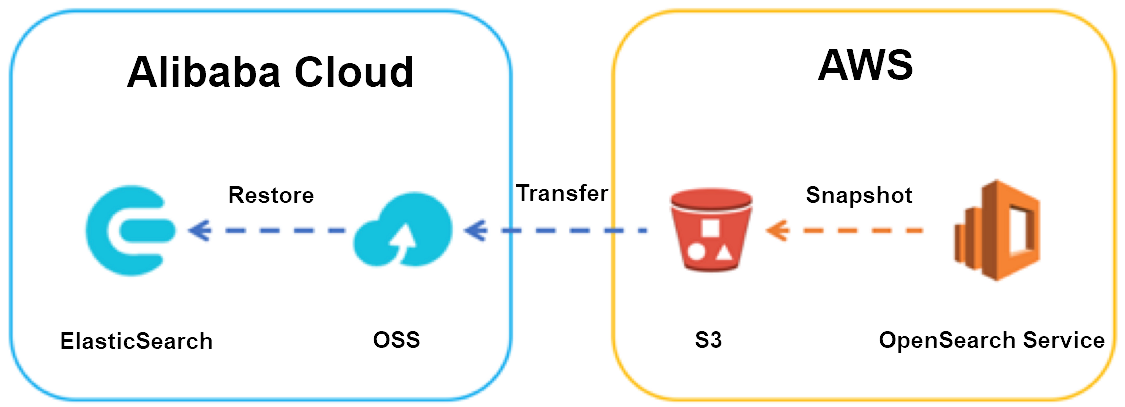
スナップショットと復元のメカニズムを使用して、Amazon OpenSearch Service ドメインから Alibaba Cloud Elasticsearch クラスターに Elasticsearch インデックスデータを移行します。
移行の概要
この移行では、Amazon Simple Storage Service (Amazon S3) と Object Storage Service (OSS) を中間ストレージとして使用し、Elasticsearch スナップショットを介してインデックスデータを転送します。大まかな手順は次のとおりです。
スナップショットリポジトリの作成:Amazon OpenSearch Service ドメインでスナップショットリポジトリを作成し、インデックスの完全なスナップショットを取得します。
スナップショットの転送:ossimport またはデータオンライン移行を使用して、スナップショットを S3 バケットから OSS バケットに転送します。
スナップショットリポジトリの登録:OSS バケットを指すスナップショットリポジトリを Alibaba Cloud Elasticsearch クラスターに登録します。
スナップショットの復元:スナップショットを Alibaba Cloud Elasticsearch クラスターに復元します。
増分変更の同期:切り替えまでスナップショット-転送-復元のサイクルを繰り返し、増分変更を同期します。
最終的な切り替え:書き込みを停止し、最終スナップショットを取得して、トラフィックを Alibaba Cloud Elasticsearch に切り替えることで、最終的な切り替えを実行します。
バージョンの互換性
移行先の Elasticsearch クラスターのバージョンは、移行元のクラスターバージョンと同じか、それ以降である必要があります。スナップショットは、1 つのメジャーバージョンに対してのみ前方互換性があります。
| ソーススナップショットバージョン | サポートされる復元ターゲット |
|---|---|
| Elasticsearch 1.x | Elasticsearch 2.x |
| Elasticsearch 2.x | Elasticsearch 5.x |
| Elasticsearch 5.x | Elasticsearch 6.x |
詳細については、「スナップショット復元のバージョンの互換性」をご参照ください。
このメカニズムは AWS に限定されません。 Amazon S3、Tencent Cloud Object Storage (COS)、またはその他のオブジェクトストレージサービスに保存されている Elasticsearch スナップショットは、OSS に転送して解凍できます。 詳細については、「データを移行する」および「手動スナップショットを作成し、手動スナップショットからデータを解凍する」をご参照ください。
前提条件
AWS 側
| 前提条件 | 説明 |
|---|---|
| Amazon OpenSearch Service ドメイン | 移行するインデックスを持つ実行中のドメイン。このガイドでは、シンガポールリージョンの Elasticsearch 5.5.2 を例として使用します。「Amazon OpenSearch Service ドメインの作成」をご参照ください。 |
| S3 バケット | 手動スナップショットを保存します。Amazon リソースネーム (ARN) をメモしておきます。例:arn:aws:s3:::eric-es-index-backups。標準の S3 料金が適用されます。 |
| IAM ロール | Amazon OpenSearch Service に S3 バケットへのアクセスを許可します。信頼関係では、Service 要素に es.amazonaws.com を指定する必要があります。 |
| IAM ポリシー | IAM ロールがバケットに対して実行できる S3 アクション (s3:ListBucket、s3:GetObject、s3:PutObject、s3:DeleteObject) を定義します。 |
| Python 環境 | スナップショットリポジトリ登録スクリプトの実行に必要です。requests および requests-aws4auth ライブラリをインストールします。 |
Alibaba Cloud 側
| 前提条件 | 説明 |
|---|---|
| Alibaba Cloud Elasticsearch クラスター | ソースと同じバージョン、またはそれ以降のバージョンで実行中のクラスター。本ガイドでは、中国 (杭州) リージョンの V5.5.3 を使用します。詳細については、「Create an Alibaba Cloud Elasticsearch cluster」をご参照ください。 |
| OSS バケット | スナップショットデータを受信します。本ガイドでは、中国 (杭州) リージョンに、標準ストレージクラスでアクセス制御リスト (ACL) が「プライベート」に設定されたバケットを使用します。詳細については、「Create buckets」をご参照ください。 |
| AccessKey ID および AccessKey Secret | Elasticsearch クラスターが OSS に対して認証を行うために使用します。 |
Amazon OpenSearch Service は、プライマリシャードの日次スナップショットを自動的に作成し、最大 14 日間無料で保持します。ただし、これらの自動スナップショットは、同じドメインにのみデータを復元できます。別のクラスターにデータを移行するには、手動スナップショットを取得する必要があります。
ステップ 1:AWS IAM 権限の設定
スナップショットリポジトリを登録する前に、IAM を設定して Amazon OpenSearch Service に S3 バケットへのアクセスを許可します。
IAM ロールの作成
IAM コンソールを開き、ロールを作成します。
Amazon OpenSearch Service は [ロールタイプの選択] ドロップダウンリストに表示されません。代わりに [Amazon EC2] を選択し、信頼関係を更新して
