Elasticsearch-Hadoop(ES-Hadoop)は、オープンソースの Elasticsearch によって開発されたツールです。Elasticsearch を Apache Hadoop に接続し、それらの間のデータ転送を可能にします。 ES-Hadoop は、Elasticsearch の高速検索機能と Hadoop のバッチ処理機能を組み合わせることで、インタラクティブなデータ処理を実現します。このトピックでは、ES-Hadoop を使用して Hive で Alibaba Cloud Elasticsearch にデータを書き込んだり、Alibaba Cloud Elasticsearch からデータを読み取ったりする方法について説明し、Elasticsearch と Hadoop を組み合わせてより柔軟なデータ分析を実装するのに役立ちます。
背景情報
Hadoop は大規模なデータセットを処理できます。ただし、インタラクティブ分析に使用する場合、高レイテンシが発生します。 Elasticsearch は、インタラクティブ分析において Hadoop よりも優れています。特にアドホッククエリに対して、数秒以内にクエリに応答できます。 ES-Hadoop は、Hadoop と Elasticsearch の利点を組み合わせたものです。 ES-Hadoop を使用すると、Elasticsearch に保存されているデータを処理するためのコード変更をわずかに行うだけで済みます。 ES-Hadoop は、高速なクエリエクスペリエンスも提供します。
ES-Hadoop は、MapReduce、Spark、Hive などのデータ処理エンジンのデータソースとして Elasticsearch を使用します。 ES-Hadoop は、コンピューティングストレージ分離アーキテクチャのストレージとしても Elasticsearch を使用します。 Elasticsearch は、MapReduce、Spark、Hive の他のデータソースと同様の方法で動作します。ただし、Elasticsearch はより迅速にデータを選択およびフィルタリングできます。これは分析エンジンにとって重要です。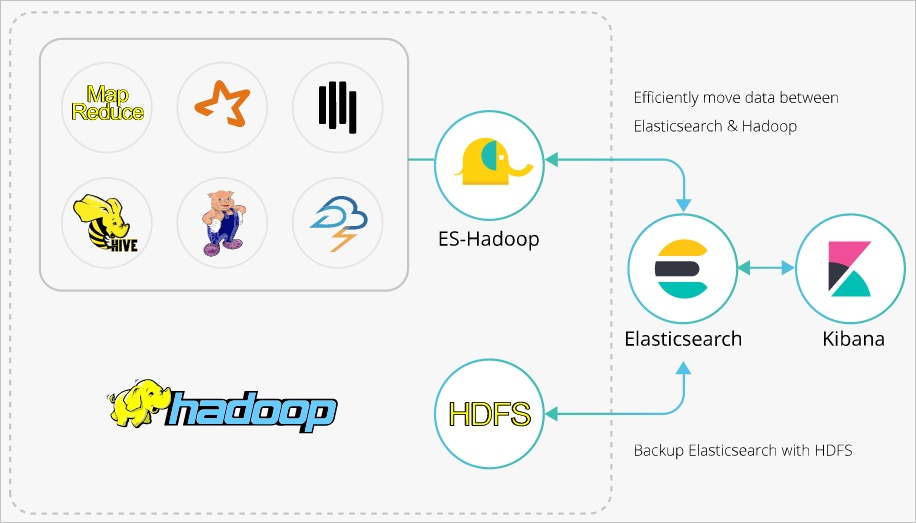
ES-Hadoop と Hive の高度な構成の詳細については、オープンソース Elasticsearch のドキュメントをご参照ください。
手順
同じ仮想プライベートクラウド(VPC)に Alibaba Cloud Elasticsearch クラスタと E-MapReduce(EMR)クラスタを作成し、Elasticsearch クラスタの自動インデックス作成機能を無効にし、Elasticsearch クラスタにインデックスを作成し、インデックスのマッピングを構成します。
手順 1:ES-Hadoop JAR パッケージを HDFS にアップロードする
Elasticsearch クラスタのバージョンと互換性のある ES-Hadoop パッケージをダウンロードし、EMR クラスタのマスターノードの HDFS ディレクトリに ES-Hadoop パッケージをアップロードします。
Hive 外部テーブルを作成し、テーブルのフィールドを Elasticsearch クラスタのインデックスのフィールドにマッピングします。
手順 3:Hive を使用してインデックスにデータを書き込む
HiveSQL を使用して Elasticsearch クラスタのインデックスにデータを書き込みます。
手順 4:Hive を使用してインデックスからデータを読み取る
HiveSQL を使用して Elasticsearch クラスタのインデックスからデータを読み取ります。
準備
Alibaba Cloud Elasticsearch クラスタを作成します。
この例では、Elasticsearch V6.7.0 クラスタが作成されます。詳細については、Alibaba Cloud Elasticsearch クラスタの作成をご参照ください。
クラスタの自動インデックス作成機能を無効にし、クラスタにインデックスを作成し、インデックスのマッピングを構成します。
