OSS-HDFS は RootPolicy をサポートしています。RootPolicy を使用すると、OSS-HDFS にカスタムプレフィックスを設定できます。この機能により、Serverless Spark は、元の hdfs:// プレフィックスを使用するタスクを変更することなく、OSS-HDFS 内のデータで直接操作を実行できます。
準備
Serverless Spark ワークスペースを作成済みであること。詳細については、「ワークスペースの作成」をご参照ください。
OSS-HDFS が有効になっている EMR on ECS クラスターを作成済みであること。詳細については、「クラスターの作成」をご参照ください。
RootPolicy の設定
クラスターの OSS-HDFS サービスに対して RootPolicy をすでに設定している場合は、設定セクションをスキップして、直接「RootPolicy の使用」をお読みください。
環境変数を設定します。
ECS インスタンスに接続します。詳細については、「ECS インスタンスへの接続」をご参照ください。
インストールされている JindoSDK JAR パッケージの bin ディレクトリに移動します。
cd jindosdk-x.x.x/bin/説明x.x.x は JindoSDK JAR パッケージのバージョン番号を示します。
jindosdk.cfgという名前の設定ファイルを作成し、次のパラメーターを設定ファイルに追加します。[common] 次のデフォルト設定を保持します。 logger.dir = /tmp/jindo/ logger.sync = false logger.consolelogger = false logger.level = 0 logger.verbose = 0 logger.cleaner.enable = true hadoopConf.enable = false [jindosdk] 次のパラメーターを指定します。 <!-- この例では、中国 (杭州) リージョンが使用されています。実際のリージョンを指定してください。 --> fs.oss.endpoint = cn-hangzhou.oss-dls.aliyuncs.com <! -- OSS-HDFS へのアクセスに使用する AccessKey ID と AccessKey Secret を設定します。 --> fs.oss.accessKeyId = yourAccessKeyId fs.oss.accessKeySecret = yourAccessKeySecret環境変数を設定します。
export JINDOSDK_CONF_DIR=<JINDOSDK_CONF_DIR><JINDOSDK_CONF_DIR> を
jindosdk.cfg設定ファイルの絶対パスに設定します。
RootPolicy を設定します。
