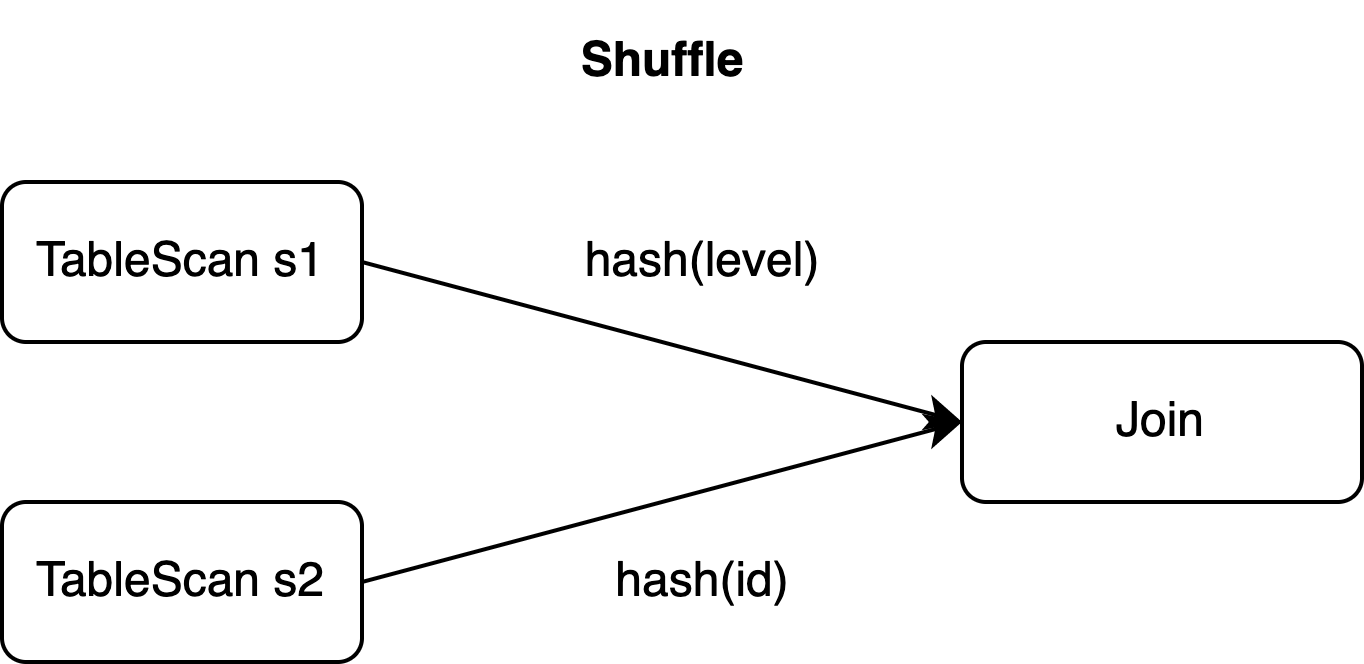
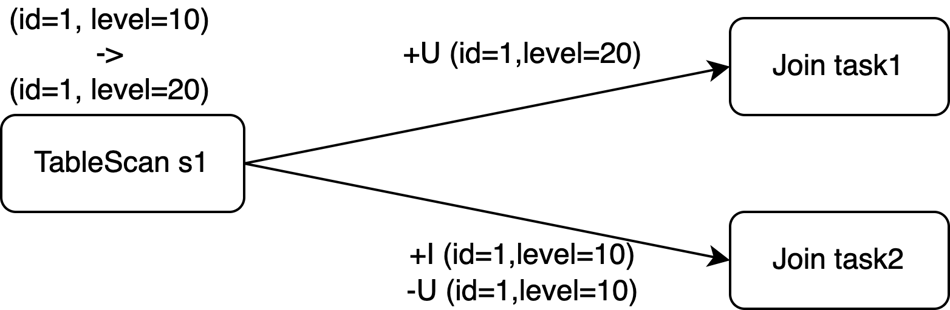
イベントは並列で処理されるため、下流の Sink 演算子は、次の 3 通りの順序のいずれかでイベントを受信する可能性があります。
| ケース 1 (正しい順序) | ケース 2 (順序が正しくない) | ケース 3 (順序が正しくない) |
|---|---|---|
+I (id=1, level=10, attr='a1') |
+U (id=1, level=20, attr='b1') |
+I (id=1, level=10, attr='a1') |
-U (id=1, level=10, attr='a1') |
+I (id=1, level=10, attr='a1') |
+U (id=1, level=20, attr='b1') |
+U (id=1, level=20, attr='b1') |
-U (id=1, level=10, attr='a1') |
-U (id=1, level=10, attr='a1') |
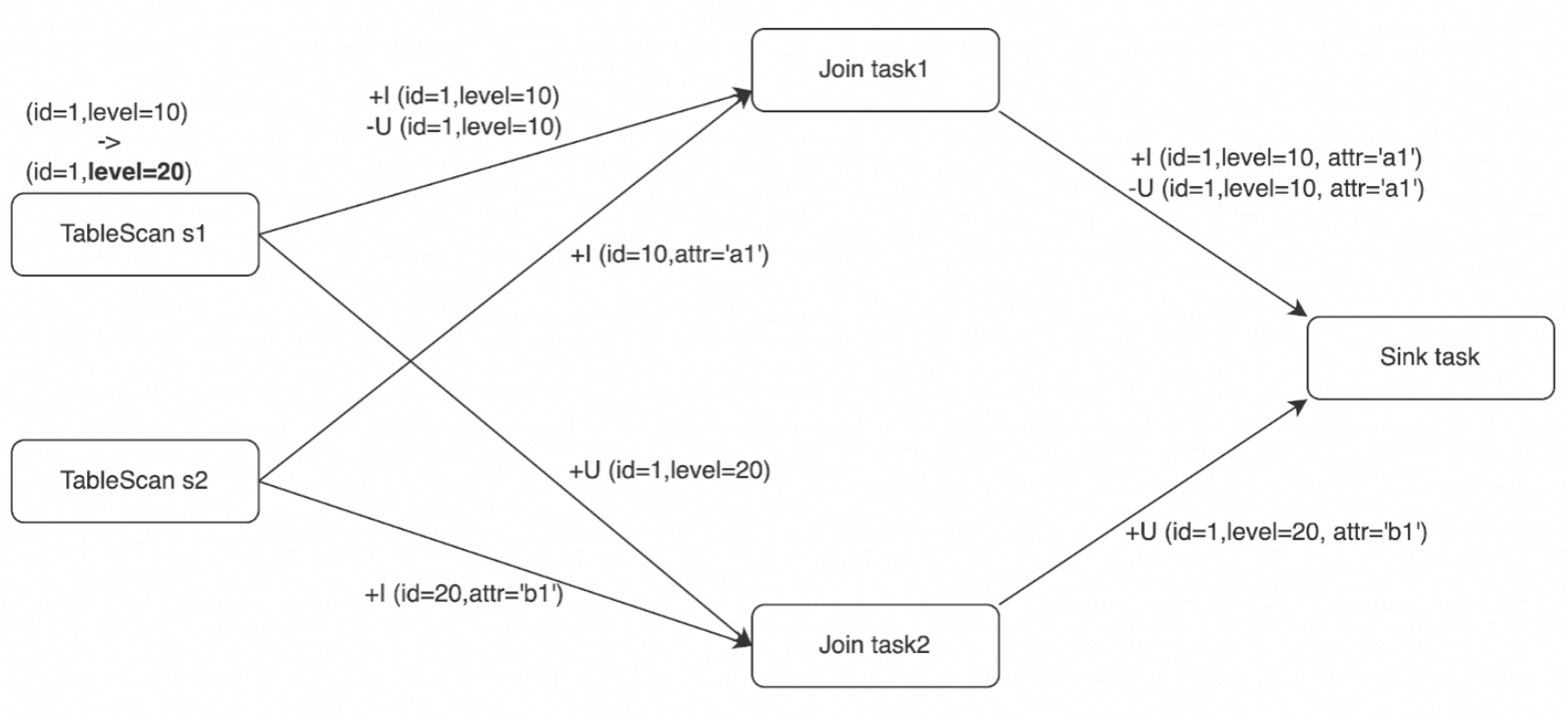
ケース 1 はイベントを元の順序で処理します — 問題ありません。ケース 2 とケース 3 では、シンクテーブルは id を主キーとしています。外部ストレージがアップサートを実行すると、期待される最終状態が (id=1, level=20, attr='b1') であるにもかかわらず、id=1 のレコードは削除されてしまいます。
順序が正しくないイベントは、Join 演算子の並列度が 1 より大きい場合にのみ発生します。同じアップサートキーを持つイベントのペアは常に同じタスクにルーティングされるため、このシナリオでは 3 つの順序パターンのみが考えられます。
SinkUpsertMaterializer
仕組み
SinkUpsertMaterializer は、Flink が順序の問題を解決するために挿入する中間演算子です。これは FLINK-20374 に対応するために導入されました。
SinkUpsertMaterializer がなぜ必要かを理解するには、upsert キーを理解することが役立ちます。[upsert キー] とは、SQL 操作を通じて一意キーのソート順を維持するカラム (または一連のカラム) です。upsert キーが存在する場合、ダウンストリームオペレーターは更新イベントを正しい順序で受信します。この例の level に対する JOIN のように、データシャッフル操作によって一意キーの順序が崩れると、upsert キーは空になります。
