Apache Spark は、ビッグデータコンピューティング用の汎用フレームワークであり、Hadoop MapReduce のすべてのコンピューティング上の利点を備えています。Spark と MapReduce の違いは、Spark はメモリ内にデータをキャッシュして、大規模データセットの高速反復を可能にすることです。この方法では、ディスクではなくキャッシュから直接データを読み取ることができます。これにより、Spark は MapReduce よりも高い処理パフォーマンスを提供できます。このトピックでは、Elasticsearch-Hadoop (ES-Hadoop) を使用して、Spark で Alibaba Cloud Elasticsearch にデータを書き込んだり、Alibaba Cloud Elasticsearch からデータを読み取ったりする方法について説明します。
準備
- Alibaba Cloud Elasticsearch クラスタを作成し、クラスタの自動インデックス作成機能を有効にします。詳細については、「Alibaba Cloud Elasticsearch クラスタを作成する」および「Elasticsearch クラスタにアクセスして構成する」をご参照ください。このトピックでは、Elasticsearch V6.7.0 クラスタが作成されます。重要 本番環境では、自動インデックス作成機能を無効にすることをお勧めします。事前にインデックスを作成し、インデックスのマッピングを構成する必要があります。このトピックで使用されている Elasticsearch クラスタはテスト用のみです。そのため、自動インデックス作成機能が有効になっています。
Elasticsearch クラスタが存在する仮想プライベートクラウド (VPC) に E-MapReduce (EMR) クラスタを作成します。
EMR クラスタ構成:
EMR バージョン: EMR-3.29.0 を選択します。
必須サービス: Spark (2.4.5) は必須サービスの 1 つです。他のサービスについては、デフォルト設定が保持されます。
詳細については、「クラスタを作成する」をご参照ください。
重要デフォルトでは、Elasticsearch クラスタのプライベート IP アドレスホワイトリストに 0.0.0.0/0 が指定されています。クラスタセキュリティ構成ページでホワイトリスト構成を表示できます。デフォルト設定を使用しない場合は、EMR クラスタのプライベート IP アドレスをホワイトリストに追加する必要があります。
EMR クラスタのプライベート IP アドレスを取得する方法の詳細については、「クラスタリストとクラスタの詳細を表示する」をご参照ください。
Elasticsearch クラスタのプライベート IP アドレスホワイトリストを構成する方法の詳細については、「Elasticsearch クラスタのパブリックまたはプライベート IP アドレスホワイトリストを構成する」をご参照ください。ホワイトリストに登録されている IP アドレスを使用して、VPC 経由で Elasticsearch クラスタにアクセスできます。
Java 環境を準備します。JDK バージョンは 1.8.0 以降である必要があります。
Spark ジョブのコンパイルと実行
テストデータを準備します。
E-MapReduce コンソール にログインし、EMR クラスタのマスターノードの IP アドレスを取得します。次に、SSH を使用して、IP アドレスで示される Elastic Compute Service (ECS) インスタンスにログインします。
詳細については、「クラスタにログインする」をご参照ください。
テストデータをファイルに書き込みます。
この例では、次の JSON 形式のテストデータが http_log.txt ファイルに書き込まれます。
{"id": 1, "name": "zhangsan", "birth": "1990-01-01", "addr": "No.969, wenyixi Rd, yuhang, hangzhou"} {"id": 2, "name": "lisi", "birth": "1991-01-01", "addr": "No.556, xixi Rd, xihu, hangzhou"} {"id": 3, "name": "wangwu", "birth": "1992-01-01", "addr": "No.699 wangshang Rd, binjiang, hangzhou"}次のコマンドを実行して、ファイルを EMR クラスタのマスターノードの /tmp/hadoop-es ディレクトリにアップロードします。
