Elasticsearch クラスターで、ハードウェア障害、ソフトウェアエラー、データセンター障害、または自然災害によるサービス中断などの壊滅的なイベントが発生した場合、クラスター間レプリケーション (CCR) 機能を使用して、リージョン間またはリソース間のディザスタリカバリを実装できます。このトピックでは、新しいネットワークアーキテクチャと元のネットワークアーキテクチャの両方で CCR を実装する方法について説明します。
背景情報
CCR は、Platinum エディションのオープンソース Elasticsearch でリリースされた商用機能です。Alibaba Cloud Elasticsearch クラスターを購入し、いくつかの簡単な構成を行うと、この機能を無料で利用できます。
ディザスタリカバリシナリオで CCR を使用して、同じ VPC (virtual private cloud) 内の異なるゾーンに存在する Elasticsearch クラスター間でデータをバックアップできます。クラスター (リモートクラスター) に障害が発生した場合、別のクラスター (ローカルクラスター) からデータを取得し、リモートクラスターにデータを復元できます。この機能は、データ損失を防ぐのに役立ちます。
CCR を使用するには、ローカルクラスターとリモートクラスターの 2 種類のクラスターを準備する必要があります。リモートクラスターはソースデータを提供し、リーダーインデックスに保存されます。ローカルクラスターはデータをレプリケートし、フォロワーインデックスに保存します。CCR を使用して、一度に大量のデータを移行することもできます。詳細については、「クラスター間レプリケーション」をご参照ください。
シナリオ
ビジネスシナリオに基づいてソリューションを選択してください:
環境 | ソリューション |
2 つの Alibaba Cloud Elasticsearch クラスターが新しいネットワークアーキテクチャにデプロイされています。 説明 V7.7 以降の Alibaba Cloud Elasticsearch クラスターのみがサポートされています。 | |
2 つの Alibaba Cloud Elasticsearch クラスターが元のネットワークアーキテクチャにデプロイされ、同じ VPC 内に存在します。 説明 V6.7.0 以降の単一ゾーンの Alibaba Cloud Elasticsearch クラスターのみがサポートされています。 |
前述の使用シナリオは、クラスター間検索 (CCS) 機能にも適用されます。詳細については、「modules-cross-cluster-search」をご参照ください。
CCR 機能は、Alibaba Cloud Elasticsearch クラスターとセルフマネージド Elasticsearch クラスター間のデータのバックアップには使用できません。
2020 年 10 月より前に作成された Alibaba Cloud Elasticsearch クラスターは、元のネットワークアーキテクチャにデプロイされます。2020 年 10 月以降に作成された Alibaba Cloud Elasticsearch クラスターは、新しいネットワークアーキテクチャにデプロイされます。
NLB と PrivateLink を使用した CCR の実装
準備
同じリージョンとゾーンに V7.7 以降の Alibaba Cloud Elasticsearch クラスターを 2 つ作成します。
説明2 つのクラスターは次のように使用されます:
1 つはリモートクラスターとして使用され、ソースデータを提供します。