次の SetRootPolicy コマンドを実行して、バケットのカスタムプレフィックスを含む登録済みアドレスを指定します。
jindo admin -setRootPolicy oss://<bucket_name>.<dls_endpoint>/ hdfs://<your_ns_name>/次の表に、SetRootPolicy コマンドのパラメーターを説明します。
パラメーター
説明
bucket_name
OSS-HDFS が有効になっているバケットの名前。
dls_endpoint
OSS-HDFS が有効になっているバケットがあるリージョンのエンドポイント。例:
cn-hangzhou.oss-dls.aliyuncs.com。RootPolicy を実行するたびに SetRootPolicy コマンドに <dls_endpoint> パラメーターを繰り返し追加したくない場合は、次のいずれかの方法を使用して、Hadoop の
core-site.xmlファイルに設定項目を追加できます。方法 1:
<configuration> <property> <name>fs.oss.endpoint</name> <value><dls_endpoint></value> </property> </configuration>方法 2:
<configuration> <property> <name>fs.oss.bucket.<bucket_name>.endpoint</name> <value><dls_endpoint></value> </property> </configuration>
your_ns_name
OSS-HDFS へのアクセスに使用されるカスタム nsname。
testなどの空でない文字列がサポートされています。現在のバージョンでは、ルートディレクトリのみがサポートされています。アクセス ポリシーの検出アドレスとスキーム実装クラスを設定します。
Hadoop の core-site.xml ファイルで次のパラメーターを設定する必要があります。
<configuration> <property> <name>fs.accessPolicies.discovery</name> <value>oss://<bucket_name>.<dls_endpoint>/</value> </property> <property> <name>fs.AbstractFileSystem.hdfs.impl</name> <value>com.aliyun.jindodata.hdfs.HDFS</value> </property> <property> <name>fs.hdfs.impl</name> <value>com.aliyun.jindodata.hdfs.JindoHdfsFileSystem</value> </property> </configuration>複数のバケットに対してアクセス ポリシーの検出アドレスとスキーム実装クラスを設定する場合は、バケットをコンマ (