hadoop fs -put http_log.txt /tmp/hadoop-es
POM 依存関係を追加します。
Java Maven プロジェクトを作成し、プロジェクトの pom.xml ファイルに次の POM 依存関係を追加します。
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>2.4.5</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.5</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch-spark-20_2.11</artifactId> <version>6.7.0</version> </dependency> </dependencies>重要POM 依存関係のバージョンが、関連する Alibaba Cloud サービスのバージョンと一致していることを確認してください。たとえば、elasticsearch-spark-20_2.11 のバージョンは Elasticsearch クラスタのバージョンと一致し、spark-core_2.12 のバージョンは HDFS のバージョンと一致しています。
コードをコンパイルします。
データの書き込み
次のサンプルコードは、テストデータを Elasticsearch クラスタの company インデックスに書き込むために使用されます。
import java.util.Map; import java.util.concurrent.atomic.AtomicInteger; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import org.spark_project.guava.collect.ImmutableMap; public class SparkWriteEs { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("Es-write"); conf.set("es.nodes", "es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com"); // Elasticsearch クラスタのエンドポイント conf.set("es.net.http.auth.user", "elastic"); // Elasticsearch クラスタにアクセスするためのユーザー名 conf.set("es.net.http.auth.pass", "xxxxxx"); // elastic ユーザー名に対応するパスワード conf.set("es.nodes.wan.only", "true"); // ノードスニッフィングを有効にするかどうかを指定 conf.set("es.nodes.discovery","false"); // ノード検出メカニズムを禁止するかどうかを指定 conf.set("es.input.use.sliced.partitions","false"); // パーティションを使用するかどうかを指定 SparkSession ss = new SparkSession(new SparkContext(conf)); final AtomicInteger employeesNo = new AtomicInteger(0); // /tmp/hadoop-es/http_log.txt をテストデータの実際のパスに置き換えます。 JavaRDD<Map<Object, ?>> javaRDD = ss.read().text("/tmp/hadoop-es/http_log.txt") .javaRDD().map((Function<Row, Map<Object, ?>>) row -> ImmutableMap.of("employees", employeesNo.getAndAdd(1), row.mkString())); JavaEsSpark.saveToEs(javaRDD, "company/_doc"); // データを書き込むインデックスを指定 } }データの読み取り
次のサンプルコードは、Elasticsearch クラスタに書き込まれたテストデータを読み取って表示するために使用されます。
