このトピックでは、Realtime Compute for Apache Flink におけるジョブ実行エラーに関する一般的な問題とその解決策について説明します。
ジョブの起動失敗に関するトラブルシューティング
問題の説明
[開始] ボタンをクリックした後、ジョブのステータスが [起動中] から [失敗] に変わります。
解決策
[イベント] タブで、
 アイコンをクリックして詳細を展開し、エラーメッセージから原因を特定します。
アイコンをクリックして詳細を展開し、エラーメッセージから原因を特定します。[ログ] タブで、起動ログに例外がないか確認し、提供された情報に基づいて問題をトラブルシューティングします。
JobManager が正常に起動した場合、[ログ] タブで JobManager または TaskManager の詳細なログを表示できます。
一般的なエラー
エラー詳細
原因
解決策
ERROR: exceeded quota: resourcequotaリソースキューのリソースが不足しています。
リソースキューのリソースをアップグレードまたはスペックダウンするか、ジョブの開始に必要なリソースを削減します。
ERROR:the vswitch ip is not enoughプロジェクトで利用可能な IP アドレスの数が、ジョブで必要な TaskManager (TM) の数より少ないです。
並列度を減らす、スロットを適切に設定する、またはワークスペースの vSwitch を変更します。
ERROR: pooler: ***: authentication failedコードで提供された AccessKey が無効であるか、必要な権限がありません。
必要な権限を持つ有効な AccessKey を提供してください。
ページの右側にデータベース接続エラーのポップアップが表示された場合の対処法
詳細

原因
登録済みのカタログが無効で、接続できません。
解決策
[Data Management] ページで、すべてのカタログを表示します。グレーアウトされているカタログを削除し、再度登録してください。
ジョブ実行後にパイプラインのデータが消費されない場合の対処法
ネットワーク接続の確認
アップストリームおよびダウンストリームのコンポーネントがデータを生成または消費していない場合、まず [起動ログ] ページでエラーメッセージを確認します。タイムアウトエラーが報告された場合は、対応するコンポーネントのネットワーク接続をトラブルシューティングしてください。
タスク実行ステータスの確認
[概要] ページで、ソースがデータを送信しているか、シンクがデータを受信しているかを確認し、問題の発生箇所を特定します。

データリンクの詳細な確認
各データリンクにプリント結果テーブルを追加して、問題をトラブルシューティングします。
ジョブ実行後に再起動する場合の対処法
ジョブの [ログ] タブで問題をトラブルシューティングできます:
例外の確認
[例外] タブで、スローされた例外を表示し、提供された情報に基づいて問題をトラブルシューティングします。
JobManager と TaskManager のログの表示

失敗した TaskManager のログの表示
一部の例外は TaskManager の障害を引き起こす可能性があります。新しくスケジュールされた TaskManager のログは不完全な場合があります。以前に失敗した TaskManager のログを表示してトラブルシューティングできます。
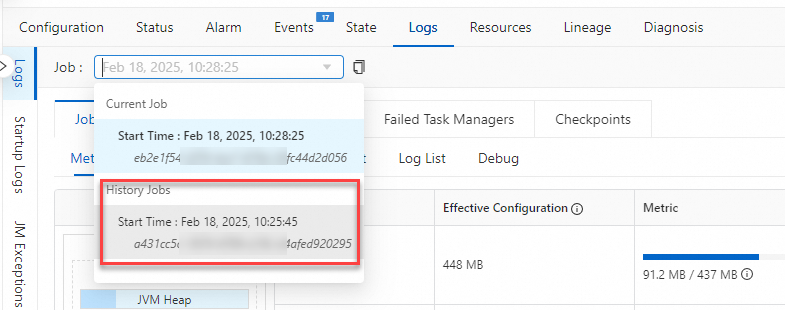
過去のジョブ実行のログの表示
現在のジョブの過去の実行からログを選択して、障害の原因を見つけます。
LocalGroupAggregate ノードでデータが長時間滞留し、出力されない原因
ジョブコード
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts as PROCTIME(), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a BIGINT, b BIGINT ) WITH ( 'connector'='print' ); CREATE TEMPORARY VIEW window_view AS SELECT window_start, window_end, a, sum(b) as b_sum FROM TABLE(TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '2' SECONDS)) GROUP BY window_start, window_end, a; INSERT INTO sink SELECT count(distinct a), b_sum FROM window_view GROUP BY b_sum;問題の説明
データが LocalGroupAggregate ノードで長時間滞留し、出力がなく、MiniBatchAssigner ノードが存在しません。

原因
ジョブに WindowAggregate と GroupAggregate の両方が含まれ、WindowAggregate の時間列が処理時間 (proctime) である場合、
table.exec.mini-batch.sizeパラメーターが設定されていないか、負の値に設定されていると、MiniBatch 処理モードはマネージドメモリを使用してデータをキャッシュします。これにより、MiniBatchAssigner ノードが生成されなくなります。その結果、計算ノードは MinibatchAssigner ノードから計算と出力をトリガーするためのウォーターマークメッセージを受信できません。計算と出力は、マネージドメモリが満杯になる、チェックポイントが発生しようとしている、またはジョブが停止するという 3 つの条件のいずれかが満たされた場合にのみトリガーされます。詳細については、「table.exec.mini-batch.size」をご参照ください。チェックポイント間隔が長すぎると、データが LocalGroupAggregate ノードに蓄積され、長期間出力されません。
解決策
チェックポイント間隔を短くします。これにより、LocalGroupAggregate ノードはチェックポイントが発生する前に自動的に出力をトリガーできます。チェックポイント間隔の設定方法の詳細については、「Tuning Checkpointing」をご参照ください。
ヒープメモリを使用してデータをキャッシュします。これにより、キャッシュされたデータレコード数が N に達したときに、LocalGroupAggregate ノードが自動的に出力をトリガーできます。これを行うには、
table.exec.mini-batch.sizeパラメーターを正の値 N に設定します。パラメーター設定の詳細については、「カスタムジョブ実行パラメーターの設定方法」をご参照ください。
アップストリームコネクタのパーティションがデータを受信せず、ウォーターマークが停滞し、ウィンドウの出力が遅延する場合の対処法
