Apache Zeppelin は、Web UI でコードを記述し、クエリを実行し、データの可視化と分析を実行できるインタラクティブな開発環境を提供します。このトピックでは、Apache Zeppelin 用の Livy Interpreter を使用して E-MapReduce (EMR) Serverless Spark に接続し、インタラクティブな開発環境を効率的に構築および最適化する方法について説明します。
前提条件
EMR Serverless Spark ワークスペースが作成されていること。詳細については、「ワークスペースを作成する」をご参照ください。
Apache Zeppelin がインストールされ、起動されていること。詳細については、「Apache Zeppelin 公式ドキュメント」をご参照ください。
手順
ステップ 1: ゲートウェイとトークンを作成する
ゲートウェイを作成して起動します。
[ゲートウェイ] ページに移動します。
EMR コンソール にログインします。
左側のナビゲーションウィンドウで、 を選択します。
[Spark] ページで、目的のワークスペースを見つけ、ワークスペースの名前をクリックします。
[EMR Serverless Spark] ページの左側のナビゲーションウィンドウで、 を選択します。
[ゲートウェイ] ページで、[Livy ゲートウェイ] タブをクリックします。
[Livy ゲートウェイ] タブで、[Livy ゲートウェイの作成] をクリックします。
Livy ゲートウェイの作成ページで、[名前] パラメーターを構成し、[作成] をクリックします。この例では、[名前] パラメーターを Livy-gateway に設定します。
ビジネス要件に基づいて他のパラメーターを構成できます。詳細については、「ゲートウェイを管理する」をご参照ください。
[Livy ゲートウェイ] タブで、作成したゲートウェイを見つけ、[アクション] 列の [開始] をクリックします。
トークンを作成します。
[ゲートウェイ] ページで、ゲートウェイ Livy-gateway を見つけ、[トークン] 列の [アクション] をクリックします。
[トークン] タブで、[トークンの作成] をクリックします。
[トークンの作成] ダイアログボックスで、[名前] パラメーターを構成し、[OK] をクリックします。
トークンをコピーします。
重要トークンを作成したら、すぐにコピーする必要があります。ページを離れると、トークンを表示できなくなります。トークンの有効期限が切れた場合、またはトークンを紛失した場合は、トークンをリセットするか、別のトークンを作成します。
ステップ 2: Apache Zeppelin 用の Livy Interpreter を構成する
Apache Zeppelin にログインし、右上隅のユーザー名をクリックして、ドロップダウンリストから [Interpreter] を選択します。

右上隅の [+ 作成] をクリックし、必要なパラメーターを設定してインタープリターを作成します。
パラメーター
説明
インタープリター名
mylivy などのカスタム名を入力します。
インタープリターグループ
このパラメーターを [livy] に設定します。
[インタープリターグループ] パラメーターを [livy] に設定した後、必要なパラメーターを構成します。
