Alibaba Cloud Elasticsearch チームが開発した aliyun-timestream プラグインを使用すると、複雑なドメイン特化言語 (DSL) クエリを記述することなく、専用 API を介して時系列インデックスを管理できます。PromQL を使用してご利用のクラスターに保存されているメトリックデータをクエリし、時系列ストレージ向けに組み込まれた Elasticsearch のベストプラクティスを活用してディスク使用量を削減できます。
プラグインの概要については、「aliyun-timestream の概要」をご参照ください。完全な API リファレンスと Prometheus 連携については、「aliyun-timestream がサポートする API の概要」および「aliyun-timestream と Prometheus API の連携」をご参照ください。
aliyun-timestream を使用するタイミング
データが以下のすべての基準を満たす場合に、aliyun-timestream プラグインを使用します。
データがタイムスタンプ付きのメトリック測定値 (CPU 使用率、メモリ、ディスク I/O など) で構成されている。
データがほぼリアルタイムで、おおよそ
@timestamp順に書き込まれる。各データポイントは、ディメンションフィールドのセット (
clusterId、nodeId、namespaceなどのラベル) によって識別されます。PromQL または Elasticsearch アグリゲーションを使用してデータをクエリする予定がある。
aliyun-timestream を介して作成された時系列インデックスは、Elasticsearch の データストリーム上に構築されており、index.mode: time_series、aliyun-codec 圧縮プラグイン、およびディメンションベースのルーティングが自動的に構成されます。これは、通常のインデックスまたはデータストリームとはいくつかの重要な点で異なります。
時間ベースのバッキングインデックス: 同じタイムウィンドウからのデータは、
index.time_series.start_timeおよびindex.time_series.end_timeに基づいて、同じバッキングインデックスにルーティングされます。ディメンションベースのルーティング: 同じディメンション値を共有するすべてのデータポイントは、内部の
_tsidフィールドによって識別される同じシャードに保存されます。これにより、圧縮とクエリパフォーマンスが向上します。メトリックフィールドストレージ: メトリックフィールドはドキュメント値のみを保存し、転置インデックスデータは保存しないため、ディスク使用量が削減されます。
PromQL サポート: プラグインの Prometheus 互換 API を介して PromQL を使用してメトリックデータをクエリします。DSL は使用しません。
前提条件
開始する前に、以下を確認してください。
以下のバージョン要件のいずれかを満たす Standard Edition の Alibaba Cloud Elasticsearch クラスター。
クラスターバージョン V7.16 以降、およびカーネルバージョン V1.7.0 以降
クラスターバージョン V7.10、およびカーネルバージョン V1.8.0 以降
クラスターの作成手順については、「Alibaba Cloud Elasticsearch クラスターの作成」をご参照ください。
時系列インデックスの管理
時系列インデックスの作成
test_stream という名前の時系列インデックスを作成します。
PUT _time_stream/test_streamこれにより、Elasticsearch データストリーム (スタンドアロンインデックスではない) と、以下の設定を事前構成する .timestream_test_stream という名前のインデックステンプレートが作成されます。
| 設定 | 値 | 効果 |
|---|---|---|
index.mode | time_series | 時系列ストレージ向けに組み込まれた Elasticsearch のベストプラクティスで時系列モードを有効にします。 |
index.codec | ali | aliyun-codec インデックス圧縮プラグイン |
index.ali_codec_service.enabled | true | インデックス圧縮を有効にします。 |
index.doc_value.compression.default | zstd | zstd アルゴリズムを使用してカラム指向 (ドキュメント値) データを圧縮します。 |
index.postings.compression | zstd | zstd を使用して転置インデックスデータを圧縮します。 |