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import java.util.Map; public class ReadES { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("readEs").setMaster("local[*]") .set("es.nodes", "es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com") // Elasticsearch クラスタのエンドポイント .set("es.port", "9200") // Elasticsearch クラスタにアクセスするためのポート番号 .set("es.net.http.auth.user", "elastic") // Elasticsearch クラスタにアクセスするためのユーザー名 .set("es.net.http.auth.pass", "xxxxxx") // elastic ユーザー名に対応するパスワード .set("es.nodes.wan.only", "true") // ノードスニッフィングを有効にするかどうかを指定 .set("es.nodes.discovery","false") // ノード検出メカニズムを禁止するかどうかを指定 .set("es.input.use.sliced.partitions","false") // パーティションを使用するかどうかを指定 .set("es.resource", "company/_doc") // データを読み取るインデックスを指定 .set("es.scroll.size","500"); // スクロールサイズを指定 JavaSparkContext sc = new JavaSparkContext(conf); JavaPairRDD<String, Map<String, Object>> rdd = JavaEsSpark.esRDD(sc); for ( Map<String, Object> item : rdd.values().collect()) { System.out.println(item); } sc.stop(); } }
表 1. パラメーター
パラメーター
デフォルト値
説明
es.nodes
localhost
Elasticsearch クラスタにアクセスするために使用されるエンドポイント。内部エンドポイントを使用することをお勧めします。Elasticsearch クラスタの「基本情報」ページで内部エンドポイントを取得できます。詳細については、「クラスタの基本情報を表示する」をご参照ください。
es.port
9200
Elasticsearch クラスタにアクセスするために使用されるポート番号。
es.net.http.auth.user
elastic
Elasticsearch クラスタにアクセスするために使用されるユーザー名。
説明elastic アカウントを使用して Elasticsearch クラスタにアクセスし、アカウントのパスワードをリセットする場合、新しいパスワードが有効になるまでに時間がかかることがあります。この期間中は、elastic アカウントを使用してクラスタにアクセスすることはできません。そのため、Elasticsearch クラスタへのアクセスに elastic アカウントを使用しないことをお勧めします。Kibana コンソールにログインし、必要なロールを持つユーザーを作成して、Elasticsearch クラスタにアクセスできます。詳細については、「Elasticsearch X-Pack が提供する RBAC メカニズムを使用してアクセス制御を実装する」をご参照ください。
es.net.http.auth.pass
/
elastic ユーザー名に対応するパスワード。パスワードは、Elasticsearch クラスタの作成時に指定します。パスワードを忘れた場合は、リセットできます。詳細については、「Elasticsearch クラスタのアクセスパスワードをリセットする」をご参照ください。
es.nodes.wan.only
false
Elasticsearch クラスタが接続に仮想 IP アドレスを使用する場合に、ノードスニッフィングを有効にするかどうかを指定します。有効な値:
true: ノードスニッフィングが有効になっていることを示します。
false: ノードスニッフィングが無効になっていることを示します。
