データ開発およびタスク実行中に AccessKey やパスワードなどの機密情報をプレーンテキストで保存すると、セキュリティリスクが生じます。暗号文管理機能を使用すると、機密情報を暗号化して保存できます。その後、データ開発中およびセッション構成で暗号化された情報を動的に参照できます。このアプローチは、データ漏洩を防ぎ、メンテナンス効率を向上させるのに役立ちます。
暗号文の作成
暗号文管理ページに移動します。
E-MapReduce コンソールにログインします。
左側のナビゲーションウィンドウで、[EMR Serverless > Spark] を選択します。
[Spark] ページで、ターゲットワークスペースの名前をクリックします。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある [Ciphertext Management] をクリックします。
[Ciphertext Management] ページで、[Add Ciphertext] をクリックします。
[Add Ciphertext] ページで、次のパラメーターを設定し、[Confirm] をクリックします。
パラメーター
説明
変数名
変数名は、同じワークスペース内で一意である必要があります。作成後に変更することはできません。
暗号文
暗号文では大文字と小文字が区別されます。作成後に変更したり、再度表示したりすることはできません。
暗号文の使用
Notebook での使用
Notebook ジョブでは、emrssutils.utils ライブラリで暗号文を使用できます。DPI エンジンのバージョンは、esr-2.8.0、esr-3.4.0、esr-4.4.0、またはそれ以降のバージョンである必要があります。
例
ライブラリをインポートし、暗号文をロードします。
# 暗号文を取得するためのサンプルコード import emrssutils.utils # 復号された値を動的に取得 password = emrssutils.utils.get_secret(key='<variable_name>')暗号文を参照します。
# 暗号文を参照するためのサンプルコード df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://<jdbc_url>") \ .option("dbtable", "<db>.<table>") \ .option("user", "<username>") \ .option("password", password) \ # 暗号文を参照 .load() df.show()
Spark 構成での使用
セッションまたはバッチジョブの Spark 構成では、暗号文に ${secret_values.variable_name} というフォーマットを使用します。
例
MaxCompute からのデータの読み取りまたは MaxCompute へのデータの書き込みを行う場合、まず AccessKey を暗号文管理に追加します。その後、SQL セッションの Spark 構成で暗号文を使用します。詳細については、「MaxCompute からの読み取りと MaxCompute への書き込み」をご参照ください。
spark.sql.catalog.odps org.apache.spark.sql.execution.datasources.v2.odps.OdpsTableCatalog
spark.sql.extensions org.apache.spark.sql.execution.datasources.v2.odps.extension.OdpsExtensions
spark.sql.sources.partitionOverwriteMode dynamic
spark.hadoop.odps.tunnel.quota.name pay-as-you-go
spark.hadoop.odps.project.name <project_name>
spark.hadoop.odps.end.point https://service.cn-hangzhou-vpc.maxcompute.aliyun-inc.com/api
spark.hadoop.odps.access.id <accessId>
# 暗号文を参照
spark.hadoop.odps.access.key ${secret_values.AccessKey} バッチジョブまたはストリームジョブでの使用
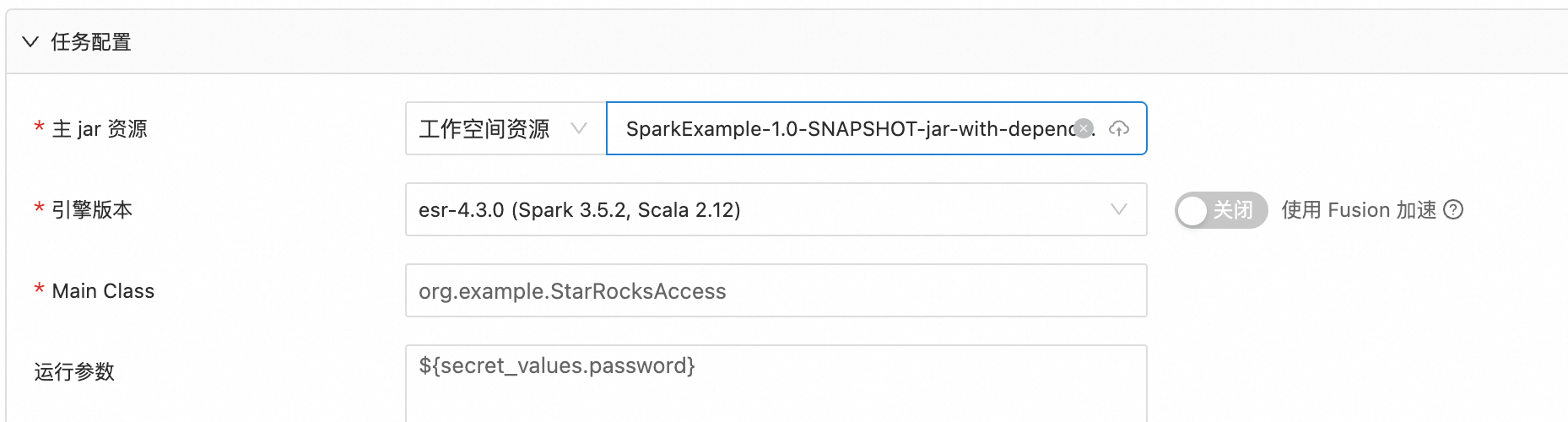
バッチジョブまたはストリームジョブの実行時パラメーターには、${secret_values.variable_name} というフォーマットで暗号文を使用できます。
例
JAR バッチジョブを作成するときに、関連する機密情報を暗号文管理に追加できます。その後、実行時パラメーターで ${secret_values.variable_name} というフォーマットを使用して暗号文を参照します。