index.ali_codec_service.source_reuse_doc_values.enabled | true | ストレージを削減するために、ドキュメント値からのソース再利用を有効にします。 |
index.source.compression | zstd | zstd を使用して行指向 (ソース) データを圧縮します。 |
index.translog.durability | ASYNC | 非同期トランスログ書き込みを使用することで、書き込みレイテンシーを削減します。 |
index.refresh_interval | 10s | インデックスリフレッシュをバッチ処理して、書き込みスループットを向上させます。 |
index.routing_path | labels.* | ラベルフィールドに基づいてドキュメントをシャードにルーティングします。 |
インデックステンプレートは、2 つのフィールドカテゴリのマッピングも事前構成します。
ディメンションフィールド (
labels.*):keywordとしてマッピングされ、time_series_dimension: trueが設定されます。すべてのディメンションフィールドは、各時系列を一意に識別する内部の_tsidフィールドに結合されます。メトリックフィールド (
metrics.*):doubleまたはlongとしてマッピングされ、"index": falseが設定されます。ドキュメント値のみが保存され、転置インデックスデータは保存されません。
test_stream の完全な構成を表示します。
GET _time_stream/test_streamインデックステンプレートのカスタマイズ
インデックス作成時に template ボディを渡すことで、デフォルト設定をオーバーライドできます。以下の例は、一般的なカスタマイズを示しています。
プライマリシャードの数を設定します。
PUT _time_stream/test_stream { "template": { "settings": { "index": { "number_of_shards": "2" } } } }データモデル (フィールド命名規則) をカスタマイズします。
PUT _time_stream/test_stream { "template": { "settings": { "index": { "number_of_shards": "2" } } }, "time_stream": { "labels_fields": ["labels_*"], "metrics_fields": ["metrics_*"] } }
時系列インデックスの更新
test_stream のプライマリシャードの数を更新します。
POST _time_stream/test_stream/_update
{
"template": {
"settings": {
"index": {
"number_of_shards": "4"
}
}
}
}変更したいフィールドだけでなく、既存のすべての構成を更新リクエストボディに含めてください。フィールドを省略すると、デフォルトにリセットされます。GET _time_stream/test_stream を最初に実行して現在の完全な構成を取得し、必要なフィールドを変更してください。
更新後、新しい設定は現在のバッキングインデックスには適用されません。適用するには、インデックスをロールオーバーします。
POST test_stream/_rollover新しいバッキングインデックスが更新された設定で作成されます。元のバッキングインデックスは以前の設定を保持します。
時系列インデックスの削除
test_stream とそのすべてのデータを削除します。
DELETE _time_stream/test_streamこれにより、インデックス内のすべてのデータとその構成が削除されます。この操作は元に戻すことはできません。
時系列データの書き込みとクエリ
時系列インデックスは、データの書き込みと基本的なクエリに関して、通常の Elasticsearch インデックスと同じ方法で使用されます。
データの書き込み
bulk または index API を使用してドキュメントを書き込みます。各ドキュメントには、測定が行われた時刻に設定された @timestamp フィールドを含める必要があります。
POST test_stream/_doc
{
"@timestamp": 1630465208722,
"metrics": {
"cpu.idle": 79.67298116109929,
"disk_ioutil": 17.630910821570456,
"mem.free": 75.79973639970004
},
"labels": {
"disk_type": "disk_type2",
"namespace": "namespaces1",
"clusterId": "clusterId3",
