Apache Airflow は、開発者がデータパイプラインの実行をオーケストレーション、スケジュール、およびモニターできるようにする、強力なワークフロー自動化およびスケジューリングツールです。EMR Serverless Spark は、大規模なデータ処理ジョブを処理するためのサーバーレスコンピューティング環境を提供します。このトピックでは、Apache Airflow を使用して EMR Serverless Spark へのジョブの自動送信を有効にする方法について説明します。このアプローチは、ジョブのスケジューリングと実行を自動化して、データ処理ジョブをより効率的に管理するのに役立ちます。
背景情報
Apache Livy は、RESTful API を呼び出すことによって Spark と対話します。これにより、Spark とアプリケーションサーバー間の通信の複雑さが大幅に簡素化されます。Livy API の詳細については、「REST API」をご参照ください。
Apache Airflow を使用すると、必要に応じて Livy Operator または EmrServerlessSparkStartJobRunOperator を使用して EMR Serverless Spark にジョブを送信できます。要件に基づいてメソッドを選択できます。
メソッド | シナリオ |
Apache Airflow のオープンソース Operator を使用して Serverless Spark にジョブを送信する場合は、この方法を選択できます。 | |
EmrServerlessSparkStartJobRunOperator は、EMR Serverless Spark が Apache Airflow にジョブを送信するために提供する専用コンポーネントです。EmrServerlessSparkStartJobRunOperator は、Apache Airflow の有向非巡回グラフ (DAG) メカニズムに深く統合されており、ジョブのオーケストレーションとスケジューリングを容易にします。 新しいプロジェクトを使用する場合、または EMR Serverless Spark を完全にベースとしてデータを処理する場合は、パフォーマンスを向上させ、運用の複雑さを軽減するためにこの方法をお勧めします。 |
前提条件
Airflow がインストールされ、開始されていること。詳細については、「Airflow のインストール」をご参照ください。
ワークスペースが作成されていること。詳細については、「ワークスペースの作成」をご参照ください。
使用上の注意
EmrServerlessSparkStartJobRunOperator 操作を呼び出してジョブログをクエリすることはできません。ジョブログを表示するには、EMR Serverless Spark ページに移動し、ジョブ実行 ID でログを表示したいジョブ実行を見つける必要があります。その後、ジョブ詳細ページの [ログ] タブ、または [Spark UI] の Spark Jobs ページでジョブログを確認および分析できます。
方法 1: Livy Operator を使用してジョブを送信する
ステップ 1: Livy ゲートウェイとトークンを作成する
Livy ゲートウェイを作成して開始します。
Gateways ページに移動します。
EMR コンソールにログインします。
左側のナビゲーションウィンドウで、 を選択します。
[Spark] ページで、対象のワークスペースの名前をクリックします。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウの をクリックします。
[Livy ゲートウェイ] タブをクリックします。
[Livy ゲートウェイ] ページで、[Livy ゲートウェイの作成] をクリックします。
[ゲートウェイの作成] ページで、[名前] (例: Livy-gateway) を入力し、[作成] をクリックします。
必要に応じて他のパラメーターを構成できます。詳細については、「ゲートウェイ管理」をご参照ください。
[Livy ゲートウェイ] ページで、作成したゲートウェイを見つけ、[アクション] 列の [開始] をクリックします。
トークンを作成します。
[ゲートウェイ] ページで、Livy-gateway を見つけ、[アクション] 列の [トークン] をクリックします。
[トークンの作成] をクリックします。
[トークンの作成] ダイアログボックスで、[名前] (例: Livy-token) を入力し、[OK] をクリックします。
トークンをコピーします。
重要トークンが作成されたら、すぐにトークンをコピーする必要があります。ページを離れると、トークンは表示できなくなります。トークンが有効期限切れになったり、紛失したりした場合は、トークンをリセットするか、新しいトークンを作成してください。
ステップ 2: Apache Airflow を構成する
次のコマンドを実行して、Apache Airflow に Apache Livy をインストールします:
pip install apache-airflow-providers-apache-livy接続を追加します。
UI を使用する
Apache Airflow で [livy_default] という名前のデフォルト接続を見つけて、接続を変更します。または、Apache Airflow の Web UI で手動で接続を追加することもできます。詳細については、「UI を使用した接続の作成」をご参照ください。
