時系列データが蓄積されるにつれて、ストレージコストはデータ量に比例して線形に増加します。Elasticsearch のロールアップ機構では、元のストレージコストの一部で履歴データをコンパクトな集約結果にまとめることができ、同時に Kibana を通じた集約クエリもサポートします。
本チュートリアルでは、Logstash トラフィック監視データを対象とした一連のロールアップワークフローを説明します。具体的には、ロールアップタスクの作成、ロールアップインデックスへのクエリ実行、およびインスタンス ID 単位・時間単位の粒度で networkoutTraffic および networkinTraffic メトリックを可視化する Kibana ダッシュボードの構築手順について解説します。
本チュートリアルで使用するコマンドは Elasticsearch V7.4 に対応しています。V6.x 向けのコマンドについては、「ロールアップの概要」をご参照ください。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
manageまたはmanage_rollup権限を有していること。詳細については、「セキュリティ権限」をご参照ください。Alibaba Cloud Elasticsearch V7.4 インスタンス(Standard Edition)が実行中であること。インスタンスの作成方法については、「Alibaba Cloud Elasticsearch クラスターの作成」をご参照ください。
Kibana コンソールへのアクセスができること。アクセス手順については、「Kibana コンソールへのログイン」をご参照ください。
本チュートリアルで紹介するすべての API コマンドは、Kibana コンソールから実行してください。
背景情報
本チュートリアルで使用するソースインデックスの名前は、monitordata-logstash-sls-* のパターンに従います。ここで * は YYYY-MM-DD 形式の日付です。新しいインデックスは毎日作成されます。
インデックスマッピングは以下のとおりです。
"monitordata-logstash-sls-2020-04-05" : {
"mappings" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"__source__" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"disk_type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"host" : {
"type" : "keyword"
},
"instanceId" : {
"type" : "keyword"
},
"metricName" : {
"type" : "keyword"
},
"monitor_type" : {
"type" : "keyword"
},
"networkinTraffic" : {
"type" : "double"
},
"networkoutTraffic" : {
"type" : "double"
},
"node_spec" : {
"type" : "keyword"
},
"node_stats_node_master" : {
"type" : "keyword"
},
"resource_uid" : {
"type" : "keyword"
}
}
}
}
}ステップ 1:ロールアップタスクの作成
ロールアップタスクでは、集約対象のソースインデックス、グループ化対象のフィールド、計算対象のメトリック、および実行頻度を定義します。
以下のタスクでは、monitordata-logstash-sls-* からデータを読み込み、時間単位およびインスタンス ID 単位でデータをグループ化し、各トラフィックフィールドの合計値を計算します。また、15 分ごとに実行されます。
PUT _rollup/job/ls-monitordata-sls-1h-job1
{
"index_pattern": "monitordata-logstash-sls-*",
"rollup_index": "monitordata-logstash-rollup-1h-1",
"cron": "0 */15 * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1h"
},
"terms": {
"fields": ["instanceId"]
}
},
"metrics": [
{
"field": "networkoutTraffic",
"metrics": ["sum"]
},
{
"field": "networkinTraffic",
"metrics": ["sum"]
}
]
}パラメーター:
| パラメーター | 必須 | 型 | 説明 |
|---|---|---|---|
index_pattern | はい | 文字列 | ソースインデックスまたはインデックスパターン。ワイルドカード (*) を使用できます。 |