クラスタの自動インデックス作成機能を有効にすると、Elasticsearch クラスタによって自動的に作成されるインデックスが要件を満たさない場合があります。たとえば、INT データ型の age フィールドを定義し、自動インデックス作成機能を有効にしたとします。この場合、age フィールドのデータ型はインデックスで LONG になる可能性があります。そのため、自動インデックス作成機能を無効にすることをお勧めします。この例では、company という名前のインデックスが作成されます。次のコードは、このインデックスとそのマッピングを示しています。
PUT company { "mappings": { "_doc": { "properties": { "id": { "type": "long" }, "name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "birth": { "type": "text" }, "addr": { "type": "text" } } } }, "settings": { "index": { "number_of_shards": "5", "number_of_replicas": "1" } } }Elasticsearch クラスタと同じ VPC に存在する EMR クラスタを作成します。
重要デフォルトでは、Elasticsearch クラスタのプライベート IP アドレスホワイトリストに 0.0.0.0/0 が指定されています。ホワイトリストの構成は、クラスタセキュリティ構成ページで表示できます。デフォルト設定を使用しない場合は、EMR クラスタのプライベート IP アドレスをホワイトリストに追加する必要があります。
EMR クラスタのプライベート IP アドレスを取得する方法の詳細については、クラスタリストとクラスタの詳細の表示をご参照ください。
Elasticsearch クラスタのプライベート IP アドレスホワイトリストを構成する方法の詳細については、Elasticsearch クラスタのパブリックまたはプライベート IP アドレスホワイトリストの構成をご参照ください。ホワイトリストに登録されている IP アドレスを使用して、VPC 経由で Elasticsearch クラスタにアクセスできます。
手順 1:ES-Hadoop JAR パッケージを HDFS にアップロードする
Elasticsearch クラスタのバージョンと互換性のある ES-Hadoop パッケージをダウンロードします。
この例では、elasticsearch-hadoop-6.7.0.zip パッケージを使用します。
EMR コンソールにログインし、EMR クラスタのマスターノードの IP アドレスを取得します。次に、SSH を使用して、IP アドレスで示される Elastic Compute Service(ECS)インスタンスにログインします。
詳細については、クラスタへのログインをご参照ください。
elasticsearch-hadoop-6.7.0.zip パッケージをマスターノードにアップロードし、パッケージを解凍して elasticsearch-hadoop-hive-6.7.0.jar ファイルを取得します。
HDFS ディレクトリを作成し、elasticsearch-hadoop-hive-6.7.0.jar ファイルをディレクトリにアップロードします。
hadoop fs -mkdir /tmp/hadoop-es hadoop fs -put elasticsearch-hadoop-6.7.0/dist/elasticsearch-hadoop-hive-6.7.0.jar /tmp/hadoop-es
手順 2:Hive 外部テーブルを作成する
EMR コンソールの [データプラットフォーム] タブで、[hivesql] ジョブを作成します。
詳細については、Hive SQL ジョブの構成をご参照ください。
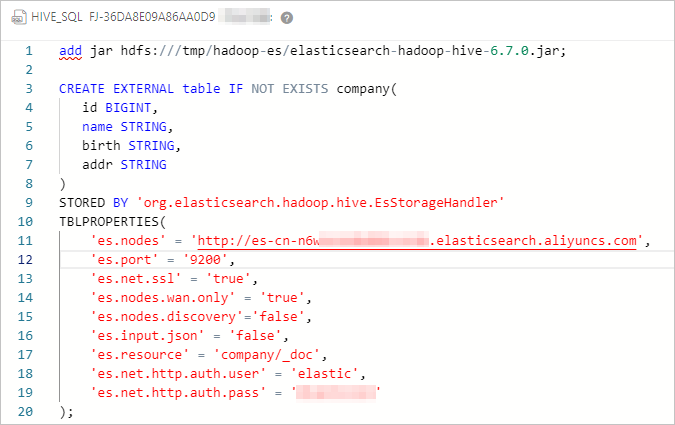
ジョブを構成し、Hive 外部テーブルを作成します。
次のコードは、ジョブの構成を示しています。