"nodeId": "nodeId5"
}
}時間ベースのルーティングの仕組み
データストリーム内の各バッキングインデックスには、index.time_series.start_time および index.time_series.end_time によって定義された時間範囲があります。ドキュメントは、その時間範囲にドキュメントの @timestamp 値が含まれるバッキングインデックスに書き込まれます。
データストリームはこの時間範囲を自動的に管理します。ロールオーバー後、新しいバッキングインデックスは前のインデックスの終了時刻から引き継がれるため、すべてのバッキングインデックスはギャップなく連続した時間範囲をカバーします。
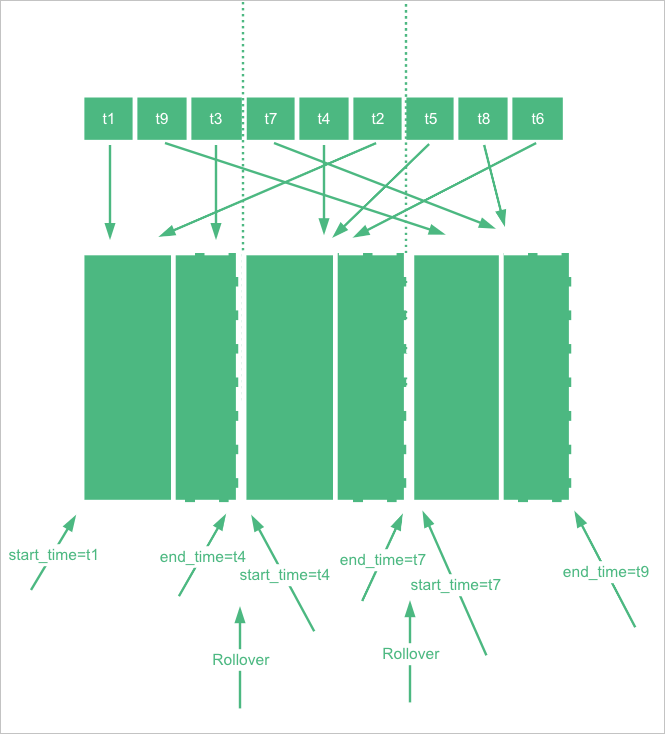
時間範囲の境界は協定世界時 (UTC) です。ご利用のアプリケーションが UTC + 08:00 で実行されている場合、それに応じて変換してください。たとえば、2022-06-21T00:00:00.000Z (UTC) は UTC + 08:00 の 2022-06-21T08:00:00.000 に対応します。
データのクエリ
test_stream 内のすべてのドキュメントを検索します。
GET test_stream/_searchインデックスの詳細を表示します。
GET _cat/indices/test_stream?v&s=iインデックス統計の表示
test_stream の統計 (シャードごとに追跡される時系列の数を含む) を取得します。
GET _time_stream/test_stream/_stats応答例:
{
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"time_stream_count" : 1,
"indices_count" : 1,
"total_store_size_bytes" : 19132,
"time_streams" : [
{
"time_stream" : "test_stream",
"indices_count" : 1,
"store_size_bytes" : 19132,
"tsid_count" : 2
}
]
}time_stream_count メトリックは、_tsid フィールドのドキュメント値を読み取ることで、プライマリシャードごとのユニークな時系列をカウントします。これは比較的にコストの高い操作です。コストを削減するには、以下を実行します。
読み取り専用インデックスの場合、カウントが一度だけ収集され、再度リフレッシュされないようにキャッシュポリシーを構成します。
アクティブなインデックスの場合、キャッシュはデフォルトで 5 分ごとにリフレッシュされます。この間隔は、
index.time_series.stats.refresh_intervalパラメーターで調整します。最小値は 1 分です。
Prometheus API を使用したデータのクエリ
aliyun-timestream プラグインは、/_time_stream/prom/{index_name} で Prometheus 互換クエリインターフェイスを公開しています。これを使用して Grafana または任意の Prometheus 互換ツールと連携できます。
Prometheus データソースの構成
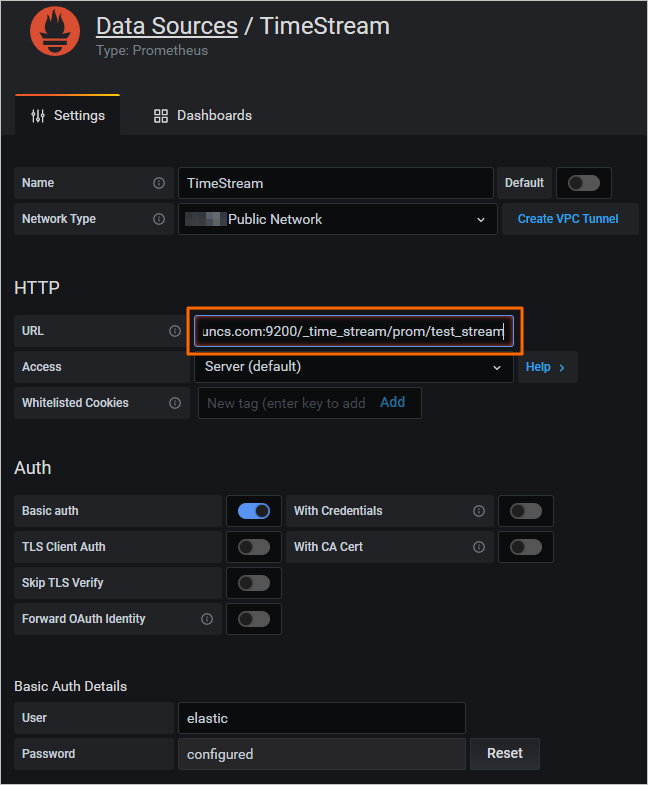
オプション 1: Grafana コンソール
Grafana コンソールで、Prometheus データソースを追加し、URL を /_time_stream/prom/test_stream に設定します。時系列インデックスは、Prometheus データソースとして直接利用可能になります。
オプション 2: カスタムフィールドプレフィックスとサフィックス
Prometheus API を介してクエリを実行する場合、プラグインはデフォルトでメトリックフィールドから metrics. プレフィックスを、ディメンションフィールドから labels. プレフィックスを削除します。
カスタムデータモデル (非デフォルトのフィールドプレフィックス) でインデックスを作成した場合、プレフィックスとサフィックスのマッピングを明示的に構成します。
PUT _time_stream/{name}
{
"time_stream": {
"labels_fields": "@labels.*_l",
"metrics_fields": "@metrics.*_m",
"label_prefix": "@labels.",
"label_suffix": "_l",
"metric_prefix": "@metrics.",
"metric_suffix": "_m"
}
}メタデータのクエリ
test_stream 内のすべてのメトリックフィールドを表示します。