これには、次の情報が含まれます:
ホスト: ゲートウェイの エンドポイント を入力します。
スキーマ: https と入力します。
追加: JSON 文字列を入力します。
x-acs-spark-livy-tokenは、前のステップでコピーしたトークンを示します。{ "x-acs-spark-livy-token": "6ac**********kfu" }
CLI を使用する
Airflow コマンドラインインターフェイス (CLI) を使用してコマンドを実行し、接続を追加します。詳細については、「接続の作成」をご参照ください。
airflow connections add 'livy_default' \ --conn-json '{ "conn_type": "livy", "host": "pre-emr-spark-livy-gateway-cn-hangzhou.data.aliyun.com/api/v1/workspace/w-xxxxxxx/livycompute/lc-xxxxxxx", # ゲートウェイのエンドポイント。 "schema": "https", "extra": { "x-acs-spark-livy-token": "6ac**********kfu" # 前のステップでコピーしたトークン。 } }'
ステップ 3: DAG を構成してジョブを送信する
Apache Airflow では、有向非巡回グラフ (DAG) を使用してジョブの実行モードを宣言できます。次のサンプルコードは、Apache Airflow の LivyOperator を使用して Spark ジョブを実行する方法を示しています。
Object Storage Service (OSS) から取得した Python スクリプトファイルを実行します。
from datetime import timedelta, datetime
from airflow import DAG
from airflow.providers.apache.livy.operators.livy import LivyOperator
default_args = {
'owner': 'aliyun',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
# DAG の開始
livy_operator_sparkpi_dag = DAG(
dag_id="livy_operator_sparkpi_dag", # DAG の一意の ID。
default_args=default_args,
schedule_interval=None,
start_date=datetime(2024, 5, 20),
tags=['example', 'spark', 'livy'],
catchup=False
)
# LivyOperator で livy タスクを定義する
# 必要に応じて file の値を置き換えます。
livy_sparkpi_submit_task = LivyOperator(
file="oss://<YourBucket>/jars/spark-examples_2.12-3.3.1.jar",
class_name="org.apache.spark.examples.SparkPi",
args=['1000'],
driver_memory="1g",
driver_cores=1,
executor_memory="1g",
executor_cores=2,
num_executors=1,
name="LivyOperator SparkPi",
task_id="livy_sparkpi_submit_task",
dag=livy_operator_sparkpi_dag,
)
livy_sparkpi_submit_task
次の表にパラメーターを示します。
パラメーター | 説明 |
| DAG の一意の ID。ID を使用して、異なる DAG を区別できます。 |
| DAG がスケジュールされるスケジューリング間隔。 |
| DAG のスケジュールが開始される日付。 |
| DAG に追加されたタグ。これは、DAG の分類と検索に役立ちます。 |
| 実行されていない過去のジョブを実行するかどうかを指定します。このパラメーターを |
| Spark ジョブに対応するファイルパス。この例では、このパラメーターは OSS にアップロードされた JAR パッケージのパスに設定されています。必要に応じてこのパラメーターを構成できます。OSS にファイルをアップロードする方法の詳細については、「単純なアップロード」をご参照ください。 |
| JAR パッケージのメインクラス名。 |
| Spark ジョブのコマンドライン引数。 |
| ドライバーのメモリサイズとコア数。 |
| 各エグゼキュータのメモリサイズとコア数。 |
| エグゼキュータの数。 |
| Spark ジョブの名前。 |
| Airflow タスクの一意の識別子。 |
| タスクを DAG に関連付けます。 |
方法 2: EmrServerlessSparkStartJobRunOperator を使用してジョブを送信する
ステップ 1: Apache Airflow を構成する
airflow_alibaba_provider-0.0.3-py3-none-any.whl をダウンロードします。
Airflow の各ノードに airflow-alibaba-provider プラグインをインストールします。