この例では、s1 からの行は level によってシャッフルされるため、Join 出力には同じ s1.id 値を持つ行が任意な順序で含まれます。一意キーは (s1.id)、(s1.id, s1.level)、および (s1.id, s2.id) ですが、upsert キーは空です。さらに、sink テーブルの主キー (id) は、Join 出力内の upsert キーと一致しません。SinkUpsertMaterializer がこのギャップを埋めます。
順序が乱れたチェンジログイベントは特定のルールに従い、特定の upsert キー (または upsert キーが空の場合はすべての列) に対して、ADD イベント (+I および +U) は、対応する RETRACT イベント (-D および -U) の前に必ず発生します。同じ upsert キーを持つチェンジログイベントのペアは、データシャッフルが発生した場合でも、同じタスクによって処理されます。SinkUpsertMaterializer は、これらの順序の保証に依存して、正しい結果を再構築します。
この演算子は次のように動作します。
-
導出された upsert キー (upsert キーが空の場合は行全体) をキーとして、
RowData値のリストをステート内で保持します。 -
ADD イベント (
+Iまたは+U): 状態の行を追加または更新します。 -
RETRACT イベント (
-Uまたは-D) では、ステートから行を削除します。 -
シンクテーブルのプライマリキーに基づいて、正しいチェンジログイベントを生成します。
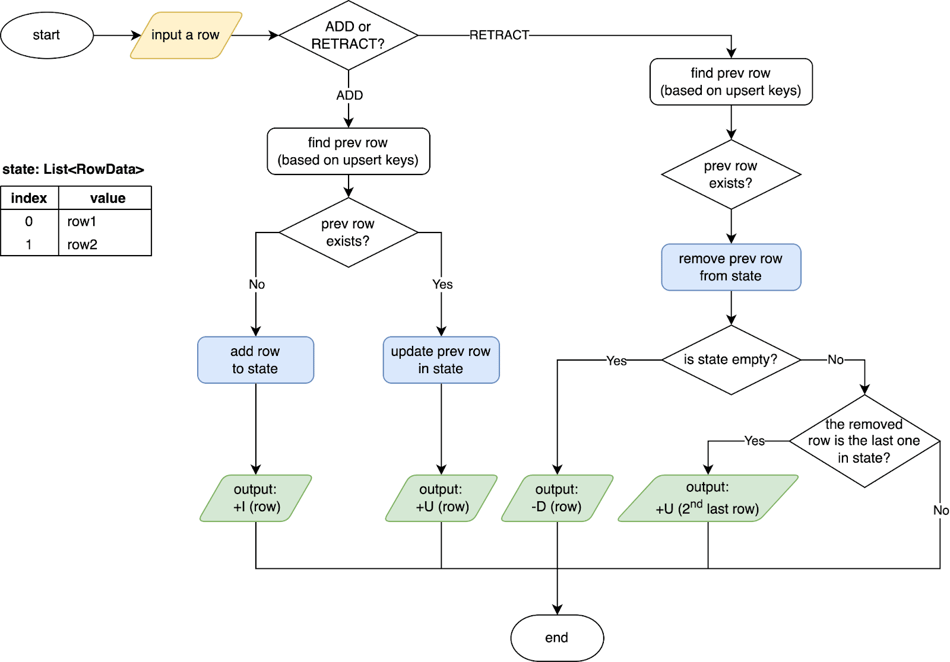
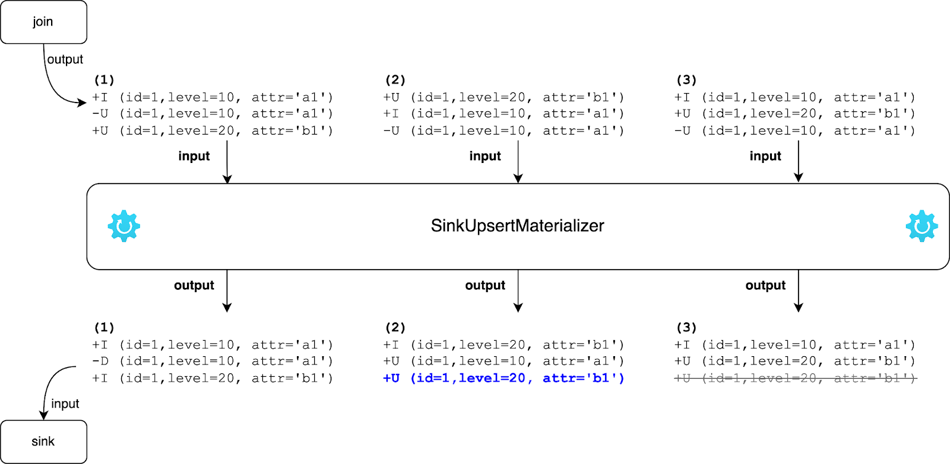
以下の図は、SinkUpsertMaterializer が上記の例のケース 2 とケース 3 をどのように処理するかを示しています。
-
ケース 2:
-U (id=1, level=10, attr='a1')が最後に到着した場合、SinkUpsertMaterializer はその行を state から削除し、最後から 2 番目の行に基づいて UPDATE イベントを生成します。最終結果は(id=1, level=20, attr='b1')になります。 -
ケース 3:
+U (id=1, level=20, attr='b1')が到着すると、オペレーターはそれを下流に渡します。後から-U (id=1, level=10, attr='a1')が到着すると、オペレーターはイベントを発行せずに state から対応する行を削除します。最終的な結果は、再び(id=1, level=20, attr='b1')になります。
ソースコードについては、「SinkUpsertMaterializer (Flink release-1.17)」をご参照ください。