GET /_time_stream/prom/test_stream/metadata応答例:
{
"status" : "success",
"data" : {
"cpu.idle" : [
{
"type" : "gauge",
"help" : "",
"unit" : ""
}
],
"disk_ioutil" : [
{
"type" : "gauge",
"help" : "",
"unit" : ""
}
],
"mem.free" : [
{
"type" : "gauge",
"help" : "",
"unit" : ""
}
]
}
}test_stream 内のすべてのディメンションフィールドを表示します。
GET /_time_stream/prom/test_stream/labels応答例:
{
"status" : "success",
"data" : [
"__name__",
"clusterId",
"disk_type",
"namespace",
"nodeId"
]
}特定のディメンションフィールドのすべての値を表示します。
GET /_time_stream/prom/test_stream/label/clusterId/values応答例:
{
"status" : "success",
"data" : [
"clusterId1",
"clusterId3"
]
}cpu.idle メトリックのすべての時系列を表示します。
GET /_time_stream/prom/test_stream/series?match[]=cpu.idle応答例:
{
"status" : "success",
"data" : [
{
"__name__" : "cpu.idle",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"clusterId" : "clusterId1",
"nodeId" : "nodeId2"
},
{
"__name__" : "cpu.idle",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"clusterId" : "clusterId1",
"nodeId" : "nodeId5"
},
{
"__name__" : "cpu.idle",
"disk_type" : "disk_type2",
"namespace" : "namespaces1",
"clusterId" : "clusterId3",
"nodeId" : "nodeId5"
}
]
}PromQL を使用したデータのクエリ
Prometheus インスタントクエリおよび範囲クエリ API を使用して、時系列インデックスに対して PromQL クエリを実行します。サポートされている PromQL 構文の詳細については、「aliyun-timestream の PromQL サポート」をご参照ください。
インスタントクエリ
GET /_time_stream/prom/test_stream/query?query=cpu.idle&time=1655769837time パラメーターは Unix 秒単位です。省略した場合、クエリは過去 5 分間のデータを返します。
応答例:
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId1",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"nodeId" : "nodeId2"
},
"value" : [
1655769837,
"79.672981161"
]
},
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId1",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"nodeId" : "nodeId5"
},
"value" : [
1655769837,
"79.672981161"
]
},
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId3",
"disk_type" : "disk_type2",
"namespace" : "namespaces1",
"nodeId" : "nodeId5"
},
"value" : [
1655769837,
"79.672981161"
]
}
]
}
}範囲クエリ
GET /_time_stream/prom/test_stream/query_range?query=cpu.idle&start=1655769800&end=16557699860&step=1m応答例:
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId1",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"nodeId" : "nodeId2"
},
"value" : [
[
1655769860,
"79.672981161"
]
]
},
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId1",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"nodeId" : "nodeId5"
},
"value" : [
[
1655769860,
"79.672981161"
]
]
},
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId3",
"disk_type" : "disk_type2",
"namespace" : "namespaces1",
"nodeId" : "nodeId5"
},
"value" : [
[
1655769860,
"79.672981161"
]
]
}
]
}
}ダウンサンプリングの構成
ダウンサンプリングは、古い時系列データの解像度を下げて、広範囲の時間にわたるクエリを高速化します。プラグインは、アグリゲーションクエリの fixed_interval 値に基づいて、最も適切なダウンサンプリングインデックスを自動的に選択します。
時系列インデックスの作成時にダウンサンプリング間隔を構成します。以下の例では、1 分、10 分、60 分の 3 つのダウンサンプリング間隔を構成しています。
PUT _time_stream/test_stream
{
"time_stream": {
"downsample": [
{
"interval": "1m"
},
{
"interval": "10m"
},
{
"interval": "60m"
}
]
}
}データが書き込まれ、元のバッキングインデックスがロールオーバーされた後、プラグインは元のバッキングインデックスからダウンサンプリングインデックスを自動的に生成します。ダウンサンプリングは、現在の時刻がインデックスの end_time から少なくとも 2 時間経過したときに開始されます。
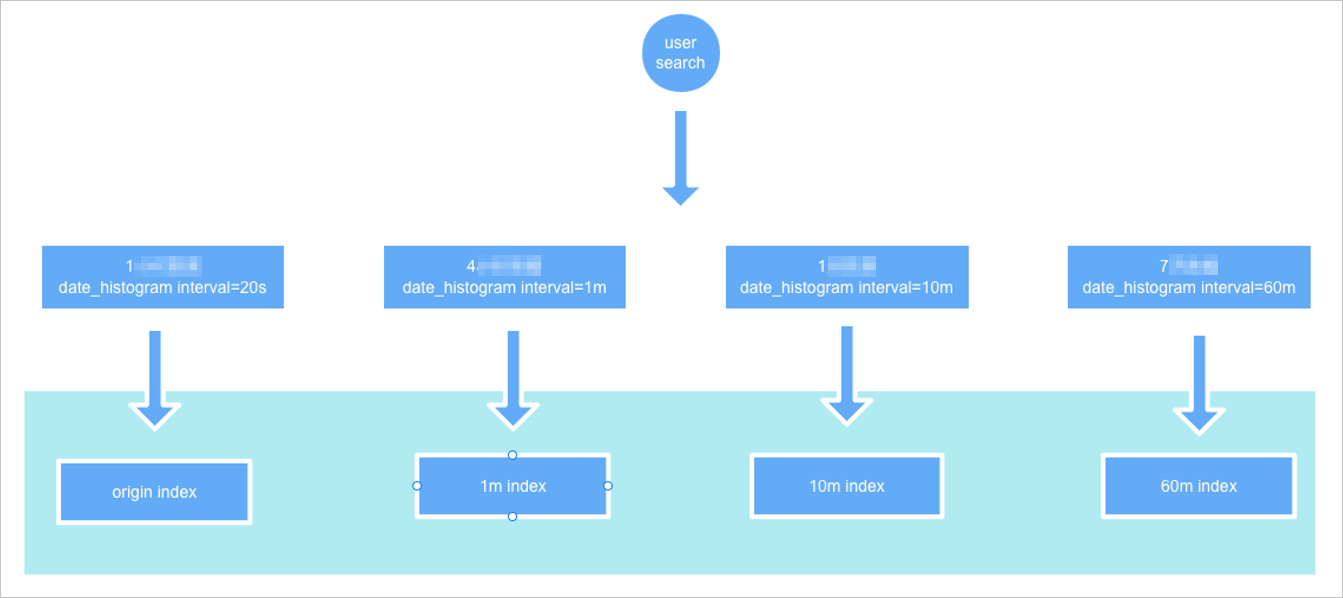
自動インデックス選択の仕組み
アグリゲーションクエリを実行するときは、元のインデックス名を渡し、date_histogram アグリゲーションで fixed_interval を指定します。プラグインは、fixed_interval の倍数である、最高の時間精度を持つダウンサンプリングインデックスを選択します。
たとえば、fixed_interval が 120m で、ダウンサンプリング間隔が 1m、10m、60m の場合、プラグインは 60m ダウンサンプリングインデックスをクエリします。
fixed_interval: 120m を使用したクエリ例:
GET test_stream/_search?size=0&request_cache=false
{
"aggs": {
"1": {
"terms": {
"field": "labels.disk_type",
"size": 10
},
"aggs": {
"2": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "120m"
}
}
}
}
}
}応答例 (60m ダウンサンプリングインデックスをクエリ):
{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"1" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "disk_type2",
"doc_count" : 9,
"2" : {
"buckets" : [
{
"key_as_string" : "2022-06-20T06:00:00.000Z",
"key" : 1655704800000,
"doc_count" : 9
}
]
}
}
]
}
}
}hits.total.value が 1 であることは、1 つのダウンサンプリングされたレコードが返されたことを意味します。アグリゲーションの doc_count が 9 であることは、9 つの元のデータポイントがそのレコードにロールアップされたことを示しており、クエリが元のインデックスではなくダウンサンプリングインデックスにヒットしたことを確認できます。
比較として、fixed_interval を 20s に設定すると、元のインデックスがクエリされ、hits.total.value: 9 が返され、doc_count: 9 と一致します。
ダウンサンプリングインデックスは、データが構成された間隔に基づいてタイムバケットに集約されることを除いて、元のインデックスと同じ設定とマッピングを持ちます。
