このトピックでは、Alibaba Cloud Logstash を使用して PolarDB-X 1.0 データベースから Alibaba Cloud Elasticsearch にデータを同期し、全文検索とセマンティック分析を行う方法について説明します。
仕組み
Alibaba Cloud Logstash は、logstash-input-jdbc プラグインを使用して、前回のポーリング以降に挿入または更新されたレコードを PolarDB-X 1.0 から定期的にポーリングします。このプラグインは、デフォルトですべての Logstash クラスターにインストールされており、削除することはできません。
増分同期が正しく機能するには、次の 2 つの条件を満たす必要があります。
-
ID フィールドマッピング:Elasticsearch の
_idフィールドは、PolarDB-X 1.0 のidフィールドと一致する必要があります。このマッピングにより、PolarDB-X 1.0 でレコードが更新されたときに、同期パイプラインが正しい Elasticsearch ドキュメントを上書きできます。 -
タイムスタンプフィールド:ソーステーブルのすべてのレコードには、挿入または更新時刻を格納するフィールドを含める必要があります。プラグインはこのフィールドを追跡して、各ポーリングに含めるレコードを決定します。前回のポーリングより後のタイムスタンプを持つレコードのみが同期されます。
数秒のレイテンシーで完全なデータを同期する必要がある場合、またはスケジュールされた間隔で特定のレコードをクエリして同期する必要がある場合は、このアプローチを使用します。
前提条件
開始する前に、以下が準備できていることを確認してください。
-
データベースが作成された PolarDB-X 1.0 インスタンス
-
Alibaba Cloud Elasticsearch クラスター (この例では V6.7、Standard Edition を使用)
-
Alibaba Cloud Logstash クラスター
ネットワーク遅延を最小限に抑え、追加の設定を回避するために、3 つすべてのリソースを同じ VPC (Virtual Private Cloud) にデプロイします。
-
PolarDB-X 1.0 インスタンスとデータベースを作成するには、「PolarDB-X 1.0 インスタンスの作成」または「」をご参照ください。
-
Elasticsearch クラスターを作成するには、「Alibaba Cloud Elasticsearch クラスターの作成」をご参照ください。
-
Logstash クラスターを作成するには、「Alibaba Cloud Logstash クラスターの作成」をご参照ください。
Logstash を介してインターネットからデータを収集したり、インターネットにデータを転送したりするには、NAT (Network Address Translation) ゲートウェイを設定します。詳細については、「インターネット経由のデータ転送のための NAT ゲートウェイの設定」をご参照ください。
制限事項
-
削除は同期されない:logstash-input-jdbc プラグインは、PolarDB-X 1.0 から Elasticsearch への削除を伝播できません。削除されたレコードを処理するには、次のいずれかの戦略を使用します。
-
論理削除 (推奨):テーブルに
is_deletedフィールドを追加します。レコードが論理的に削除されたら、is_deletedをtrueに設定します。プラグインはこの変更を Elasticsearch に同期し、クエリで論理削除されたドキュメントを除外できます。 -
外部削除:PolarDB-X 1.0 のレコードを削除するシステムが、Elasticsearch クラスターでも直接対応する delete コマンドを実行するようにします。
-
-
ID フィールドの要件:Elasticsearch の
_idフィールドは、PolarDB-X 1.0 のidフィールドと一致する必要があります。これは、レコードが更新されたときにパイプラインがドキュメントを正しく上書きするために必要です。Elasticsearch では、上書きは元のドキュメントを削除して更新されたドキュメントをインデックス作成することと同等であり、これはネイティブな更新操作と同じくらい効率的です。 -
タイムスタンプフィールドの要件:挿入または更新されたすべてのレコードには、挿入または更新時刻をキャプチャするフィールドを含める必要があります。このフィールドがないレコードは、増分同期に含まれません。
-
追跡列の順序:
tracking_columnとして指定された列の値は、昇順である必要があります。
PolarDB-X 1.0 から Elasticsearch へのデータ同期
ステップ 1:ソースと送信先の設定
-
PolarDB-X 1.0 でテーブルを作成し、テストデータを挿入します。次の例では、