SinkUpsertMaterializerがトリガーされるケース
Flink は、以下のシナリオで SinkUpsertMaterializer 演算子を追加します。
-
シンクテーブルにプライマリキーがあるものの、入力データが UNIQUE 制約を満たさない場合。主な原因は以下のとおりです。
-
ソーステーブルにプライマリキーがないにもかかわらず、シンクテーブルにプライマリキーを定義する場合。
-
シンクに書き込む際にソースのプライマリキー列を除外する場合や、ソースの非プライマリキー列をシンクのプライマリキーにマッピングする場合。
-
型変換やグループ集約によってプライマリキー列の精度が低下する場合 (例:BIGINT から INT へのキャスト)。
-
複数の列を 1 つに連結するなど、プライマリキー列を変換する場合。
CREATE TABLE students ( student_id BIGINT NOT NULL, student_name STRING NOT NULL, course_id BIGINT NOT NULL, score DOUBLE NOT NULL, PRIMARY KEY(student_id) NOT ENFORCED ) WITH (...); CREATE TABLE performance_report ( student_info STRING NOT NULL PRIMARY KEY NOT ENFORCED, avg_score DOUBLE NOT NULL ) WITH (...); CREATE TEMPORARY VIEW v AS SELECT student_id, student_name, AVG(score) AS avg_score FROM students GROUP BY student_id, student_name; -- 連結された結果はもはやUNIQUE制約を満たしませんが、 -- シンクテーブルのプライマリキーとして使用されます。 INSERT INTO performance_report SELECT CONCAT('id:', student_id, ',name:', student_name) AS student_info, avg_score FROM v;
-
-
データシャッフル操作は、シンクテーブルに書き込む前に一意キーのソート順を崩します。上記の join の例では、
levelでの JOIN が s1 の行をシャッフルするため、idプライマリキーのソート順が崩れます。 -
table.exec.sink.upsert-materializeパラメーターはforceに設定されています。
SinkUpsertMaterializerの設定