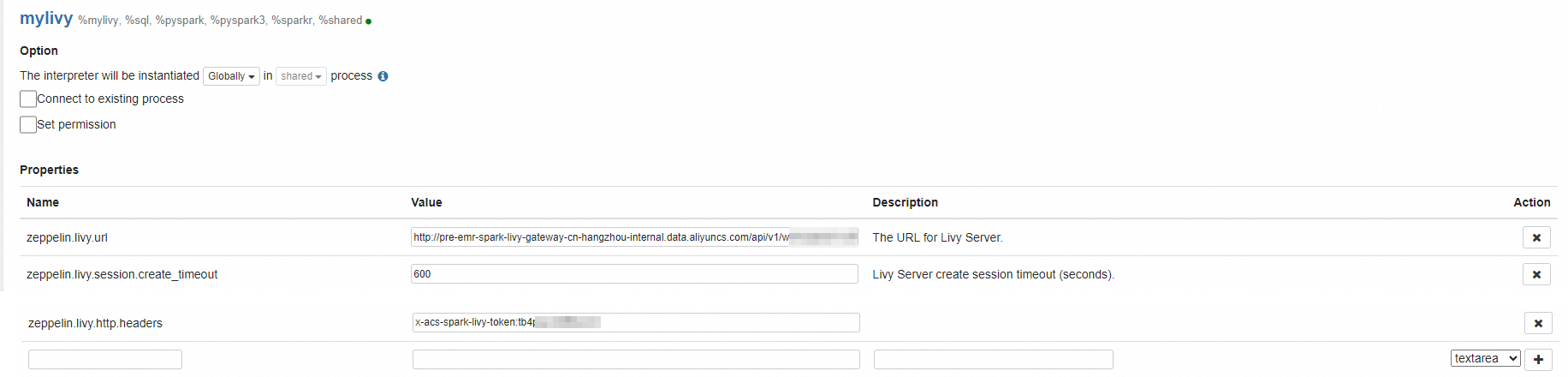
次の表に、必要なパラメーターを示します。ビジネス要件に基づいて他のパラメーターも構成できます。詳細については、「Apache Zeppelin 公式ドキュメント」をご参照ください。
パラメーター
説明
zeppelin.livy.url
Livy ゲートウェイの URL。URL を
http://{endpoint}形式で入力します。{endpoint}は、作成した Livy ゲートウェイの [内部エンドポイント] を示します。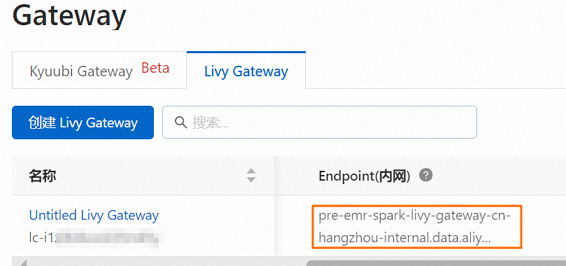
zeppelin.livy.session.create_timeout
Apache Zeppelin がセッションを作成する最大待機時間。単位:秒。このパラメーターを 600 に設定することをお勧めします。
zeppelin.livy.http.headers
HTTP リクエストのカスタム ヘッダー。
 アイコンをクリックして構成を追加し、
アイコンをクリックして構成を追加し、x-acs-spark-livy-token:{token}と入力する必要があります。{token}は、[トークン管理] タブで作成したトークンです。ページの下部にある [保存] をクリックして設定を保存します。
ステップ 3: データ分析用のノートブックを作成する
上部のナビゲーションバーで、[ノートブック] をクリックします。次に、[新しいノートの作成] を選択します。
カスタムノート名を入力し、[デフォルトのインタープリター] ドロップダウンリストから mylivy を選択します。
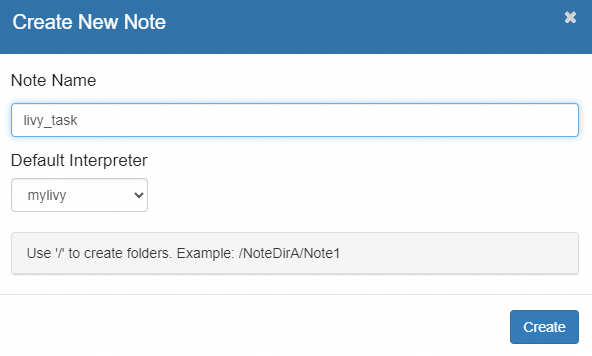
[作成] をクリックします。
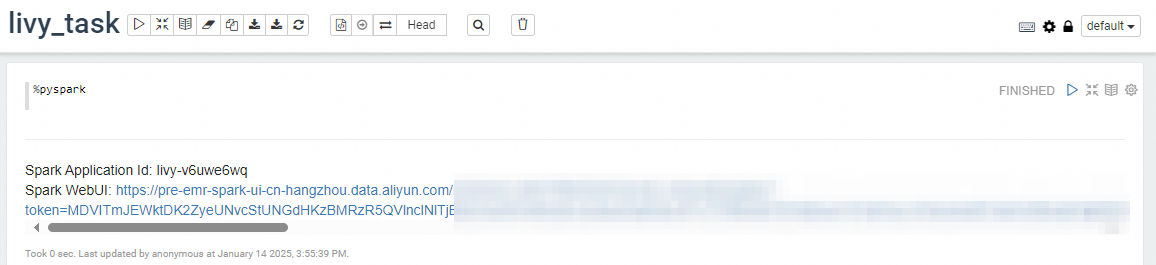
作成したノートブックに次のコードを入力して、Spark セッションを開始します。
初回起動に必要な時間は 1 ~ 3 分です。
%pysparkと入力すると Python 環境が使用されます。%sparkと入力すると Scala 環境が使用されます。%pysparkSpark セッションが開始されると、Spark UI へのリンクを表示してコードを実行できます。Python コードと Scala コードを一緒に使用できます。
新しいノートブックに次のコードを入力して、現在の Spark 環境で使用可能なデータベースをクエリします。
%pyspark spark.sql("show databases").show()次の図は、返された情報を示しています。

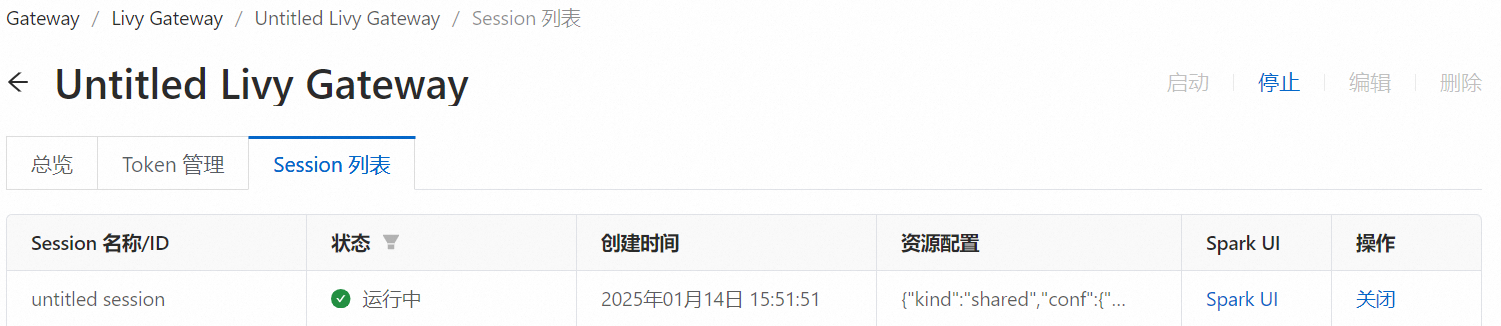
オプション。セッション情報を表示します。
Livy インターフェースを使用して Spark セッションを作成した後、指定した Livy ゲートウェイの [セッション] タブで、セッション ID やステータスなど、Spark セッションに関する情報を表示できます。
[Livy ゲートウェイ] タブで、目的の Livy ゲートウェイを見つけ、ゲートウェイの名前をクリックします。
[セッション] タブをクリックします。
[セッション] タブでは、Livy インターフェースを使用して作成された Spark セッションに関する情報を表示できます。