rollup_index | はい | 文字列 | ロールアップ集約結果の送信先インデックス。完全な名前を指定する必要があります。ワイルドカードは使用できません。 |
cron | はい | 文字列 | ロールアップタスクの実行頻度。これはタスクの実行間隔を制御するものであり、集約の粒度を制御するものではありません。 |
page_size | はい | 整数 | 1 回の反復処理で処理されるバケット結果の数。値を大きくすると処理速度が向上しますが、メモリ使用量も増加します。 |
groups | はい | オブジェクト | グループ化フィールドおよび集約方法を定義します。 |
groups.date_histogram | はい | オブジェクト | 日付フィールドを時間単位のバケットにグループ化します。 |
groups.date_histogram.field | はい | 文字列 | 集約対象の日付フィールド。 |
groups.date_histogram.fixed_interval | はい | 時間単位 | 集約の粒度。1h は 1 時間単位のバケットにデータをグループ化します。これはロールアップインデックスでサポートされる最小クエリ間隔です。 |
groups.terms | いいえ | オブジェクト | 指定されたタームフィールドでグループ化します。 |
groups.terms.fields | はい | 文字列 | グループ化対象のフィールド。任意の順序で keyword 型または数値型フィールドを指定できます。 |
metrics | いいえ | オブジェクト | 集約対象の数値フィールドを定義します。 |
metrics[].field | はい | 文字列 | 集約対象のフィールド。 |
metrics[].metrics | はい | 配列 | 適用する集約演算子:min、max、sum、avg、または value_count。 |
パラメーターの全リファレンスについては、「ロールアップタスクの作成 API」をご参照ください。
構成ルール:
index_patternとrollup_indexは異なる名前を指定する必要があります。index_patternがワイルドカードで、そのパターンがrollup_indexと一致する場合、API はエラーを返します。rollup_indexのマッピングにはオブジェクトタイプを使用します。index_patternと同じ値を設定するとエラーになります。ロールアップタスクでは、日付ヒストグラム集約、ヒストグラム集約、およびターム集約のみがサポートされています。詳細については、「ロールアップ集約の制限事項」をご参照ください。
ステップ 2:ロールアップタスクの開始とステータス確認
ロールアップタスクを開始します。
POST _rollup/job/ls-monitordata-sls-1h-job1/_startタスクの構成、統計情報、および現在のステータスを取得します。
GET _rollup/job/ls-monitordata-sls-1h-job1/応答スキーマの全仕様については、「ロールアップタスクの取得 API」をご参照ください。正常な応答例は以下のとおりです。
{ ........ "status" : { "job_state" : "indexing", "current_position" : { "@timestamp.date_histogram" : 1586775600000, "instanceId.terms" : "ls-cn-ddddez****" }, "upgraded_doc_id" : true }, "stats" : { "pages_processed" : 3, "documents_processed" : 11472500, "rollups_indexed" : 3000, "trigger_count" : 1, "index_time_in_ms" : 766, "index_total" : 3, "index_failures" : 0, "search_time_in_ms" : 68559, "search_total" : 3, "search_failures" : 0 } }
ステップ 3:ロールアップインデックスへのクエリ実行
ロールアップドキュメントは、生データとは異なる内部構造を持ちます。ロールアップインデックスに対してクエリを実行すると、Elasticsearch はクエリ DSL をロールアップ形式に書き換え、その後クライアントが期待する形式で結果を復元します。
ロールアップインデックス内のすべてのドキュメントを取得します。
GET monitordata-logstash-rollup-1h-1/_search { "query": { "match_all": {} } }_rollup_searchを使用してnetworkoutTrafficの合計値を計算します。GET /monitordata-logstash-rollup-1h-1/_rollup_search { "size": 0, "aggregations": { "sum_temperature": { "sum": { "field": "networkoutTraffic" } } } }