たとえば、5 つのパーティションを持つ Kafka ソースを考えます。毎分 2 つの新しいレコードが到着しますが、すべてのパーティションがリアルタイムでデータを受信するわけではありません。ソースがタイムアウト期間内に要素を受信しない場合、一時的にアイドル状態としてマークされます。その結果、ウォーターマークが進まず、ウィンドウが迅速に閉じられず、結果がリアルタイムで出力されません。
この場合、生存時間 (TTL) を設定して、パーティションにデータがないことを示すことができます。これにより、パーティションはウォーターマークの計算から除外されます。データが到着すると、パーティションは再び計算に含まれます。詳細については、「Configuration」をご参照ください。
[追加構成] セクションで、次のコードを追加します。詳細については、「カスタムジョブ実行パラメーターの設定方法」をご参照ください。
table.exec.source.idle-timeout: 1sJobManager が実行されていない場合に問題を迅速に特定する方法
JobManager が実行されていない場合、[Flink UI] ページにアクセスできません。この場合、次の手順を実行して障害の原因を特定できます:
ページで、対象のジョブ名をクリックします。
[イベント] タブをクリックします。
キーボードショートカットを使用して「error」を検索し、例外情報を取得します。
Windows: Ctrl+F
macOS: Command+F

INFO: org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss
エラー詳細

原因
ストレージクラスが [OSS バケット] です。OSS が新しいフォルダを作成する際、まずフォルダが存在するかどうかを確認します。フォルダが存在しない場合、この INFO メッセージが報告されます。このメッセージは Flink ジョブに影響しません。
解決策
ログテンプレートに
<Logger level="ERROR" name="org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss"/>を追加します。詳細については、「ジョブログ出力の設定」をご参照ください。
エラー: akka.pattern.AskTimeoutException
原因
JobManager または TaskManager のメモリ不足により、継続的なガベージコレクション (GC) が発生します。これにより、JobManager と TaskManager 間のハートビートおよびリモートプロシージャコール (RPC) リクエストがタイムアウトします。
ジョブが大規模であるため、RPC リクエストの量が多くなります。しかし、JobManager のリソースが不足しているため、RPC リクエストが滞留します。これにより、JobManager と TaskManager 間のハートビートおよび RPC リクエストがタイムアウトします。
ジョブのタイムアウトパラメーターが小さい値に設定されています。サードパーティ製品への接続に失敗すると、システムは接続を複数回リトライします。これにより、タイムアウトに達する前に接続失敗エラーがスローされなくなります。
解決策
エラーが継続的な GC によって引き起こされている場合は、ジョブのメモリ使用量と GC ログに基づいて、GC の消費時間と頻度を確認します。高頻度の GC または長い GC 時間が見つかった場合は、JobManager と TaskManager のメモリを増やしてください。
エラーが大規模なジョブによって引き起こされている場合は、JobManager の CPU とメモリリソースを増やしてください。また、
akka.ask.timeoutおよびheartbeat.timeoutパラメーターの値を増やすこともできます。重要これらの 2 つのパラメーターは、大規模なジョブの場合にのみ調整することを推奨します。小規模なジョブの場合、このエラーは通常、パラメーター値が小さいことが原因ではありません。
これらのパラメーターは必要に応じて設定してください。値が大きすぎると、TaskManager が予期せず終了した場合にジョブの回復時間が増加します。
タイムアウトがサードパーティ製品への接続失敗によって引き起こされている場合は、まず次の 4 つのパラメーターの値を増やして、サードパーティのエラーがスローされるようにします。その後、サードパーティのエラーを解決できます。
client.timeout: デフォルト: 60 s。推奨: 600 s。akka.ask.timeout: デフォルト: 10 s。推奨: 600 s。client.heartbeat.timeout: デフォルト: 180000 s。推奨: 600000 s。値を入力する際は、単位を含めないでください。単位を含めると、起動エラーが発生する可能性があります。例:client.heartbeat.timeout: 600000と入力します。heartbeat.timeout: デフォルト: 50000 ms。推奨: 600000 ms。値を入力する際は、単位を含めないでください。単位を含めると、起動エラーが発生する可能性があります。例:heartbeat.timeout: 600000と入力します。
たとえば、エラー
Caused by: java.sql.SQLTransientConnectionException: connection-pool-xxx.mysql.rds.aliyuncs.com:3306 - Connection is not available, request timed out after 30000msは、MySQL 接続プールが満杯であることを示します。MySQL の WITH オプションでconnection.pool.sizeパラメーターの値を増やす必要があります。デフォルト値は 20 です。説明前述のパラメーターの最小値は、タイムアウトエラーメッセージに基づいて決定できます。たとえば、
pattern.AskTimeoutException: Ask timed out on [Actor[akka://flink/user/rpc/dispatcher_1#1064915964]] after [60000 ms].では、60000 ms はclient.timeoutの現在の値です。
エラー: Task did not exit gracefully within 180 + seconds.
エラー詳細
Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852861506+08:00 stdout F org.apache.flink.util.FlinkRuntimeException: Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852865065+08:00 stdout F at org.apache.flink.runtime.taskmanager.Task$TaskCancelerWatchDog.run(Task.java:1709) [flink-dist_2.11-1.12-vvr-3.0.4-SNAPSHOT.jar:1.12-vvr-3.0.4-SNAPSHOT] 2022-04-22T17:32:25.852867996+08:00 stdout F at java.lang.Thread.run(Thread.java:834) [?:1.8.0_102] // ログレベル:エラー log_level:ERROR原因
このエラーは、ジョブ例外の根本原因ではありません。
task.cancellation.timeoutパラメーター (タスクが終了するまでのタイムアウトを指定) のデフォルト値は 180 秒です。ジョブのフェールオーバーまたは終了プロセス中に、タスクの終了が何らかの理由でブロックされることがあります。ブロック時間がタイムアウトに達すると、Flink はタスクがスタックして回復できないと判断します。その後、Flink はタスクが配置されている TaskManager を能動的に停止し、フェールオーバーまたは終了プロセスを続行させます。これが、このエラーがログに表示される理由です。実際の原因は、ユーザー定義関数 (UDF) の実装に問題がある可能性があります。たとえば、close メソッドでの長時間のブロックや、長時間戻らない計算メソッドなどです。
解決策
task.cancellation.timeoutパラメーターを 0 に設定します。このパラメーターの設定方法の詳細については、「カスタムジョブ実行パラメーターの設定方法」をご参照ください。値が 0 の場合、ブロックされたタスクの終了はタイムアウトせず、タスクは終了が完了するまで無期限に待機します。ジョブを再起動した後、フェールオーバーまたは終了中にジョブが長時間ブロックされていることが再度判明した場合は、Cancelling 状態のタスクを見つけます。タスクのスタックを確認して根本原因を調査し、それに応じて問題を解決してください。重要task.cancellation.timeoutパラメーターはジョブのデバッグに使用されます。本番ジョブではこのパラメーターを 0 に設定しないでください。
エラー: 存在しないレコードを撤回できません。このエラーは発生しないはずです。
エラー詳細
java.lang.RuntimeException: Can not retract a non-existent record. This should never happen. at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:196) at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:55) at org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:135) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:106) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:424) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:685) at org.apache.flink.streaming.runtime.tasks.StreamTask.executeInvoke(StreamTask.java:640) at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:651) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:624) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:799) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:586) at java.lang.Thread.run(Thread.java:877)原因と解決策
シナリオ
原因
解決策
シナリオ 1
コード内の
now()関数が原因です。TopN は、ORDER BY または PARTITION BY 句で非決定的なフィールドをサポートしていません。
now()関数は毎回異なる値を返すため、リトラクションで前の値を見つけることができません。ORDER BY および PARTITION BY 句には、決定的な値のみを生成するソーステーブルのフィールドを使用してください。
シナリオ 2
table.exec.state.ttlパラメーターの値が小さすぎます。状態は期限切れになるとクリアされ、リトラクション中に対応するキーステートが見つかりません。table.exec.state.ttlパラメーターの値を増やしてください。このパラメーターの設定方法の詳細については、「カスタムジョブ実行パラメーターの設定方法」をご参照ください。
エラー: SQL Server で gRPC 呼び出しがタイムアウトしました
エラー詳細
org.apache.flink.table.sqlserver.utils.ExecutionTimeoutException: The GRPC call timed out in sqlserver, please check the thread stacktrace for root cause: // sqlserver で GRPC 呼び出しがタイムアウトしました。根本原因については、スレッドスタックトレースを確認してください。 Thread name: sqlserver-operation-pool-thread-4, thread state: TIMED_WAITING, thread stacktrace: // スレッド名:sqlserver-operation-pool-thread-4、スレッド状態:TIMED_WAITING、スレッドスタックトレース: at java.lang.Thread.sleep0(Native Method) at java.lang.Thread.sleep(Thread.java:360) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.processWaitTimeAndRetryInfo(RetryInvocationHandler.java:130) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:107) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy195.getFileInfo(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1661) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1577) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1574) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1589) at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1683) at