####JAR ファイルを追加します。これは現在のセッションでのみ有効です。######## add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; ####Hive 外部テーブルを作成し、テーブルを Elasticsearch クラスタのインデックスにマップします。#### CREATE EXTERNAL table IF NOT EXISTS company( id BIGINT, name STRING, birth STRING, addr STRING ) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES( 'es.nodes' = 'http://es-cn-mp91kzb8m0009****.elasticsearch.aliyuncs.com', 'es.port' = '9200', 'es.net.ssl' = 'true', 'es.nodes.wan.only' = 'true', 'es.nodes.discovery'='false', 'es.input.use.sliced.partitions'='false', 'es.input.json' = 'false', 'es.resource' = 'company/_doc', 'es.net.http.auth.user' = 'elastic', 'es.net.http.auth.pass' = 'xxxxxx' );表 1. ES-Hadoop パラメータ
パラメータ
デフォルト値
説明
es.nodes
localhost
Elasticsearch クラスタにアクセスするために使用されるエンドポイント。内部エンドポイントを使用することをお勧めします。内部エンドポイントは、Elasticsearch クラスタの「基本情報」ページで取得できます。詳細については、クラスタの基本情報の表示をご参照ください。
es.port
9200
Elasticsearch クラスタにアクセスするために使用されるポート番号。
es.net.http.auth.user
elastic
Elasticsearch クラスタにアクセスするために使用されるユーザー名。
説明elastic アカウントを使用して Elasticsearch クラスタにアクセスし、アカウントのパスワードをリセットする場合、新しいパスワードが有効になるまでに時間がかかる場合があります。この期間中は、elastic アカウントを使用してクラスタにアクセスすることはできません。そのため、Elasticsearch クラスタへのアクセスに elastic アカウントを使用しないことをお勧めします。Kibana コンソールにログインし、Elasticsearch クラスタにアクセスするために必要なロールを持つユーザーを作成できます。詳細については、Elasticsearch X-Pack が提供する RBAC メカニズムを使用したアクセス制御の実装をご参照ください。
es.net.http.auth.pass
/
Elasticsearch クラスタにアクセスするために使用されるパスワード。
es.nodes.wan.only
false
Elasticsearch クラスタが接続に仮想 IP アドレスを使用する場合に、ノードスニッフィングを有効にするかどうかを指定します。有効な値:
true:ノードスニッフィングを有効にします。
false:ノードスニッフィングを無効にします。
es.nodes.discovery
true
ノード検出メカニズムを有効にするかどうかを指定します。有効な値:
true: ノード検出メカニズムを有効にします。
false: ノード検出メカニズムを無効にします。
重要Alibaba Cloud Elasticsearch を使用する場合は、このパラメータを false に設定する必要があります。
es.input.use.sliced.partitions
true
パーティションを使用するかどうかを指定します。有効な値:
true:パーティションを使用します。この場合、インデックスの先読みフェーズにより多くの時間がかかる場合があります。このフェーズに必要な時間は、データクエリに必要な時間よりも長くなる場合があります。クエリ効率を向上させるには、このパラメータを false に設定することをお勧めします。