airflow-alibaba-provider プラグインは EMR Serverless Spark によって提供されます。これには、EMR Serverless Spark にジョブを送信するために使用される EmrServerlessSparkStartJobRunOperator コンポーネントが含まれています。
pip install airflow_alibaba_provider-0.0.3-py3-none-any.whl接続を追加します。
CLI を使用する
Airflow CLI を使用してコマンドを実行し、接続を確立します。詳細については、「接続の作成」をご参照ください。
airflow connections add 'emr-serverless-spark-id' \ --conn-json '{ "conn_type": "emr_serverless_spark", "extra": { "auth_type": "AK", # AccessKey ペアは認証に使用されます。 "access_key_id": "<yourAccesskeyId>", # Alibaba Cloud アカウントの AccessKey ID。 "access_key_secret": "<yourAccesskeyKey>", # Alibaba Cloud アカウントの AccessKey Secret。 "region": "<yourRegion>" } }'UI を使用する
Airflow Web UI で手動で接続を作成できます。詳細については、「UI を使用した接続の作成」をご参照ください。
[接続の追加] ページで、パラメーターを構成します。
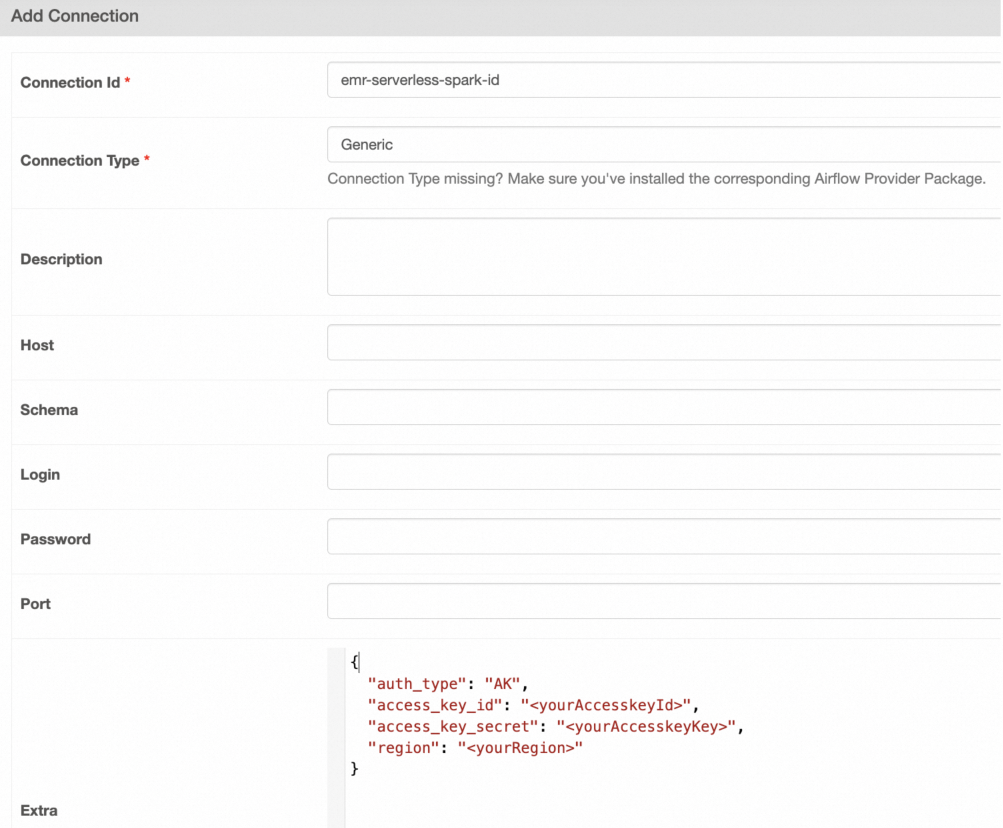
次の表にパラメーターを示します。
パラメーター
説明
Connection Id
接続 ID。この例では、emr-serverless-spark-id と入力します。
Connection Type
接続タイプ。この例では、[Generic] を選択します。Generic が利用できない場合は、[Email] を選択することもできます。
Extra
追加の構成。この例では、次の内容を入力します:
{ "auth_type": "AK", # AccessKey ペアは認証に使用されます。 "access_key_id": "<yourAccesskeyId>", # Alibaba Cloud アカウントの AccessKey ID。 "access_key_secret": "<yourAccesskeyKey>", # Alibaba Cloud アカウントの AccessKey Secret。 "region": "<yourRegion>" }
ステップ 2: DAG を構成する
Apache Airflow では、有向非巡回グラフ (DAG) を使用してジョブの実行モードを宣言できます。次のサンプルコードは、EmrServerlessSparkStartJobRunOperator を使用して Apache Airflow でさまざまな種類の Spark ジョブを実行する方法の例を示しています。
JAR パッケージを送信する
Airflow タスクを使用して、プリコンパイルされた Spark JAR ジョブを EMR Serverless Spark に送信します。
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# default_args によって提供される不足している引数を無視します
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_jar"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_jar = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_jar",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-7e2f1750c6b3****",
resource_queue_id="root_queue",
code_type="JAR",
name="airflow-emr-spark-jar",
entry_point="oss://<YourBucket>/spark-resource/examples/jars/spark-examples_2.12-3.3.1.jar",
entry_point_args=["1"],
spark_submit_parameters="--class org.apache.spark.examples.SparkPi --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_jar
SQL ファイルを送信する
Airflow DAG で SQL コマンドを実行します。
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# default_args によって提供される不足している引数を無視します
# mypy: disable-error-code="call-arg"
ENV_ID = os.environ.get("SYSTEM_TESTS_ENV_ID")