es.nodes.discovery
true
ノード検出メカニズムを禁止するかどうかを指定します。有効な値:
true: ノード検出メカニズムが禁止されていることを示します。
false: ノード検出メカニズムが禁止されていないことを示します。
重要Alibaba Cloud Elasticsearch を使用する場合は、このパラメーターを false に設定する必要があります。
es.input.use.sliced.partitions
true
パーティションを使用するかどうかを指定します。有効な値:
true: パーティションを使用します。この場合、インデックスの先読みフェーズにより多くの時間がかかることがあります。このフェーズに必要な時間は、データクエリに必要な時間よりも長くなることがあります。クエリ効率を向上させるには、このパラメーターを false に設定することをお勧めします。
false: パーティションを使用しません。
es.index.auto.create
true
ES-Hadoop を使用してクラスタにデータを書き込むときに、システムが Elasticsearch クラスタにインデックスを作成するかどうかを指定します。有効な値:
true: システムが Elasticsearch クラスタにインデックスを作成することを示します。
false: システムが Elasticsearch クラスタにインデックスを作成しないことを示します。
es.resource
/
データの読み取りまたは書き込み操作が実行されるインデックスの名前とタイプ。
es.mapping.names
/
テーブルのフィールド名と Elasticsearch クラスタのインデックスのフィールド名の間のマッピング。
ES-Hadoop の設定項目の詳細については、「オープンソース ES-Hadoop 構成」をご参照ください。
- コードを JAR パッケージに圧縮し、EMR クラスタのマスターノードやこの EMR クラスタに関連付けられているゲートウェイクラスタなど、EMR クライアントにアップロードします。
EMR クライアントで、次の Spark ジョブを実行します。
データの書き込み
cd /usr/lib/spark-current ./bin/spark-submit --master yarn --executor-cores 1 --class "SparkWriteEs" /usr/local/spark_es.jar重要/usr/local/spark_es.jar は、JAR パッケージをアップロードしたパスに置き換えます。
データの読み取り
cd /usr/lib/spark-current ./bin/spark-submit --master yarn --executor-cores 1 --class "ReadES" /usr/local/spark_es.jarデータが読み取られると、次の図に示す結果が返されます。
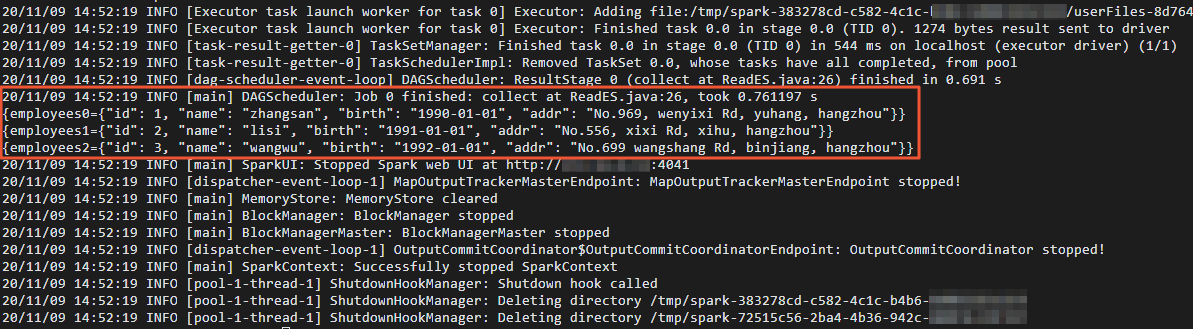
結果の確認
- Elasticsearch クラスタの Kibana コンソールにログインします。詳細については、「Kibana コンソールにログインする」をご参照ください。
- 左側のナビゲーションウィンドウで、[Dev Tools] をクリックします。
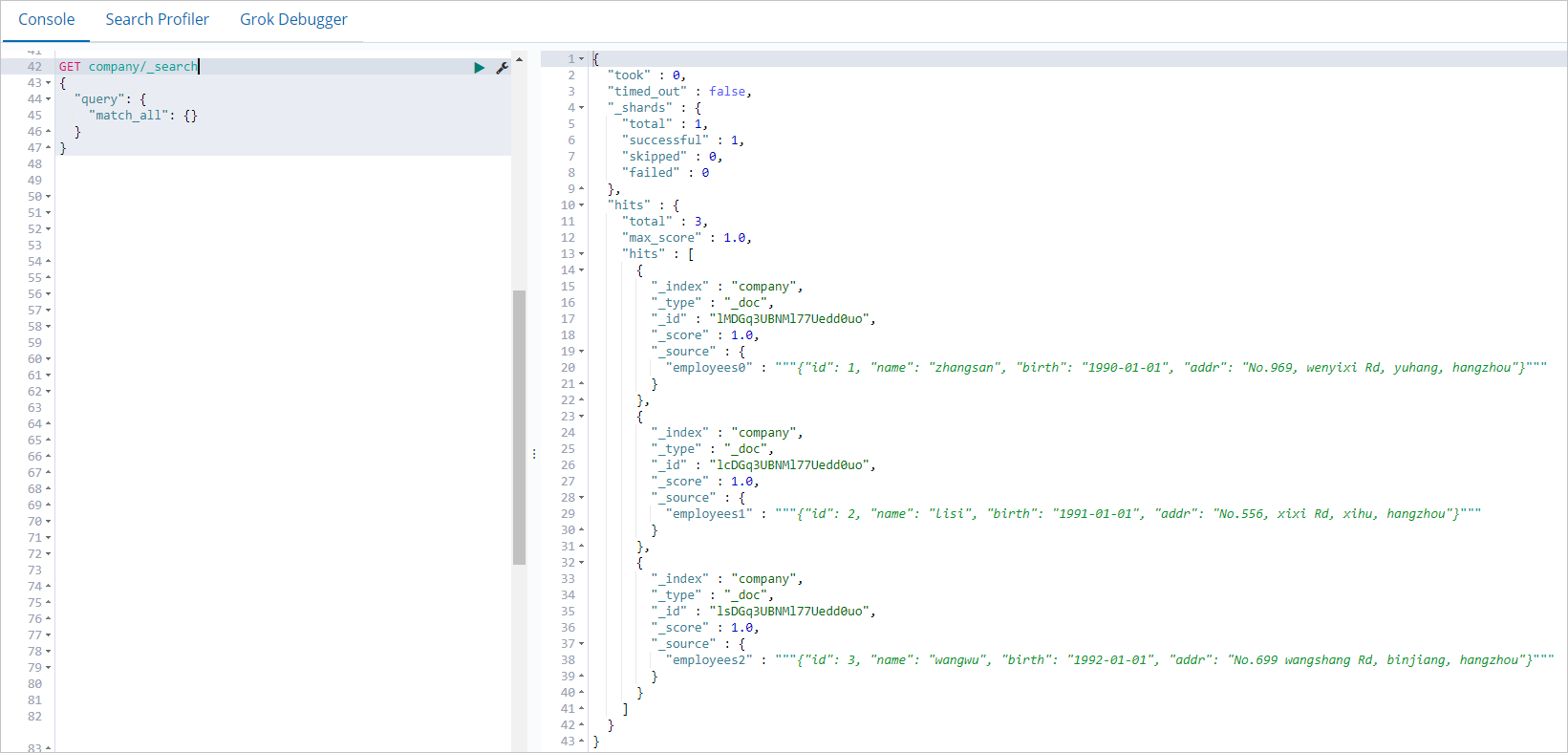
表示されるページの [コンソール] タブで、次のコマンドを実行して、Spark ジョブによって書き込まれたデータをクエリします。
GET company/_search { "query": { "match_all": {} } }コマンドが正常に実行されると、次の図に示す結果が返されます。
まとめ
このトピックでは、EMR クラスタで Spark ジョブを実行することにより、ES-Hadoop を使用して Alibaba Cloud Elasticsearch にデータを書き込んだり、Alibaba Cloud Elasticsearch からデータを読み取ったりする方法について説明しました。ES-Hadoop が Spark と統合されると、ES-Hadoop は Spark データセット、レジリエント分散データセット (RDD)、Spark Streaming、Scala、および Spark SQL をサポートします。要件に基づいて ES-Hadoop を構成できます。詳細については、「Apache Spark のサポート」をご参照ください。