もう 1 つはローカルクラスターとして使用され、リモートクラスター内の 1 つ以上のインデックスからデータをレプリケートします。
2 つのクラスター間にプライベート接続を確立します。詳細については、「NLB と PrivateLink を使用して Alibaba Cloud Elasticsearch クラスター間にプライベート接続を確立する」をご参照ください。
説明リモートクラスターのプライベート IP アドレスを Network Load Balancer (NLB) サーバーグループに追加して、2 つのクラスター間にプライベート接続を確立します。
リモートクラスターにインデックス (リーダーインデックス) を作成します。
リモートクラスターの Kibana コンソールにログインします。詳細については、「Kibana コンソールにログインする」をご参照ください。
表示されたページで、左上隅の
 アイコンをクリックし、[Management] >[Dev Tools]) を選択します。
アイコンをクリックし、[Management] >[Dev Tools]) を選択します。次のコマンドを実行して、リモートクラスターにリーダーインデックスを作成します:
PUT /leader-new { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" } } } }
シナリオ 1: 特定のインデックスに CCR を実装する
ステップ 1: リモートクラスターをローカルクラスターに接続する
ローカルクラスターの Kibana コンソールにログインします。詳細については、「Kibana コンソールにログインする」をご参照ください。
表示されたページで、左上隅の
アイコンをクリックし、 を選択します。[Management] ページの左側のナビゲーションウィンドウで、[Remote Clusters] をクリックします。
[Add A Remote Cluster] をクリックします。
表示されたページで、リモートクラスターに関する情報を指定します。
[Name]: リモートクラスターの名前。名前は一意である必要があります。
[Connection Mode]: [Use Proxy Mode] をオンにします。
[Proxy Address]: プロキシサーバーのアドレス。アドレスは
エンドポイントドメイン名:9300形式である必要があります。エンドポイントドメイン名は、PrivateLink エンドポイントサービスに対応するエンドポイントのドメイン名です。説明CCR 中、Kibana はデータノードの IP アドレスを使用して TCP ポート 9300 経由でクラスターにアクセスします。HTTP ポート 9200 はサポートされていません。
[Save] をクリックします。
保存後、システムは自動的にリーダー クラスターに接続します。接続が成功すると、接続ステータスに [Connected] (接続済み). と表示されます。
API 使用例
PUT /_cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"<remote_cluster>": {
"mode": "PROXY",
"proxy_address": "Endpoint domain name:9300"
}
}
}
}
}パラメーター | 説明 |
persistent | クラスターが再起動されても設定が永続的に保存されるように指定します。 |
<remote_cluster> | リモートクラスターの名前に置き換えます。 |
mode | プロキシモードのみがサポートされています。ローカルクラスターは、設定されたプロキシアドレスを使用してリモートクラスターにアクセスします。リモートクラスターへのすべてのリクエストは、このプロキシアドレスに送信され、プロキシサーバーによってリモートクラスター内の適切なノードに転送されます。 |