foodテーブルを作成します。CREATE TABLE food( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(32), insert_time DATETIME, update_time DATETIME );主要な列:
-
id:プライマリキー。その値は Elasticsearch の_idフィールドにマッピングされます。同期パイプラインがドキュメントを正しく識別して上書きするために必要です。 -
update_time:追跡タイムスタンプ。logstash-input-jdbc プラグインは、このフィールドを使用して前回のポーリング以降の変更を検出します。増分同期が機能するために必要です。 -
insert_time:行が最初に作成された日時を記録します。同期には必要ありませんが、監査に役立ちます。
サンプルデータを挿入します。
INSERT INTO food VALUES(null, 'Chocolates', NOW(), NOW()); INSERT INTO food VALUES(null, 'Yogurt', NOW(), NOW()); INSERT INTO food VALUES(null, 'Ham sausage', NOW(), NOW()); -
-
ご利用の Elasticsearch クラスターの自動インデックス作成機能を有効にします。詳細については、「Elasticsearch クラスターへのアクセスと設定」をご参照ください。
-
MySQL JDBC ドライバーを Logstash クラスターにアップロードします。ドライバーのバージョンは、ご利用の PolarDB-X 1.0 インスタンスと互換性がある必要があります。この例では、
mysql-connector-java-5.1.35を使用します。アップロード手順については、「サードパーティライブラリの設定」をご参照ください。説明PolarDB-X 1.0 への接続には、MySQL JDBC ドライバーを推奨します。PolarDB JDBC ドライバーは、PolarDB-X 2.0 では機能しない場合があります。
-
Logstash クラスターノードの IP アドレスを、ご利用の PolarDB-X 1.0 インスタンスの IP アドレスホワイトリストに追加します。ノードの IP アドレスは、Elasticsearch コンソールの Logstash クラスターの [基本情報] ページで確認できます。ホワイトリストへの追加手順については、「IP アドレスホワイトリストの設定」をご参照ください。
ステップ 2:Logstash パイプラインの設定
-
上部のナビゲーションバーで、クラスターが存在するリージョンを選択します。
-
[Logstash クラスター] ページで、対象のクラスターを見つけてその ID をクリックします。
-
左側のナビゲーションウィンドウで、[パイプライン] をクリックします。
-
[パイプライン] ページで、[パイプラインの作成] をクリックします。
-
[タスクの作成] ページで、[パイプライン ID] フィールドにパイプライン ID を入力し、[設定] フィールドに次の構成を入力します。
<Logstash cluster ID>、<Database name>、および認証情報を実際の値に置き換えてください。Logstash クラスター ID を確認するには、「Logstash クラスターページの概要」をご参照ください。重要セキュリティのため、JDBC ドライバーを使用する場合は、常に
allowLoadLocalInfile=false&autoDeserialize=falseをjdbc_connection_stringに追加してください。これらのパラメーターがないと、保存時にパイプライン構成のチェックが失敗します。Input プラグインパラメーター
パラメーター 型 デフォルト 説明 jdbc_driver_class文字列 — JDBC ドライバークラス。MySQL の場合は、 com.mysql.jdbc.Driverを使用します。jdbc_driver_library文字列 — Logstash クラスター上の JDBC ドライバーファイルへのパス。バックエンドは /ssd/1/share/<Logstash cluster ID>/logstash/current/config/custom/形式のパスを提供します。詳細については、「サードパーティライブラリの設定」をご参照ください。jdbc_connection_string文字列 — PolarDB-X 1.0 インスタンスのエンドポイント、ポート番号、データベース名を含む JDBC 接続文字列。 jdbc_user文字列 — PolarDB-X 1.0 データベースにアクセスするためのユーザー名。 jdbc_password文字列 — PolarDB-X 1.0 データベースにアクセスするためのパスワード。 