,) で区切ります。次のコマンドを実行して、RootPolicy が正常に設定されているかどうかを確認します。
hadoop fs -ls hdfs://<your_ns_name>/次の結果が返された場合、RootPolicy は正常に設定されています。
drwxr-x--x - hdfs hadoop 0 2023-01-05 12:27 hdfs://<your_ns_name>/apps drwxrwxrwx - spark hadoop 0 2023-01-05 12:27 hdfs://<your_ns_name>/spark-history drwxrwxrwx - hdfs hadoop 0 2023-01-05 12:27 hdfs://<your_ns_name>/tmp drwxrwxrwx - hdfs hadoop 0 2023-01-05 12:27 hdfs://<your_ns_name>/userカスタムプレフィックスを使用して OSS-HDFS にアクセスします。
Hive や Spark などのサービスを再起動すると、カスタムプレフィックスを使用して OSS-HDFS にアクセスできます。
任意。他の目的で RootPolicy を使用します。
バケットに指定されたカスタムプレフィックスを含むすべての登録済みアドレスを一覧表示する
次の listAccessPolicies コマンドを実行して、バケットに指定されたカスタムプレフィックスを含むすべての登録済みアドレスを一覧表示します。
jindo admin -listAccessPolicies oss://<bucket_name>.<dls_endpoint>/バケットに指定されたカスタムプレフィックスを含むすべての登録済みアドレスを削除する:
次の unsetRootPolicy コマンドを実行して、バケットに指定されたカスタムプレフィックスを含むすべての登録済みアドレスを削除します。
jindo admin -unsetRootPolicy oss://<bucket_name>.<dls_endpoint>/ hdfs://<your_ns_name>/
RootPolicy の使用
シナリオ 1: Notebook セッションで RootPolicy を使用する
Spark 設定を構成します。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある [セッションマネージャー] をクリックします。
[Notebook セッション] ページで、[Notebook セッションの作成] をクリックします。
[Notebook セッションの作成] ページで、次の [Spark 設定] を構成します。