org.apache.flink.connectors.hive.HiveSourceFileEnumerator.getNumFiles(HiveSourceFileEnumerator.java:118) at org.apache.flink.connectors.hive.HiveTableSource.lambda$getDataStream$0(HiveTableSource.java:209) at org.apache.flink.connectors.hive.HiveTableSource$$Lambda$972/1139330351.get(Unknown Source) at org.apache.flink.connectors.hive.HiveParallelismInference.logRunningTime(HiveParallelismInference.java:118) at org.apache.flink.connectors.hive.HiveParallelismInference.infer(HiveParallelismInference.java:100) at org.apache.flink.connectors.hive.HiveTableSource.getDataStream(HiveTableSource.java:207) at org.apache.flink.connectors.hive.HiveTableSource$1.produceDataStream(HiveTableSource.java:123) at org.apache.flink.table.planner.plan.nodes.exec.common.CommonExecTableSourceScan.translateToPlanInternal(CommonExecTableSourceScan.java:127) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecExchange.translateToPlanInternal(StreamExecExchange.java:87) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecGroupAggregate.translateToPlanInternal(StreamExecGroupAggregate.java:148) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.java:108) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:74) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:73) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at org.apache.flink.table.planner.delegation.StreamPlanner.translateToPlan(StreamPlanner.scala:73) at org.apache.flink.table.planner.delegation.StreamExecutor.createStreamGraph(StreamExecutor.java:52) at org.apache.flink.table.planner.delegation.PlannerBase.createStreamGraph(PlannerBase.scala:610) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraphInternal(StreamPlanner.scala:166) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraph(StreamPlanner.scala:159) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:304) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:288) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$validate$22(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$394/1626790418.run(Unknown Source) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapClassLoader(DelegateOperationExecutor.java:250) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$wrapExecutor$26(DelegateOperationExecutor.java:275) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$395/1157752141.run(Unknown Source) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:281) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:786) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522) at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172) at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331) at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820) at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37) at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) Caused by: java.util.concurrent.TimeoutException // タイムアウトの例外 at java.util.concurrent.FutureTask.get(FutureTask.java:205) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:277) ... 11 more原因