false:パーティションを使用しません。
es.index.auto.create
true
ES-Hadoop を使用してクラスタにデータを書き込むときに、システムが Elasticsearch クラスタにインデックスを作成するかどうかを指定します。有効な値:
true:システムは Elasticsearch クラスタにインデックスを作成します。
false:システムは Elasticsearch クラスタにインデックスを作成しません。
es.resource
/
データの読み取りまたは書き込み操作が実行されるインデックスの名前とタイプ。
es.mapping.names
/
テーブルのフィールド名と Elasticsearch クラスタのインデックスのフィールド名のマッピング。
es.read.metadata
false
_id などのドキュメントメタデータを結果に含めるかどうかを指定します。ドキュメントメタデータを含めるには、値を true に設定します。
ES-Hadoop の構成項目の詳細については、オープンソース ES-Hadoop 構成をご参照ください。
ジョブを保存して実行します。
ジョブが正常に実行されると、次の図に示す結果が返されます。

手順 3:Hive を使用してインデックスにデータを書き込む
[hivesql] データ書き込みジョブを作成します。
次のコードは、ジョブの構成を示しています。
add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; INSERT INTO TABLE company VALUES (1, "zhangsan", "1990-01-01","No.969, wenyixi Rd, yuhang, hangzhou"); INSERT INTO TABLE company VALUES (2, "lisi", "1991-01-01", "No.556, xixi Rd, xihu, hangzhou"); INSERT INTO TABLE company VALUES (3, "wangwu", "1992-01-01", "No.699 wangshang Rd, binjiang, hangzhou");ジョブを保存して実行します。

ジョブが正常に実行されたら、Elasticsearch クラスタの Kibana コンソールにログインし、company インデックスのデータをクエリします。
Kibana コンソールにログインする方法の詳細については、Kibana コンソールへのログインをご参照ください。次のコマンドを実行して、company インデックスのデータをクエリできます。
GET company/_searchコマンドが正常に実行されると、次の図に示す結果が返されます。
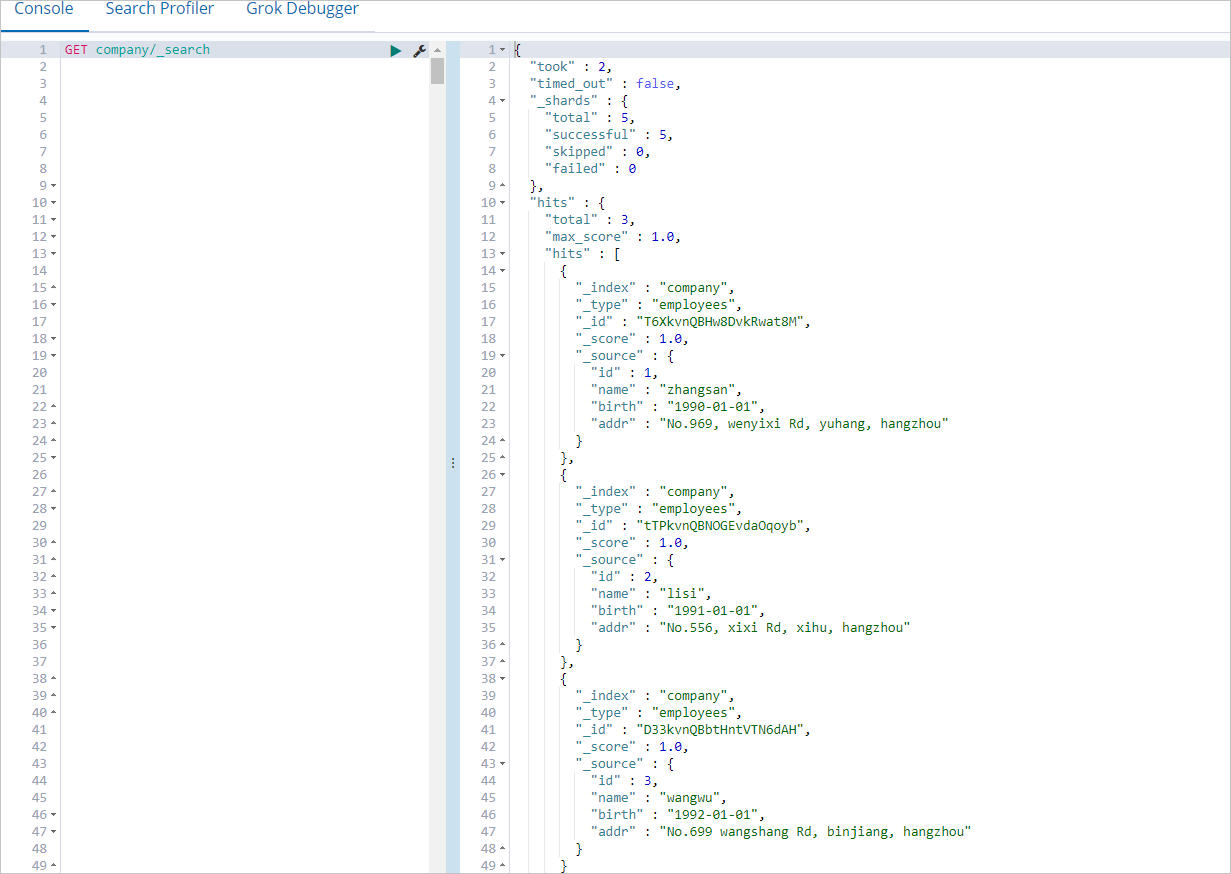
手順 4:Hive を使用してインデックスからデータを読み取る
[hivesql] データ読み取りジョブを作成します。
次のコードは、ジョブの構成を示しています。
add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; select * from company;ジョブを保存して実行します。

FAQ
Q:Hive が Elasticsearch からデータを読み書きするときに、次のエラーメッセージが報告された場合はどうすればよいですか?
FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Could not initialize class org.elasticsearch.hadoop.rest.commonshttp.CommonsHttpTransport.A: このエラーメッセージは、EMR V5.6.0 クラスタの Hive コンポーネントに commons-httpclient-3.1.jar ファイルが存在しないために報告されます。この問題を解決するには、Hive の lib ディレクトリに手動でファイルを追加します。詳細については、「commons-httpclient-3.1」をご参照ください。