DAG_ID = "emr_spark_sql"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_sql = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_sql",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-7e2f1750c6b3****",
resource_queue_id="root_queue",
code_type="SQL",
name="airflow-emr-spark-sql",
entry_point=None,
entry_point_args=["-e","show tables;show tables;"],
spark_submit_parameters="--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None,
)
emr_spark_sql
OSS から SQL ファイルを送信する
OSS から取得した SQL スクリプトファイルを実行します。
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# default_args によって提供される不足している引数を無視します
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_sql_2"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_sql_2 = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_sql_2",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-ae42e9c92927****",
resource_queue_id="root_queue",
code_type="SQL",
name="airflow-emr-spark-sql-2",
entry_point="",
entry_point_args=["-f", "oss://<YourBucket>/spark-resource/examples/sql/show_db.sql"],
spark_submit_parameters="--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_sql_2
OSS から Python スクリプトを送信する
OSS から取得した Python スクリプトファイルを実行します。
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# default_args によって提供される不足している引数を無視します
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_python"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_python = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_python",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-ae42e9c92927****",
resource_queue_id="root_queue",
code_type="PYTHON",
name="airflow-emr-spark-python",
entry_point="oss://<YourBucket>/spark-resource/examples/src/main/python/pi.py",
entry_point_args=["1"],
spark_submit_parameters="--conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_python
次の表にパラメーターを示します。
パラメーター | タイプ | 説明 |
|
| Airflow タスクの一意の識別子。 |
|
| Airflow と EMR Serverless Spark 間の接続の ID。 |
|
| EMR Spark ジョブが作成されるリージョン。 |
|
| Airflow がジョブの状態をクエリする間隔。単位: 秒。 |
|
| EMR Spark ジョブが属するワークスペースの一意の識別子。 |
|
| EMR Spark ジョブが使用するリソースキューの ID。 |
|
| ジョブタイプ。SQL、Python、および JAR ジョブがサポートされています。entry_point パラメーターの意味は、ジョブタイプによって異なります。 |
|
| EMR Spark ジョブの名前。 |
|
| ジョブを開始するために使用されるファイルの場所。JAR、SQL、および Python ファイルがサポートされています。このパラメーターの意味は |
|
| Spark アプリケーションに渡されるパラメーター。 |
|
|
|
|
| ジョブが実行される環境。このパラメーターを True に設定すると、ジョブは本番環境で実行されます。この場合、 |
|
| EMR Spark エンジンのバージョン。デフォルト値: esr-2.1-native。これは、ネイティブランタイムで Spark 3.3.1 と Scala 2.12 を実行するエンジンを示します。 |