SQL 文が過度に複雑な場合、タイムアウト例外が発生する可能性があります。
解決策
[追加構成] セクションで、次のコードを追加して、デフォルトの 120 秒のタイムアウト制限を増やします。詳細については、「カスタムジョブ実行パラメーターの設定方法」をご参照ください。
flink.sqlserver.rpc.execution.timeout: 600s
エラー: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051
エラー詳細
Caused by: io.grpc.StatusRuntimeException: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051 at io.grpc.stub.ClientCalls.toStatusRuntimeException(ClientCalls.java:244) at io.grpc.stub.ClientCalls.getUnchecked(ClientCalls.java:225) at io.grpc.stub.ClientCalls.blockingUnaryCall(ClientCalls.java:142) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$FlinkSqlServiceBlockingStub.generateJobGraph(FlinkSqlServiceGrpc.java:2478) at org.apache.flink.table.sqlserver.api.client.FlinkSqlServerProtoClientImpl.generateJobGraph(FlinkSqlServerProtoClientImpl.java:456) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.lambda$generateJobGraph$25(ErrorHandlingProtoClient.java:251) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.invokeRequest(ErrorHandlingProtoClient.java:335) ... 6 more Cause: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051)原因
ジョブのロジックが非常に複雑で、生成される JobGraph が大きすぎます。これにより、検証エラーが発生したり、ジョブが起動またはシャットダウン中にスタックしたりする可能性があります。
解決策
[追加構成] セクションで、次のコードを追加します。詳細については、「カスタムジョブ実行パラメーターの設定方法」をご参照ください。
table.exec.operator-name.max-length: 1000
エラー: Caused by: java.lang.NoSuchMethodError
エラー詳細
Error: Caused by: java.lang.NoSuchMethodError: org.apache.flink.table.planner.plan.metadata.FlinkRelMetadataQuery.getUpsertKeysInKeyGroupRange(Lorg/apache/calcite/rel/RelNode;[I)Ljava/util/Set原因
コミュニティの内部 API に依存しており、Alibaba Cloud 上のこの API のバージョンが最適化されている場合、パッケージの競合などの例外が発生する可能性があります。
解決策
Flink のソースコードでは、@Public または @PublicEvolving で明示的に注釈が付けられたメソッドのみが、呼び出し可能なパブリック API です。Alibaba Cloud は、これらのメソッドに対してのみ互換性を保証します。
エラー: java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory
エラー詳細
Causedby:java.lang.ClassCastException:org.codehaus.janino.CompilerFactorycannotbecasttoorg.codehaus.commons.compiler.ICompilerFactory atorg.codehaus.commons.compiler.CompilerFactoryFactory.getCompilerFactory(CompilerFactoryFactory.java:129) atorg.codehaus.commons.compiler.CompilerFactoryFactory.getDefaultCompilerFactory(CompilerFactoryFactory.java:79) atorg.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:426) ...66more原因
JAR パッケージに競合する janino 依存関係が含まれています。
ユーザー定義関数 (UDF) の JAR またはコネクタの JAR に、flink-table-planner や flink-table-runtime など、
flink-で始まる JAR が含まれています。
解決策
JAR パッケージに org.codehaus.janino.CompilerFactory が含まれているかどうかを分析します。クラスの読み込み順序がマシンによって異なるため、クラスの競合が発生する可能性があります。この問題を解決するには、次の手順を実行します:
ページで、対象のジョブの名前をクリックします。
[デプロイメント詳細] タブで、[実行パラメーター設定] セクションの右側にある [編集] をクリックします。
[追加構成] テキストボックスに次のパラメーターを入力し、[保存] をクリックします。
classloader.parent-first-patterns.additional: org.codehaus.janinoパラメーターの値を競合するクラスに置き換えます。
Flink 関連の依存関係のスコープを、
<scope>provided</scope>を追加して `provided` に設定します。これは主に、org.apache.flinkグループ内のflink-で始まる非コネクタ依存関係に適用されます。