ec2.amazonaws.comをes.amazonaws.comに置き換えます。信頼関係を次のように設定します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "es.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
IAM ポリシーの作成とアタッチ
IAM ロールに S3 バケットへのアクセスを許可するポリシーを作成します。
<your-s3-bucket>をご利用のバケット名に置き換えます。{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:ListBucket" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::<your-s3-bucket>" ] }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::<your-s3-bucket>/*" ] } ] }ポリシーを IAM ロールにアタッチします。
ステップ 2:Amazon OpenSearch Service へのスナップショットリポジトリの登録
Amazon OpenSearch Service では、スナップショットリポジトリの登録に AWS リクエスト署名が必要なため、cURL コマンドは使用できません。代わりに、提供されている Python クライアントを使用してください。
register_snapshot_repository.py スクリプトをダウンロードします。
スクリプトのパラメーターを更新します。
S3 マネージドキーによるサーバーサイド暗号化を有効にするには、
settingsJSON に"server_side_encryption": trueを追加します。S3 バケットがap-southeast-1リージョンにある場合は、"region": "ap-southeast-1"を"endpoint": "s3.amazonaws.com"に置き換えます。パラメーター 説明 regionAmazon OpenSearch Service ドメインの AWS リージョン hostAmazon OpenSearch Service ドメインのエンドポイント aws_access_key_idご利用の IAM 認証情報 ID aws_secret_access_keyご利用の IAM 認証情報キー pathスナップショットリポジトリのパス dataS3 バケット名と IAM ロールの ARN 必要な Python ライブラリをインストールします。
pip install requests requests-aws4authスクリプトを実行してスナップショットリポジトリを登録します。
python register_snapshot_repository.py登録を検証します。Amazon OpenSearch Service ドメインの Kibana コンソールにログインし、左側のナビゲーションウィンドウで [Dev Tools] をクリックし、[コンソール] タブで次のコマンドを実行します。応答には、登録されたスナップショットリポジトリがリストされます。
GET _snapshot/<repository>/snapshot_1
ステップ 3:完全なスナップショットの作成
Kibana の [Dev Tools] コンソールで、またはコマンドラインから cURL を使用して、次のコマンドを実行します。
スナップショットを作成します。
<repository>をスナップショットリポジトリ名に、<index>を移行するインデックスに置き換えます。例 (moviesインデックスの場合):PUT _snapshot/<repository>/snapshot_1 { "indices": "<index>" }PUT _snapshot/eric-snapshot-repository/snapshot_movies_1 { "indices": "movies" }スナップショットのステータスを確認します。
stateフィールドがSUCCESSと表示されるまで待ちます。後で増分スナップショットを転送するために、start_time_in_millisとend_time_in_millisの値をメモしておきます。GET _snapshot/<repository>/snapshot_1S3 コンソールにスナップショットオブジェクトが表示されることを確認します。
ステップ 4:S3 から OSS へのスナップショットの転送
S3 バケットから OSS バケットにスナップショットオブジェクトを転送します。 詳細な手順については、「Amazon S3 から Alibaba Cloud OSS にデータを移行する」をご参照ください。
転送が完了したら、OSS コンソールにスナップショットオブジェクトが表示されることを確認します。
ステップ 5:Alibaba Cloud Elasticsearch でのスナップショットの復元
ご利用の Alibaba Cloud Elasticsearch クラスターの Kibana コンソールにログインします。詳細については、「Kibana コンソールへのログイン」をご参照ください。
左側のナビゲーションウィンドウで [Dev Tools] をクリックし、[コンソール] タブを開きます。
OSS バケットを指すスナップショットリポジトリを登録します。リポジトリ名は、Amazon OpenSearch Service に登録したものと一致する必要があります。プレースホルダーの値を置き換えます。例:
PUT _snapshot/<repository> { "type": "oss", "settings": { "endpoint": "http://oss-cn-hangzhou-internal.aliyuncs.com", "access_key_id": "<your-AccessKey-ID>", "secret_access_key": "<your-AccessKey-secret>", "bucket": "<your-oss-bucket>", "base_path": "<snapshot-directory-path>", "compress": true } }PUT _snapshot/eric-snapshot-repository { "type": "oss", "settings": { "endpoint": "http://oss-cn-hangzhou-internal.aliyuncs.com", "access_key_id": "your AccessKeyID", "secret_access_key": "your AccessKeySecret", "bucket": "eric-oss-aws-es-snapshot-s3", "base_path": "my/snapshot/directory", "compress": true } }スナップショットにアクセスできることを確認します。
GET _snapshot/<repository>/snapshot_1スナップショットを復元します。
POST _snapshot/<repository>/snapshot_1/_restore { "indices": "<index>" }復元が正常に完了したことを確認します。
GET <index>/_recovery
ステップ 6:増分変更の移行
ベースラインスナップショットを復元した後、スナップショット-転送-復元のサイクルを繰り返して増分変更を同期します。この例では、movies インデックスには最初に 3 つのドキュメントが含まれています。移行元のドメインにさらに 2 つのドキュメントを挿入すると、増分スナップショットが変更をキャプチャします。
増分スナップショットの作成
Amazon OpenSearch Service ドメインで、新しいスナップショットを作成します。
PUT _snapshot/<repository>/snapshot_2 { "indices": "<index>" }スナップショットのステータスを確認します。
GET _snapshot/<repository>/snapshot_2
増分スナップショットの転送
ossimport を使用して、新しいスナップショットオブジェクトのみを転送します。local_job.cfg ファイルで、isSkipExistFile を true に設定して、size と LastModifiedTime に基づいて OSS バケットに既に存在するオブジェクトをスキップします。
isSkipExistFile の値 | 動作 |
|---|---|
false (デフォルト) | 既存のオブジェクトを上書きします |
true | サイズと最終更新時刻が一致するオブジェクトをスキップします |
jobTypeがauditに設定されている場合、isSkipExistFileの設定は効果がありません。
詳細については、「ossimport の説明と設定」をご参照ください。
増分スナップショットの復元
復元する前にインデックスを閉じます。
POST /<index>/_closeインデックスが閉じていることを確認します。
GET <index>/_stats増分スナップショットを復元します。
POST _snapshot/<repository>/snapshot_2/_restore { "indices": "<index>" }インデックスを再度開きます。
POST /<index>/_openドキュメント数が移行元と一致することを確認します。この例では、
moviesインデックスには 5 つのドキュメント (元の 3 つ + 追加された 2 つ) が含まれている必要があります。GET <index>/_count
増分スナップショットを復元する前に、ターゲットインデックスを閉じてください。開いているインデックスに復元すると失敗します。
ステップ 7:最終的な切り替えの実行
Amazon OpenSearch Service ドメインの移行元インデックスに書き込むすべてのサービスを停止します。
Amazon OpenSearch Service ドメインで最終スナップショットを作成します。
PUT _snapshot/<repository>/snapshot_final { "indices": "<index>" }最終スナップショットを OSS に転送し、Alibaba Cloud Elasticsearch クラスターに復元します。「ステップ 6:増分変更の移行」で説明したのと同じ手順に従います。
アプリケーションのトラフィックを Alibaba Cloud Elasticsearch クラスターのエンドポイントに切り替えます。
移行結果の検証
復元後、データが完全かつ正確であることを確認します。
ドキュメント数の確認。両方のクラスターでドキュメント数を比較します。
GET <index>/_countインデックスのヘルス状態の確認。インデックスのステータスが
greenであることを確認します。GET _cluster/health/<index>リカバリステータスの確認。すべてのシャードが完全にリカバリされたことを確認します。
GET <index>/_recoveryデータのスポットチェック。いくつかのドキュメントをクエリして、データ整合性を確認します。
GET <index>/_search { "size": 5 }
よくある質問
OSS のスナップショットオブジェクトに関するエラーで復元が失敗するのはなぜですか?
これは通常、OSS のスナップショットオブジェクト名にスラッシュ (/) などの特殊文字が含まれている場合に発生します。ossbrowser を使用して、影響を受けるスナップショットオブジェクトを通常のフォルダに移動してから、復元を再試行してください。
cURL を使用して Amazon OpenSearch Service にスナップショットリポジトリを登録できますか?
いいえ。Amazon OpenSearch Service では AWS リクエスト署名が必要ですが、cURL はこれをサポートしていません。代わりに、requests および requests-aws4auth ライブラリを備えた Python クライアントを使用してください。
復元のたびにインデックスを閉じる必要がありますか?
増分復元の場合のみです。既に存在し、開いているインデックスに復元する場合は、まず POST /<index>/_close でインデックスを閉じ、復元が完了した後に POST /<index>/_open で再度開きます。