_rollup_search では、標準検索機能のサブセットがサポートされています。
| 機能 | サポート | 備考 |
|---|---|---|
query | サポート | 制限付きのクエリ DSL。サポートされるタイプ:term、terms、range、match_all、および複合クエリ(ブール値、ブースティング、定数スコア)。 |
| 集計 | サポート | 標準の集約パラメーター。 |
size | 0 のみ、または省略必須 | ロールアップは集約専用であり、生のドキュメントは返されません。 |
highlighter、suggestors、post_filter、profile、explain | 非サポート | — |
制限事項の全リストについては、「ロールアップ検索の制限事項」および「ロールアップ集約の制限事項」をご参照ください。
クエリ制限事項:
1 回のクエリで指定できるロールアップインデックスは 1 つだけです。ロールアップインデックス名のあいまい一致はサポートされていません。リアルタイムデータのクエリでは複数のインデックスを指定できます。
ステップ 4:ロールアップインデックスパターンの作成
Kibana でロールアップデータを可視化する前に、Kibana がロールアップインデックスを認識できるよう、ロールアップインデックスパターンを作成します。
Kibana コンソールにログインします。ログイン手順については、「Kibana コンソールへのログイン」をご参照ください。
左側ナビゲーションウィンドウで、管理 アイコンをクリックします。
Kibana エリアで、インデックスパターン をクリックします。
任意: インデックスパターンについて ページを閉じます。以前にインデックスパターンを作成済みの場合は、このステップをスキップできます。
インデックスパターンの作成 > ロールアップインデックスパターン を選択します。
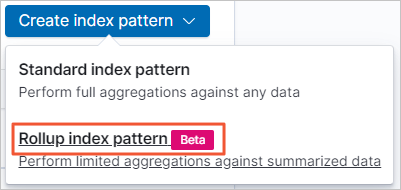
インデックスパターン フィールドにロールアップインデックス名(例:
monitordata-logstash-rollup-1h-1)を入力し、次のステップ をクリックします。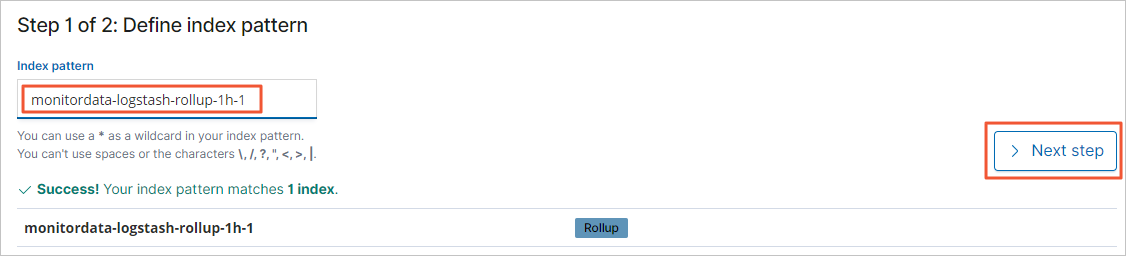
タイムフィルターのフィールド名 のドロップダウンリストから、@timestamp を選択します。
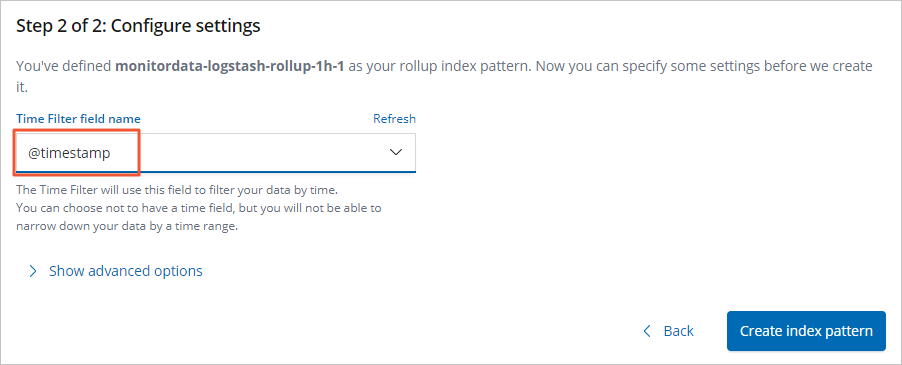
インデックスパターンの作成 をクリックします。
ステップ 5:トラフィック監視チャートの作成
ロールアップインデックスパターンを使用して、networkinTraffic および networkoutTraffic の折れ線グラフを作成します。
Kibana コンソールにログインします。ログイン手順については、「Kibana コンソールへのログイン」をご参照ください。
折れ線グラフを作成します。
左側ナビゲーションウィンドウで、可視化 アイコンをクリックします。
新しい可視化の作成 をクリックします。
新しい可視化 ダイアログボックスで、折れ線グラフ をクリックします。
インデックスパターン一覧から、ステップ 4 で作成したロールアップインデックスパターンを選択します。
メトリックス および バケット の設定を構成します。
メトリックス セクションで、Y 軸のドロップダウン矢印
 をクリックします。
をクリックします。Y 軸のパラメーターを設定します。
パラメーター 値 集約 合計 フィールド networkinTrafficまたはnetworkoutTrafficカスタムラベル Y 軸のラベルを入力します バケット セクションで、追加 > X 軸 を選択します。
X 軸のパラメーターを設定します。
パラメーター 値 集約 date_histogram(ステップ 1 のgroupsで定義)フィールド @timestamp最小間隔 ロールアップ間隔の整数倍(例: 2hまたは3h)。デフォルト値は、ロールアップタスクで設定した集約粒度です。変更の適用 アイコン
 をクリックします。
をクリックします。
上部ナビゲーションバーで、保存 をクリックします。
上記の手順を繰り返して、ゲージチャートを作成します。
ステップ 6:トラフィック監視ダッシュボードの作成
左側ナビゲーションウィンドウで、ダッシュボード アイコンをクリックします。
新しいダッシュボードの作成 をクリックします。
上部ナビゲーションバーで、追加 をクリックします。
パネルの追加 ページで、ステップ 5 で作成したチャートをクリックします。
パネルの追加 ページを閉じ、上部ナビゲーションバーで 保存 をクリックします。
ダッシュボード名を入力し、保存の確認 をクリックします。これでダッシュボードが表示されます。
+ フィルターの追加 をクリックし、フィルター項目を選択してフィルター条件を構成し、保存 をクリックします。