table.exec.sink.upsert-materialize パラメーターを使用して、Flink が SinkUpsertMaterializer オペレーターを追加するタイミングを制御します:
| 値 | 動作 |
|---|---|
auto (デフォルト) |
Flink は、順序が正しくないイベントが発生する可能性があるかを推測し、必要に応じて演算子を追加します。 |
none |
演算子を完全に無効にします。 |
force |
シンクテーブルにプライマリキーが定義されていない場合でも、常に演算子を追加します。 |
autoを設定しても、イベントの順序が実際に乱れることは保証されません。たとえば、null 値を変換するためにGROUPING SETS句とCOALESCEを使用すると、SQL プランナーが upsert キーと sink プライマリキーが一致するかどうかを判断できなくなる可能性があります。その場合、Flink は予防措置として SinkUpsertMaterializer を追加します。オペレーターがなくても結果が正しい場合は、table.exec.sink.upsert-materializeをnoneに設定してください。
Ververica Runtime (VVR) 6.0 以降を使用する Realtime Compute for Apache Flink でサポートされているクエリ操作、対応するランタイム演算子、および更新ストリームのサポートについては、「クエリの実行」をご参照ください。
パフォーマンスと運用の注意点
SinkUpsertMaterializer は、処理するすべての行の状態を保持します。これにより、状態サイズが増加し、状態の読み書きのための I/O オーバーヘッドが発生し、スループットが低下します。可能な場合は、この演算子の使用を避けてください。
SinkUpsertMaterializerのトリガーを回避する方法
-
重複排除またはグループ集約に使用されるパーティションキーを、シンクテーブルのプライマリキーと一致させてください。
-
単一の並列度がデータセットに適しており、順序が乱れたイベントを回避したい場合は、並列度を 1 に設定し、
table.exec.sink.upsert-materializeをnoneに設定して SinkUpsertMaterializer を無効にします。 -
Sink オペレーターと上流のステートフルオペレーター (重複排除やグループ集計オペレーターなど) の間にオペレーターチェーンが存在し、かつ 6.0 より前の VVR バージョンでデータ精度の問題が発生しなかった場合は、デプロイを VVR 6.0 以降に移行します。
table.exec.sink.upsert-materializeをnoneに設定し、その他の設定は変更しません。移行手順については、「デプロイのエンジンバージョンをアップグレードする」をご参照ください。