spark.hadoop.fs.accessPolicies.discovery oss://<buckename>.cn-<region>.oss-dls.aliyuncs.com spark.hadoop.fs.AbstractFileSystem.hdfs.impl com.aliyun.jindodata.hdfs.v3.HDFS spark.hadoop.fs.hdfs.impl com.aliyun.jindodata.hdfs.v3.JindoDistributedFileSystemデータ開発 Notebook タスクで、RootPolicy を介して OSS-HDFS に設定されたカスタムプレフィックスを直接使用します。
--テーブルの作成 spark.sql("""CREATE TABLE default.my_orc_table ( id INT, name STRING, age INT ) location 'hdfs://<ns_name>/user/hive/warehouse/ads_user_info_1d_emr/my_orc_table/'""") --データの挿入 spark.sql("""INSERT INTO table default.my_orc_table(id, name, age) VALUES (1, 'Alice', 30)"""); --クエリ spark.sql("SELECT * FROM default.my_orc_table").show()説明CREATE TABLE 文の "<ns_name>" を、OSS-HDFS にアクセスするためのカスタムプレフィックスに置き換えます。
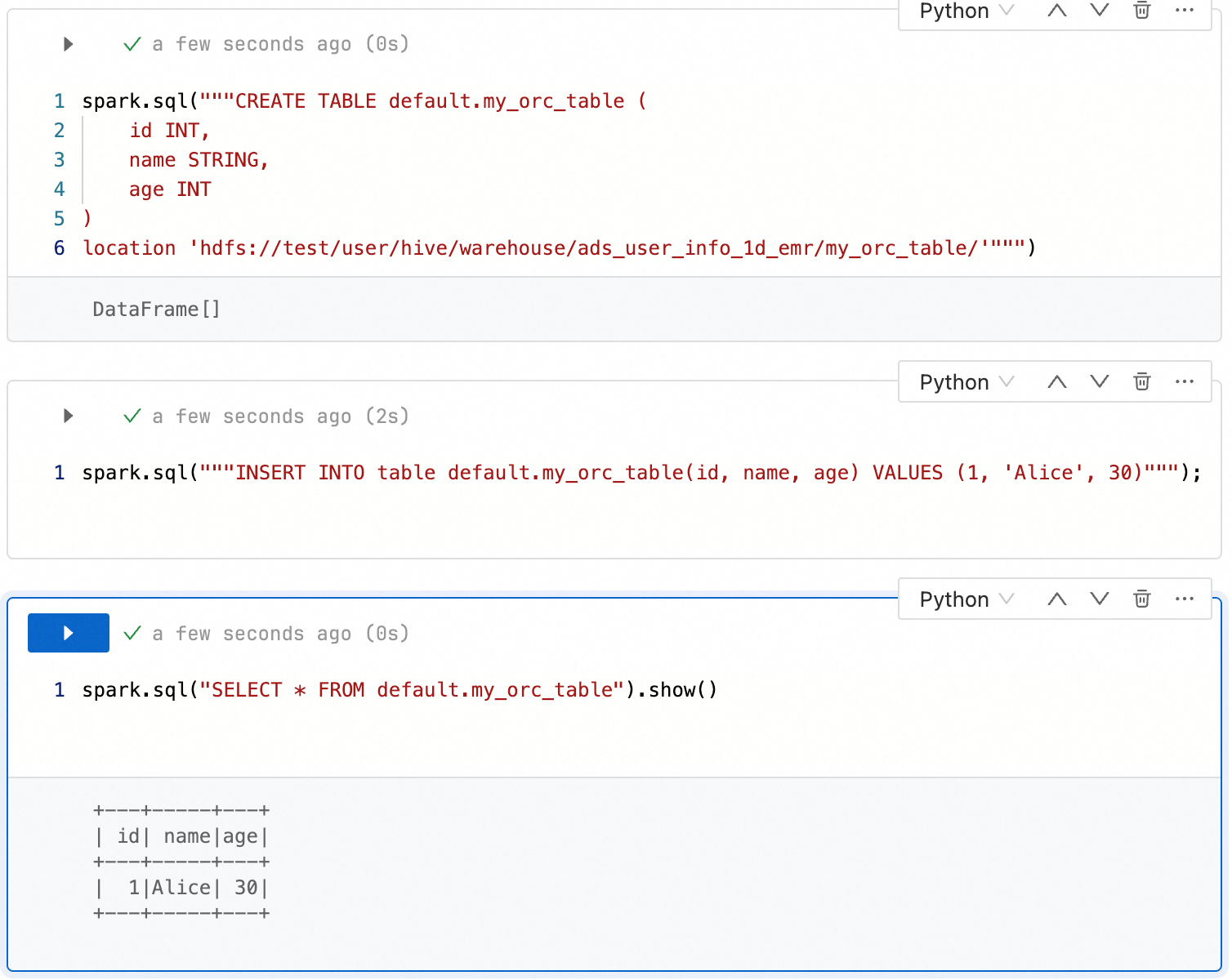
Notebook の !hadoop fs コマンドは、現在 RootPolicy をサポートしていません。
シナリオ 2: SQL セッションでの使用
Spark 設定を構成します。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある [セッションマネージャー] をクリックします。
[SQL セッション] ページで、[SQL セッションの作成] をクリックします。
[SQL セッションの作成] ページで、次の [Spark 設定] を構成します。
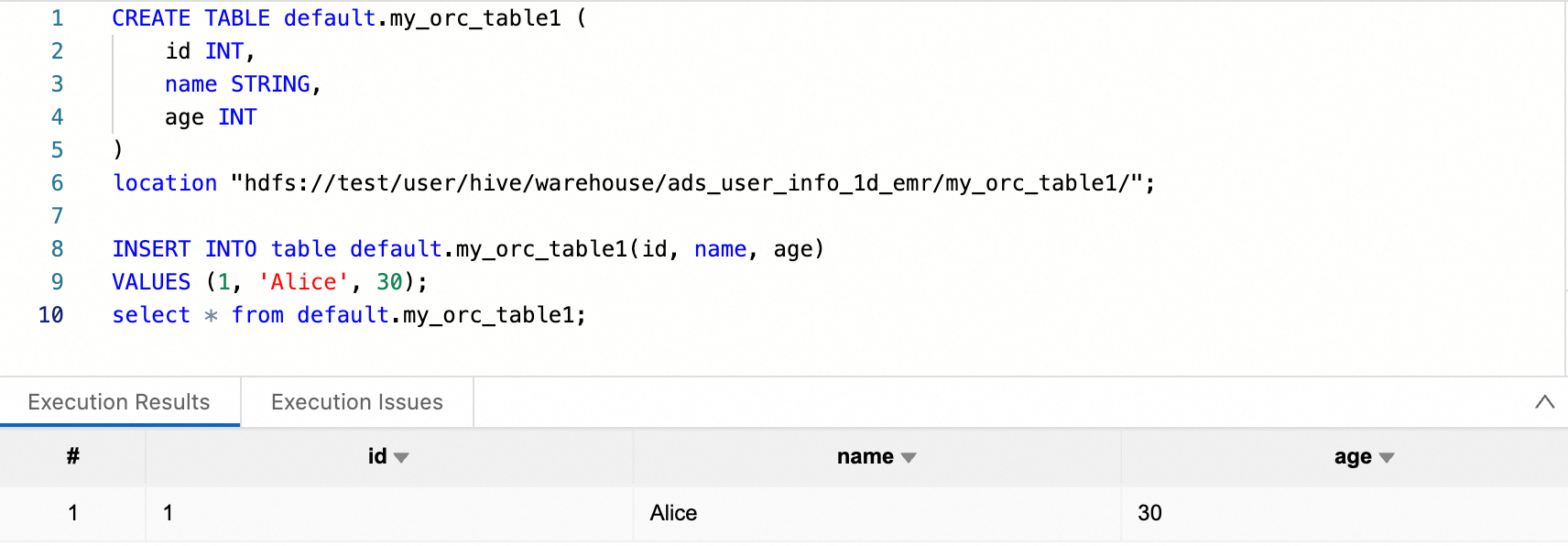
spark.hadoop.fs.accessPolicies.discovery oss://<buckename>.cn-<region>.oss-dls.aliyuncs.com spark.hadoop.fs.AbstractFileSystem.hdfs.impl com.aliyun.jindodata.hdfs.v3.HDFS spark.hadoop.fs.hdfs.impl com.aliyun.jindodata.hdfs.v3.JindoDistributedFileSystemデータ開発 SparkSQL タスクで、RootPolicy を介して OSS-HDFS に設定されたカスタムプレフィックスを直接使用します。