デモインデックスを使用したダウンサンプリングのテスト
以下のプロシージャは、手動で制御された時間範囲を使用して、ダウンサンプリングの完全なライフサイクルを示します。これはテストと検証に役立ちます。本番環境では、プラグインはロールオーバー後にダウンサンプリングを自動的にトリガーします。
固定された時間範囲とダウンサンプリング構成を持つインデックスを作成します。
start_timeとend_timeの値は過去のタイムウィンドウをシミュレートするため、ダウンサンプリングトリガー条件 (現在の時刻がインデックスのend_timeから少なくとも 2 時間経過している) はすぐに満たされます。重要このステップの後、
GET {index}/_settingsを実行してend_timeを確認してください。システムはデフォルトで 5 分ごとにend_timeを調整します。end_timeが更新される前に次のステップに進んでください。PUT _time_stream/test_stream { "template": { "settings": { "index.time_series.start_time": "2022-06-20T00:00:00.000Z", "index.time_series.end_time": "2022-06-21T00:00:00.000Z" } }, "time_stream": { "downsample": [ { "interval": "1m" }, { "interval": "10m" }, { "interval": "60m" } ] } }@timestampが[start_time, end_time)範囲内の値に設定されたドキュメントを書き込みます。POST test_stream/_doc { "@timestamp": 1655706106000, "metrics": { "cpu.idle": 79.67298116109929, "disk_ioutil": 17.630910821570456, "mem.free": 75.79973639970004 }, "labels": { "disk_type": "disk_type2", "namespace": "namespaces1", "clusterId": "clusterId3", "nodeId": "nodeId5" } }インデックスから
start_timeとend_timeを削除し、ダウンサンプリング構成を保持します。POST _time_stream/test_stream/_update { "time_stream": { "downsample": [ { "interval": "1m" }, { "interval": "10m" }, { "interval": "60m" } ] } }インデックスをロールオーバーします。
POST test_stream/_rolloverロールオーバーが完了した後、生成されたダウンサンプリングインデックスを表示します。
GET _cat/indices/test_stream?v&s=i期待される出力:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .ds-test_stream-2022.06.21-000001 vhEwKIlwSGO3ax4RKn**** 1 1 9 0 18.5kb 12.1kb green open .ds-test_stream-2022.06.21-000001_interval_10m r9Tsj0v-SyWJDc64oC**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000001_interval_1h cKsAlMK-T2-luefNAF**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000001_interval_1m L6ocasDFTz-c89KjND**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000002 42vlHEFFQrmMAdNdCz**** 1 1 0 0 452b 226b3 つのダウンサンプリングインデックス (
_interval_1m、_interval_10m、_interval_1h) は、新しいバッキングインデックス (000002) と並行して作成されます。
次のステップ
aliyun-timestream がサポートする API の概要 — ダウンサンプリング API の使用上の注意を含む完全な API リファレンス
aliyun-timestream と Prometheus API の連携 — 完全な Prometheus API 連携ガイドと PromQL サポートの詳細