proxy_address | プロキシサーバーのアドレス。アドレスは 説明 この例では、CCR または CCS は Elasticsearch のトランスポートレイヤーを使用し、通信にはポート 9300 を使用する必要があります。 |
ステップ 2: CCR の構成
ローカルクラスターの Kibana コンソールの [Management] ページに移動します。左側のナビゲーションウィンドウで、[Cross-Cluster Replication] をクリックします。
[Create A Follower Index] をクリックします。
CCR を構成します。
パラメーター
説明
リモートクラスター
ローカルクラスターに接続されているリモートクラスター。
リーダーインデックス
移行されるインデックス。
フォロワーインデックス
データをバックアップするインデックス。一意のインデックス名を指定する必要があります。
[Create] をクリックします。
フォロワーインデックスが作成されると、インデックスは [Active] 状態になります。
API 使用例
フォロワーインデックスを作成するときは、リモートクラスターと、リモートクラスターで作成されたリーダーインデックスを参照する必要があります。
このトピックのコードは参照用です。コードを使用するときは、クラスターとインデックスの名前を独自のものに置き換えてください。
# 例: leader-new-copy は、リモートクラスターのリーダーインデックスからレプリケートされたデータを受信するためにローカルクラスターに作成されたフォロワーインデックスの名前です。
PUT /leader-new-copy/_ccr/follow
{
"remote_cluster": "es-leader",
"leader_index": "leader-old"
}パラメーター | 説明 |
remote_cluster | ローカルクラスターに接続されているリモートクラスターの名前。このパラメーターは、ステップ 1 の |
leader_index | リーダーインデックスの名前。このパラメーターは、リモートクラスター内のどのインデックスを使用してデータをレプリケートするかを制御します。 |
ステップ 3: データバックアップ結果の確認
リモートクラスターの Kibana コンソールで、次のコマンドを実行してリーダーインデックスにデータを挿入します:
POST leader-new/_doc/ { "name":"Jack", "age":40 }ローカルクラスターの Kibana コンソールで、次のコマンドを実行して、挿入されたデータがフォロワーインデックスにバックアップされているかどうかを確認します:
GET leader-new-copy/_search次の図に示す結果が返されます。この結果は、リモートクラスターのリーダーインデックス leader-new のデータが、ローカルクラスターのフォロワーインデックス leader-new-copy にバックアップされていることを示しています。
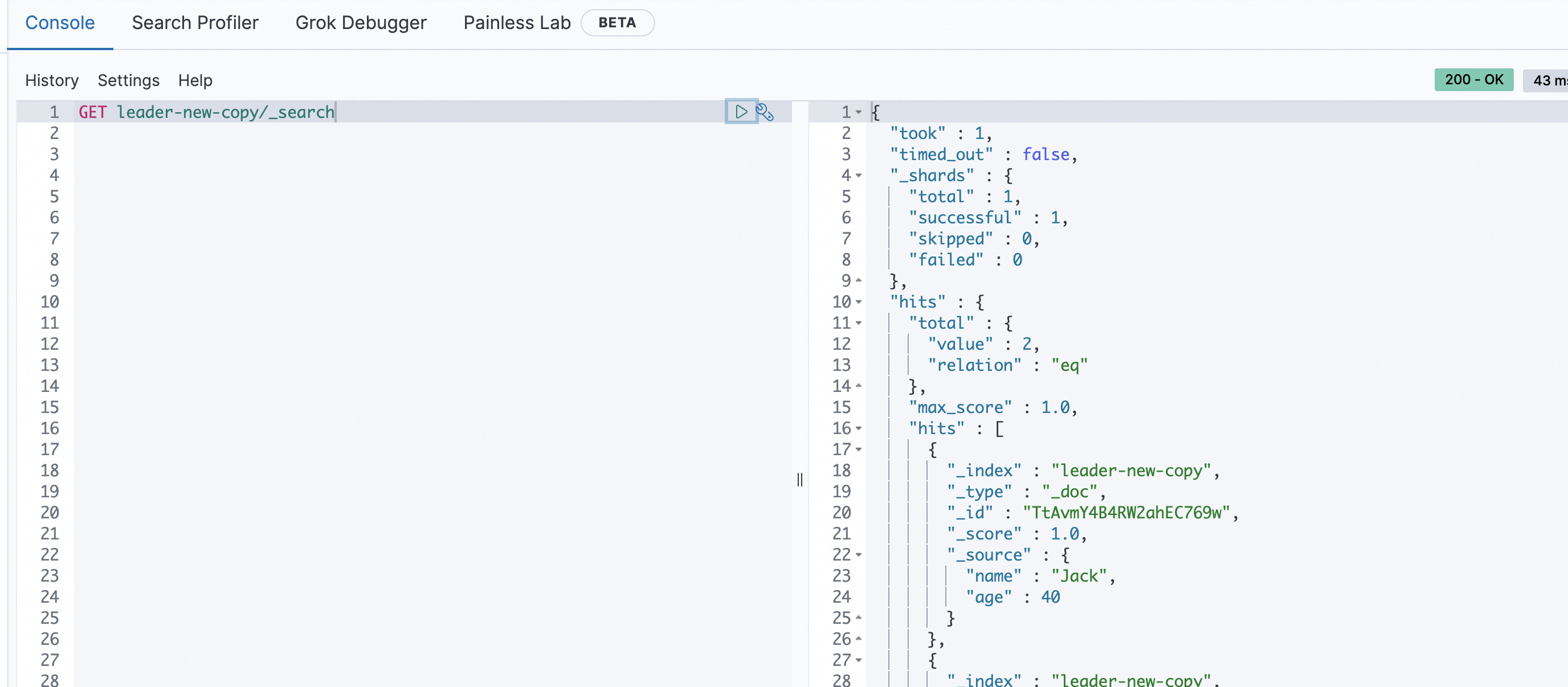
リーダーインデックスにドキュメントを挿入します。
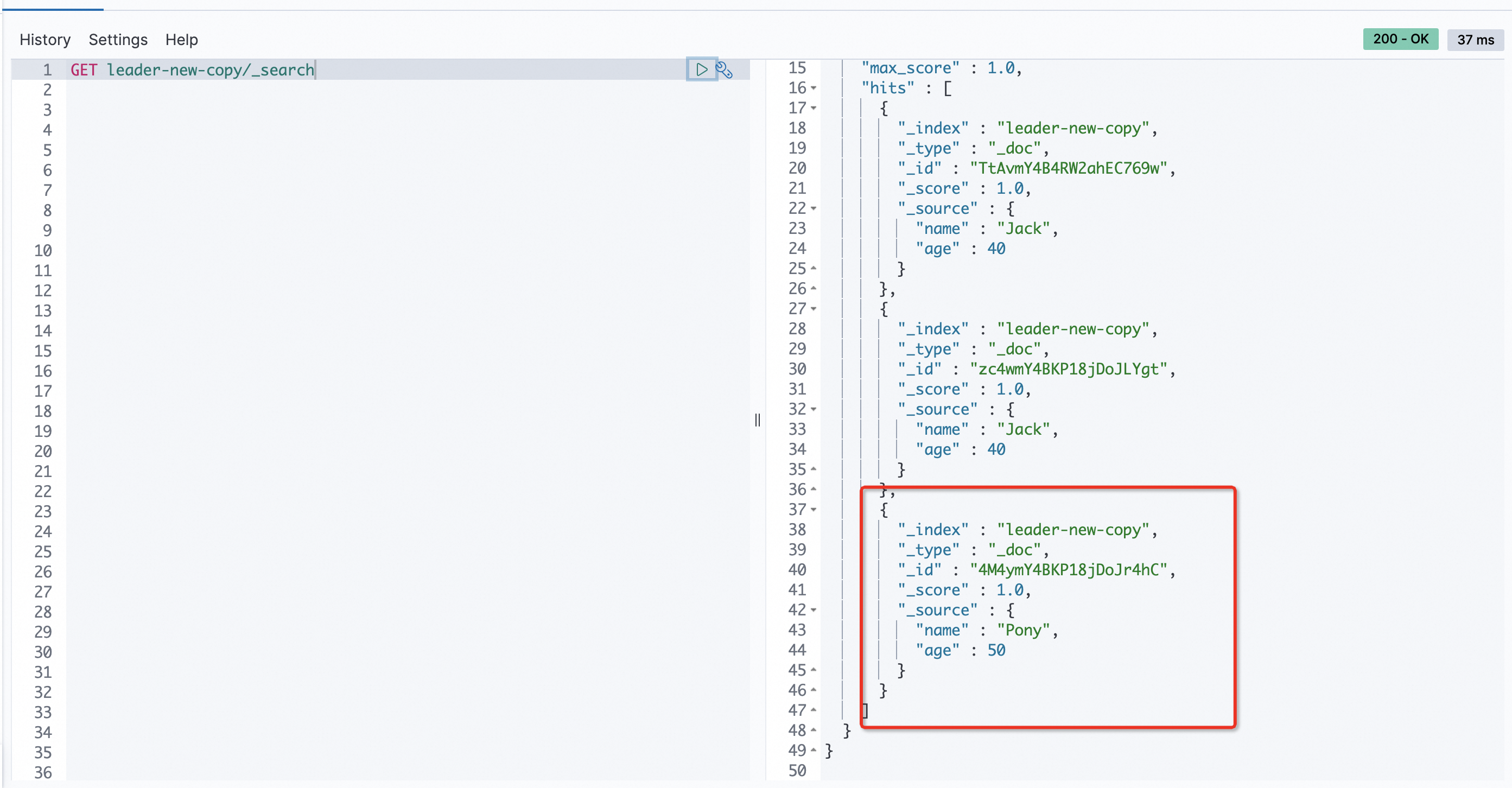
POST leader-new/_doc/ { "name":"Pony", "age":50 }ローカルクラスターで次のコマンドを実行して、増分データをリアルタイムでフォロワーインデックスにバックアップできるかどうかを確認します:
GET leader-new-copy/_searchコマンド出力は、増分データがフォロワーインデックスにバックアップされていることを示しています。
シナリオ 2: インデックスパターンを指定して複数のインデックスに CCR を実装する
ステップ 1: リモートクラスターをローカルクラスターに接続する
ローカルクラスターの Kibana コンソールにログインします。詳細については、「Kibana コンソールにログインする」をご参照ください。
表示されたページで、左上隅の
アイコンをクリックし、 を選択します。[Management] ページの左側のナビゲーションウィンドウで、[Remote Clusters] をクリックします。
[Add A Remote Cluster] をクリックします。
表示されたページで、リモートクラスターに関する情報を指定します。
[Name]: リモートクラスターの名前。名前は一意である必要があります。
[Connection Mode]: [Use Proxy Mode] をオンにします。
[Proxy Address]: プロキシサーバーのアドレス。アドレスは
エンドポイントドメイン名:9300形式である必要があります。エンドポイントドメイン名は、PrivateLink エンドポイントサービスに対応するエンドポイントのドメイン名です。説明CCR 中、Kibana はデータノードの IP アドレスを使用して TCP ポート 9300 経由でクラスターにアクセスします。HTTP ポート 9200 はサポートされていません。
[Save] をクリックします。
保存後、システムは自動的にリーダー クラスターに接続します。接続が成功すると、接続ステータスに [Connected] (接続済み). と表示されます。
API 使用例
PUT /_cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"<remote_cluster>": {
"mode": "PROXY",
"proxy_address": "Endpoint domain name:9300"
}
}
}
}
}パラメーター | 説明 |
persistent | クラスターが再起動されても設定が永続的に保存されるように指定します。 |
<remote_cluster> | リモートクラスターの名前に置き換えます。 |
mode | プロキシモードのみがサポートされています。ローカルクラスターは、設定されたプロキシアドレスを使用してリモートクラスターにアクセスします。リモートクラスターへのすべてのリクエストは、このプロキシアドレスに送信され、プロキシサーバーによってリモートクラスター内の適切なノードに転送されます。 |
proxy_address | プロキシサーバーのアドレス。アドレスは 説明 この例では、CCR または CCS は Elasticsearch のトランスポートレイヤーを使用し、通信にはポート 9300 を使用する必要があります。 |
ステップ 2: CCR の構成
ローカルクラスターの Kibana コンソールの [Management] ページに移動します。左側のナビゲーションウィンドウで、[Cross-Cluster Replication] をクリックします。
[Auto-follow Patterns] をクリックします。
[Create Auto-follow Pattern] をクリックします。
CCR を構成します。次の表に、主要なパラメーターを示します。
パラメーター
説明
リモートクラスター
ローカルクラスターに接続されているリモートクラスター。
インデックスパターン