--テーブルの作成 CREATE TABLE default.my_orc_table1 ( id INT, name STRING, age INT ) location "hdfs://<ns_name>/user/hive/warehouse/ads_user_info_1d_emr/my_orc_table1/"; --データの挿入 INSERT INTO table default.my_orc_table1(id, name, age) VALUES (1, 'Alice', 30); --クエリ select * from default.my_orc_table1;説明CREATE TABLE 文の "<ns_name>" を、OSS-HDFS にアクセスするためのカスタムプレフィックスに置き換えます。
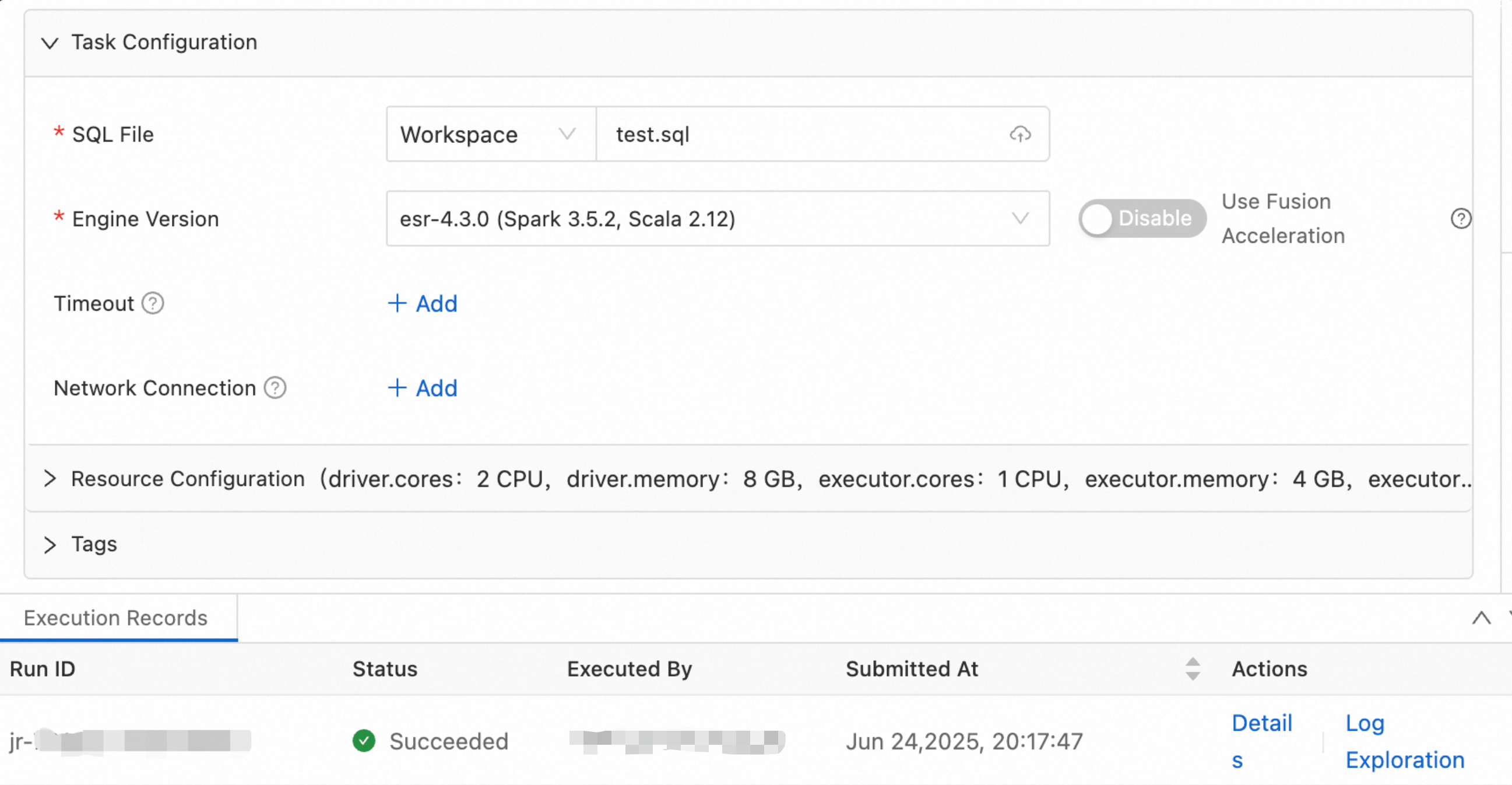
シナリオ 3: バッチジョブで RootPolicy を使用する
ファイルをアップロードします。この記事では、サンプル SQL ファイル test.sql を示します。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある [ファイル管理] をクリックします。
[管理対象ファイルディレクトリ] ページで、[ファイルのアップロード] をクリックします。
[ファイルのアップロード] ダイアログボックスで、ファイルアップロードエリアをクリックしてローカルファイルを選択するか、ターゲットファイルをファイルアップロードエリアに直接ドラッグアンドドロップします。
Spark 設定を構成します。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある [データ開発] をクリックします。
[開発ディレクトリ] タブで、
 (作成) アイコンをクリックします。
(作成) アイコンをクリックします。表示されるダイアログボックスで、[名前] を入力し、[バッチジョブ] タイプで SQL タスクを選択して、[OK] をクリックします。
[タスク設定] ページで、次の [Spark 設定] を構成します。
spark.hadoop.fs.accessPolicies.discovery oss://<buckename>.cn-<region>.oss-dls.aliyuncs.com spark.hadoop.fs.AbstractFileSystem.hdfs.impl com.aliyun.jindodata.hdfs.v3.HDFS spark.hadoop.fs.hdfs.impl com.aliyun.jindodata.hdfs.v3.JindoDistributedFileSystem
データ開発ページで、[実行] をクリックします。結果は以下のとおりです。