jdbc_paging_enabledブール値 falseクエリ結果のページングを有効にするかどうか。 jdbc_page_size整数 — ページングが有効な場合の 1 ページあたりのレコード数。 statement文字列 — レコードをクエリするために使用される SQL ステートメント。 :sql_last_valueを最後に追跡された値のプレースホルダーとして使用します。この例では>=を使用して、最後に追跡されたタイムスタンプと同時に挿入または更新されたレコードを含め、ポーリングの境界でのデータ損失を最小限に抑えます。schedule文字列 — ポーリング間隔を制御する cron 式。 * * * * *は 1 分ごとにクエリを実行します。record_last_runブール値 false最後の実行値を永続化するかどうか。 trueの場合、最後のクエリのtracking_columnの値がlast_run_metadata_pathのファイルに保存されます。last_run_metadata_path文字列 — 最後の実行値が保存されるファイルパス。Alibaba Cloud Logstash が提供する /ssd/1/<Logstash cluster ID>/logstash/data/形式のパスを使用します。Logstash はファイルを自動的に作成します。ファイルの内容は表示できません。システムはこのパスのデータを削除しません。ディスクに十分な空き容量があることを確認してください。clean_runブール値 false最後の実行値を無視して、データベースの最初のレコードから開始するかどうか。完全な再同期を強制するには trueに設定します。use_column_valueブール値 falsetracking_columnの値を:sql_last_valueとして使用するかどうか。falseの場合、:sql_last_valueは最後のクエリ実行のタイムスタンプになります。tracking_column_type文字列 numeric追跡列のデータの型。有効な値: numeric、timestamp。tracking_column文字列 — 増分同期のために追跡する列。値は昇順である必要があります。これを挿入または更新時刻を格納する列 (例: update_time) に設定します。Output プラグインパラメーター
パラメーター 型 デフォルト 説明 hosts文字列 — Elasticsearch クラスターの内部エンドポイント URL。フォーマットは http://<internal endpoint>:9200です。エンドポイントは、クラスターの [基本情報] ページで確認できます。詳細については、「クラスターの基本情報の表示」をご参照ください。user文字列 elasticElasticsearch クラスターにアクセスするためのユーザー名。 password文字列 — elasticアカウントのパスワード。忘れた場合は、リセットできます。詳細については、「Elasticsearch クラスターのアクセスパスワードのリセット」をご参照ください。index文字列 — 同期されたデータが保存される Elasticsearch インデックスの名前。 document_id文字列 — Elasticsearch のドキュメント ID。 %{id}に設定して PolarDB-X 1.0 のidフィールドを使用することで、各データベースレコードが 1 つの Elasticsearch ドキュメントに正確にマッピングされます。input { jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_driver_library => "/ssd/1/share/<Logstash cluster ID>/logstash/current/config/custom/mysql-connector-java-5.1.35.jar" jdbc_connection_string => "jdbc:mysql://drdshbga51x6****.drds.aliyuncs.com:3306/<Database name>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" jdbc_user => "db_user" jdbc_password => "db_password" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select * from food where update_time >= :sql_last_value" schedule => "* * * * *" record_last_run => true last_run_metadata_path => "/ssd/1/<Logstash cluster ID>/logstash/data/last_run_metadata_update_time.txt" clean_run => false tracking_column_type => "timestamp" use_column_value => true tracking_column => "update_time" } } filter { } output { elasticsearch { hosts => "http://es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com:9200" user => "elastic" password => "es_password" index => "drds_test" document_id => "%{id}" } }Input プラグインパラメーターの完全なリストについては、「Logstash JDBC input plugin」をご参照ください。一般的なパイプライン構成の構文については、「Logstash 構成ファイル」をご参照ください。
-
[次へ] をクリックして、パイプラインパラメーターを設定します。
警告パイプラインを保存してデプロイすると、Logstash クラスターが再起動されます。続行する前に、再起動がサービスに影響しないことを確認してください。
パラメーター デフォルト 説明 パイプラインワーカー vCPU の数 フィルタープラグインと出力プラグインを並行して実行するワーカースレッドの数。イベントがバックログされている場合や CPU リソースが十分に活用されていない場合は、この値を増やします。 パイプラインバッチサイズ 125 ワーカースレッドが入力プラグインから収集し、フィルタープラグインと出力プラグインを実行する前に収集するイベントの最大数。値を大きくするとスループットは向上しますが、より多くのメモリを消費します。 LS_HEAP_SIZE変数を使用して JVM ヒープサイズを増やすことで、より大きなバッチに対応できます。パイプラインバッチ遅延 50 ms 小さなバッチをパイプラインワーカースレッドに割り当てるまでの待機時間。 キュータイプ MEMORY イベントをバッファリングするための内部キューモデル。MEMORY はメモリベースのキューを使用します。PERSISTED は ACK をサポートするディスクベースの永続キューを使用します。 キュー最大バイト数 1024 MB キューの最大サイズ。合計ディスク容量未満である必要があります。 チェックポイント書き込みのキュー 1024 チェックポイントが強制される前に書き込まれるイベントの数 (永続キューのみ)。制限なしにするには 0に設定します。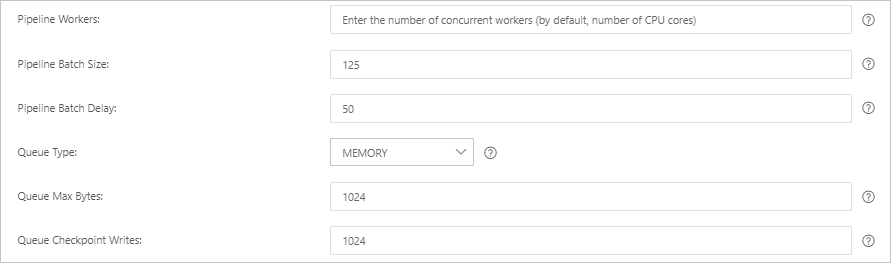
-
[保存] または [保存してデプロイ] をクリックします。
-
保存:パイプライン構成を保存し、クラスターの変更をトリガーしますが、パイプラインはアクティブ化されません。アクティブ化するには、[パイプライン] ページに移動し、パイプラインを見つけて、[操作] 列の [デプロイ] をクリックします。
-
保存してデプロイ:Logstash クラスターを保存し、すぐに再起動してパイプラインをアクティブ化します。
-
ステップ 3:結果の検証
-
Elasticsearch クラスターの Kibana コンソールにログインします。詳細については、「Kibana コンソールへのログイン」をご参照ください。
-
左側のナビゲーションウィンドウで、[開発ツール] をクリックします。
-
[コンソール] タブで、次のクエリを実行して、3 つのサンプルレコードが同期されたことを確認します。
GET drds_test/_count { "query": {"match_all": {}} }期待される応答:
{ "count": 3, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 } } -
PolarDB-X 1.0 で既存のレコードを更新し、新しいレコードを挿入します。
UPDATE food SET name='Chocolates', update_time=NOW() WHERE id = 1; INSERT INTO food VALUES(null, 'Egg', NOW(), NOW()); -
次のポーリングサイクルが完了した後 (1 分以内)、Kibana で更新を確認します。更新されたレコードをクエリします。
GET drds_test/_search { "query": { "match": { "name": "Chocolates" } } }コマンドが正常に実行されると、次の図に示す結果が返されます。
 すべてのレコードをクエリして、新しい行が追加されたことを確認します。
すべてのレコードをクエリして、新しい行が追加されたことを確認します。GET drds_test/_search { "query": { "match_all": {} } }コマンドが正常に実行されると、次の図に示す結果が返されます。