データをバックアップするインデックスのパターン。
説明インデックスパターンは、一連のインデックス名 (例: leader-*) に一致させるために使用されるルールまたはテンプレートです。これらのパターンは通常、ワイルドカードまたは正規表現を使用して定義されます。パターンに一致するインデックスは、自動的にローカルクラスターにレプリケートされます。
API 使用例
PUT /_ccr/auto_follow/beats
{
"remote_cluster": "es-leader",
"leader_index_patterns":
[
"leader-*"
],
"follow_index_pattern": "{{leader_index}}-copy"
}パラメーター | 説明 |
remote_cluster | ローカルクラスターに接続されているリモートクラスターの名前。このパラメーターは、ステップ 1 の |
leader_index_patterns | インデックスパターン。これは、一連のインデックス名に一致させるために使用されるルールまたはテンプレートで、リモートクラスター内のどのインデックスをレプリケートする必要があるかを決定します。 |
follow_index_pattern | ローカルクラスターに作成されるインデックスのパターン。システムはパターンに基づいてローカルクラスターにインデックスを作成し、データをインデックスにバックアップします。 |
ステップ 3: データバックアップ結果の確認
リモートクラスターの Kibana コンソールで、次のコマンドを実行してインデックスを追加します:
PUT /leader-new { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" } } } }ローカルクラスターの Kibana コンソールで、次のコマンドを実行して、追加されたインデックスのデータがローカルクラスターにバックアップされているかどうかを確認します:
get _cat/indices?v
Alibaba Cloud Elasticsearch クラスターを接続して CCR を有効にする
準備
同じバージョン (6.7 以降) の Alibaba Cloud Elasticsearch クラスターを 2 つ作成します。2 つのクラスターが同じ VPC にデプロイされ、同じ vSwitch に属していることを確認してください。
説明2 つのクラスターは次のように使用されます:
1 つはリモートクラスターとして使用され、ソースデータを提供します。
もう 1 つはローカルクラスターとして使用され、リモートクラスター内の 1 つ以上のインデックスからデータをレプリケートします。
同義語ファイルをリモートクラスターにアップロードした場合は、同義語ファイルをローカルクラスターにアップロードする必要があります。
リモートクラスターをローカルクラスターに接続するように構成します。詳細については、「Elasticsearch クラスターを接続してクラスター間検索を有効にする」をご参照ください。
リモートクラスターにインデックス (リーダーインデックス) を作成します。
リモートクラスターの Kibana コンソールにログインします。詳細については、「Kibana コンソールにログインする」をご参照ください。
表示されたページで、左上隅の
アイコンをクリックし、[Management] >[Dev Tools]) を選択します。次のコマンドを実行して、リモートクラスターにリーダーインデックスを作成します:
PUT myindex { "settings": { "index.soft_deletes.retention.operations": 1024, "index.soft_deletes.enabled": true } }説明V7.0 以前の Elasticsearch クラスターにインデックスを作成する場合は、インデックスの soft_deletes 属性を有効にする必要があります。そうしないと、エラーが報告されます。
GET /<yourIndexName>/_settings?prettyコマンドを実行して、soft_deletes 属性が有効になっているかどうかを確認できます。soft_deletes 属性が有効になっている場合、soft_deletes 属性の構成がコマンド出力に表示されます。既存のインデックスのデータをバックアップする場合は、reindex API を呼び出して soft_deletes 属性を有効にできます。
リーダーインデックスの物理レプリケーション機能を無効にします。
説明Elasticsearch V6.7.0 クラスターのインデックスでは、物理レプリケーション機能が自動的に有効になります。CCR を使用する前に、物理レプリケーション機能を無効にする必要があります。
インデックスを無効にします。
POST myindex/_closeインデックスの設定構成を更新して、物理レプリケーション機能を無効にします。
PUT myindex/_settings { "index.replication.type" : null }インデックスを有効にします。
POST myindex/_open
ステップ 1: リモートクラスターをローカルクラスターに接続する
ローカルクラスターの Kibana コンソールにログインします。詳細については、「Kibana コンソールにログインする」をご参照ください。
表示されたページで、左上隅の
アイコンをクリックし、 を選択します。[Management] ページの左側のナビゲーションウィンドウで、[Remote Clusters] をクリックします。
[Add A Remote Cluster] をクリックします。
表示されたページで、リモートクラスターに関する情報を指定します。
[Name]: リモートクラスターの名前。名前は一意である必要があります。
[Proxy Address]: アドレスは
リモートクラスター内のノードの IP アドレス:9300形式である必要があります。ノードの IP アドレスを取得するには、リモートクラスターの Kibana コンソールにログインし、[Dev Tools] ページの [Console] タブでGET /_cat/nodes?vコマンドを実行します。指定するノードには、リモートクラスターの専用マスターノードを含める必要があります。複数のノードを指定することをお勧めします。これにより、指定した専用マスターノードに障害が発生した場合でも CCR を使用できます。説明CCR 中、Kibana はデータノードの IP アドレスを使用して TCP ポート 9300 経由でクラスターにアクセスします。HTTP ポート 9200 はサポートされていません。
[Save] をクリックします。
設定を保存すると、システムは自動的にリモートクラスターに接続します。接続が成功すると、接続ステータスに [Connected] (接続済み). と表示されます。
ステップ 2: CCR の構成
ローカルクラスターの Kibana コンソールの [Management] ページに移動します。左側のナビゲーションウィンドウで、[Cross-Cluster Replication] をクリックします。
[Create A Follower Index] をクリックします。
CCR を構成します。
パラメーター
説明
リモートクラスター