SinkUpsertMaterializerを使用する必要がある場合
-
CURRENT_TIMESTAMPやNOW()などの非決定性関数によって生成されたカラムを、シンクテーブルに書き込まないでください。upsert キーが利用できない場合、SinkUpsertMaterializer は行全体を比較します。非決定性の値があると、履歴行の照合と削除が妨げられ、状態が無限に増大する原因となります。 -
演算子の状態がパフォーマンスに影響を与えるほど大きくなった場合は、デプロイメントの並列度を上げてください。「デプロイメントのリソース設定」をご参照ください。
既知の問題
SinkUpsertMaterializer は、以下の状況で状態が無限に増大する可能性があります。
-
状態の TTL がない、長すぎる、または短すぎる場合:Time-to-Live (TTL) が設定されていない場合、状態は無期限に蓄積されます。TTL が短すぎても問題が発生する可能性があります。ADD イベントとそれに対応する DELETE イベントの間隔が設定された TTL を超えると、Flink はその行をダーティデータとして状態に保持し (FLINK-29225 を参照)、次のログメッセージを生成します。
int index = findremoveFirst(values, row); if (index == -1) { LOG.info(STATE_CLEARED_WARN_MSG); return; }ビジネス要件に基づいて TTL を設定してください。「デプロイメントの設定」をご参照ください。VVR 8.0.7 以降を搭載した Realtime Compute for Apache Flink は、大規模な状態を持つデプロイメントのリソース消費を削減するために、演算子ごとの TTL 設定をサポートしています。「演算子の並列度、連鎖戦略、TTLの設定」をご参照ください。
-
アップサートキーがなく、非決定的な列が存在する場合:SinkUpsertMaterializer に到着する更新ストリームに推定可能なアップサートキーがなく、非決定的関数からの列が含まれている場合、履歴行は値で照合できず、決して削除されないため、状態が継続的に増大します。
次のステップ
-
リリースノート:Realtime Compute for Apache Flink と Apache Flink のエンジンバージョンのマッピング
-
クエリの実行:VVR 6.0 以降でサポートされているクエリ操作と更新ストリームのサポート
-
デプロイメントのリソース設定:大規模な SinkUpsertMaterializer の状態を処理するための並列度の向上