ローカルクラスターに接続されているリモートクラスター。
リーダーインデックス
データをバックアップするインデックス。この例では、準備で作成された [myindex] インデックスが使用されます。
フォロワーインデックス
データをバックアップするインデックス。一意のインデックス名を指定する必要があります。
[Create] をクリックします。
フォロワーインデックスが作成されると、インデックスは [Active] 状態になります。
ステップ 3: データバックアップ結果の確認
リモートクラスターの Kibana コンソールで、次のコマンドを実行してリモートクラスターにデータを挿入します:
POST myindex/_doc/ { "name":"Jack", "age":40 }ローカルクラスターの Kibana コンソールで、次のコマンドを実行して、挿入されたデータがローカルクラスターにバックアップされているかどうかを確認します:
GET myindex_follow/_search次の図に示す結果が返されます。この結果は、リモートクラスターのリーダーインデックス myindex のデータが、ローカルクラスターのフォロワーインデックス myindex_follow にバックアップされていることを示しています。
 説明
説明フォロワーインデックス myindex_follow は読み取り専用です。フォロワーインデックスにデータを書き込む場合は、まずフォロワーインデックスを共通インデックスに変換します。詳細については、「Elasticsearch CCR を使用してデータセンター間でデータを移行する」をご参照ください。
リモートクラスターに新しいデータレコードを挿入して、増分データが同期されているかどうかを確認します。
POST myindex/_doc/ { "name":"Pony", "age":50 }ローカルクラスターで挿入されたドキュメントをクエリします。次の図にドキュメントを示します。
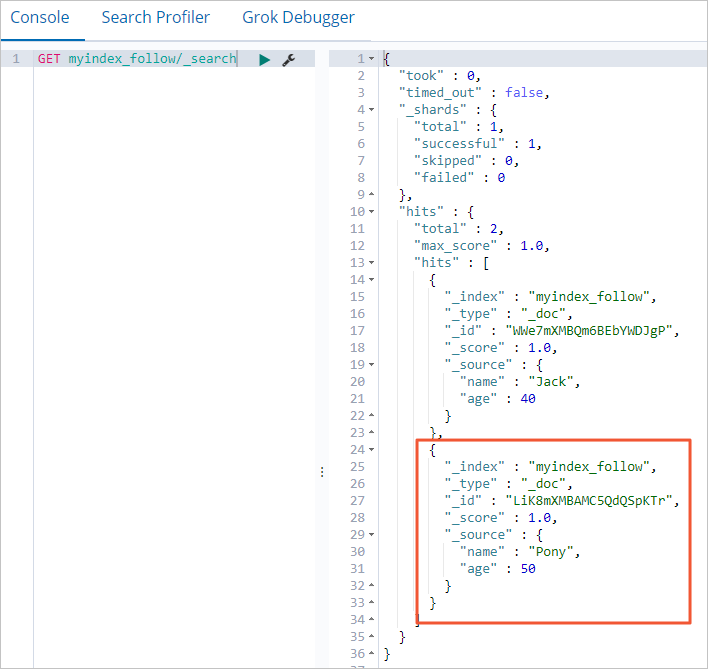
上の図は、CCR 機能が増分データのバックアップを実装できることを示しています。
説明CCR 機能の API を呼び出して、クラスター間レプリケーション操作を実行することもできます。詳細については、「クラスター間レプリケーション API」をご参照ください。
よくある質問
Q: ポート 9300 を使用してリモートクラスターを追加できます。ドメイン名を使用して Elasticsearch クラスターにアクセスする場合、なぜポート 9200 のみがアクセス可能なのでしょうか?
A: ポート 9300 はオープンポートです。ただし、インターネット経由でクラスターにアクセスする場合、Server Load Balancer (SLB) はセキュリティ上の理由からポート検証中にポート 9200 のみを有効にします。
Q: CCR ベースのデータ同期のステータスを表示するにはどうすればよいですか?
A: フォロワーインデックスを保存するクラスターの Kibana コンソールで
GET /_ccr/statsコマンドを実行し、number_of_failed_follow_indicesパラメーターの値を確認します。このパラメーターは、失敗したシャードの数を示します。パラメーターの値が 0 の場合、同期は正常です。
パラメーターの値が 0 でない場合は、フォロワーインデックスを保存するクラスターに対して次のコマンドを実行して、同期を一時停止してから再開します:
POST /<follower_index>/_ccr/pause_follow POST /<follower_index>/_ccr/resume_follow