このチュートリアルでは、2 つの例を使用してデータを同期する方法を示します。MySQL データソースのユーザー基本情報テーブル ods_user_info_d と、HttpFile の Web サイトアクセスログデータファイル user_log.txt です。これらのデータは、Data Integration オフライン同期タスクを介して非公開 OSS に同期され、Spark SQL によって作成された外部テーブルを介してアクセスされます。
目的
Data Integration を使用して、MySQL データソースに格納されているユーザーの基本情報と、HttpFile データソースに格納されているユーザーの Web サイトアクセスログを非公開 OSS バケットに同期します。ユーザーの基本情報と Web サイトアクセスログは、DataWorks によって提供されます。データソースを追加する
ソースタイプ
同期されるデータ
ソーステーブルのスキーマ
デスティネーションタイプ
MySQL
テーブル: ods_user_info_d
ユーザーの基本情報
uid: ユーザー名
gender: 性別
age_range: 年齢層
zodiac: 星座
OSS
HttpFile
ファイル: user_log.txt
ユーザーの Web サイトアクセスログ
ユーザーアクセスレコードは 1 行を占めます。
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent"$http_referer" "$http_user_agent" [unknown_content];OSS
データが同期された後、Spark SQL を使用して外部テーブルを作成し、非公開 OSS バケット内の同期データにアクセスします。
手順
ステップ 1: ワークフローを設計する
このステップでは、Data Integration ノードと E-MapReduce (EMR) Spark SQL ノードを使用してデータを取得します。データ取得は、ユーザープロファイル分析プロセスの一部です。 ods_raw_log_d_2oss_spark ノードは、HttpFile データソースのユーザーの Web サイトアクセスログを非公開 OSS バケットに同期するために使用されます。次に、ods_raw_log_d_spark ノードは、非公開 OSS バケットの同期データにアクセスするための単純な外部テーブルを作成するために使用されます。 ods_user_info_d_2oss_spark ノードは、MySQL データソースのユーザーの基本情報を非公開 OSS バケットに同期するために使用されます。次に、ods_user_info_d_spark ノードは、非公開 OSS バケットの同期データにアクセスするための外部テーブルを作成するために使用されます。
DataWorks コンソール にログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発に移動] をクリックします。
ワークフローを設計する
ワークフローを作成します。
開発コンポーネントは、ワークフローに基づいてデータを開発するために使用されます。ノードを作成する前に、ワークフローを作成する必要があります。詳細については、「ワークフローを作成する」をご参照ください。
この例では、
User profile analysis_Sparkという名前のワークフローが使用されます。ワークフローを設計します。
ワークフローを作成すると、ワークフローキャンバスが自動的に表示されます。ワークフローキャンバスの上部で、[ノードの作成] をクリックし、ノードをワークフローキャンバスにドラッグし、線を描画して、ワークフロー設計 に基づいてデータ同期のノード間の依存関係を構成します。
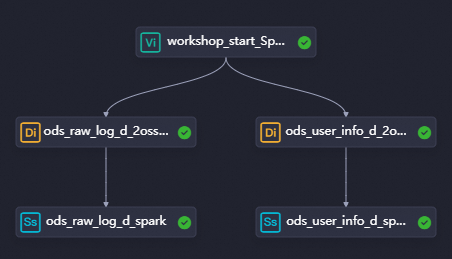
この例では、ゼロロードノードと同期ノードの間にリネージは存在しません。この場合、ノード間の依存関係は、ワークフローに線を描画することによって構成されます。依存関係の構成方法の詳細については、「スケジューリング依存関係構成ガイド」をご参照ください。次の表に、ノードタイプ、ノード名、および各ノードの機能を示します。
ノードカテゴリ
ノードタイプ
ノード名
ノード機能
全般
 ゼロロードノード
ゼロロードノードworkshop_start_sparkユーザープロファイル分析のワークフロー全体を管理するために使用されます。たとえば、ゼロロードノードは、ワークフローの実行開始時間を決定します。ワークスペース内のワークフローが複雑な場合、ゼロロードノードを使用すると、ワークフロー内のデータフローのパスがより明確になります。このノードはドライランノードです。ノードのコードを編集する必要はありません。
Data Integration
 バッチ同期
バッチ同期ods_raw_log_d_2oss_sparkHttpFile データソースに格納されているユーザーの Web サイトアクセスログを非公開 OSS バケットに同期するために使用されます。同期されたデータは、後で Spark SQL を使用して取得できます。
Data Integration
 バッチ同期
バッチ同期ods_user_info_d_2oss_sparkMySQL データソースに格納されているユーザーの基本情報を非公開 OSS バケットに同期するために使用されます。同期されたデータは、後で Spark SQL を使用して取得できます。
EMR
 EMR Spark SQL
EMR Spark SQLods_raw_log_d_sparkods_raw_log_d_spark外部テーブルを作成して、非公開 OSS バケット内の同期されたユーザーの Web サイトアクセスログにアクセスするために使用されます。EMR
 EMR Spark SQL
EMR Spark SQLods_user_info_d_sparkods_user_info_d_spark外部テーブルを作成して、非公開 OSS バケット内の同期されたユーザーの基本情報にアクセスするために使用されます。
スケジューリングロジックを構成する
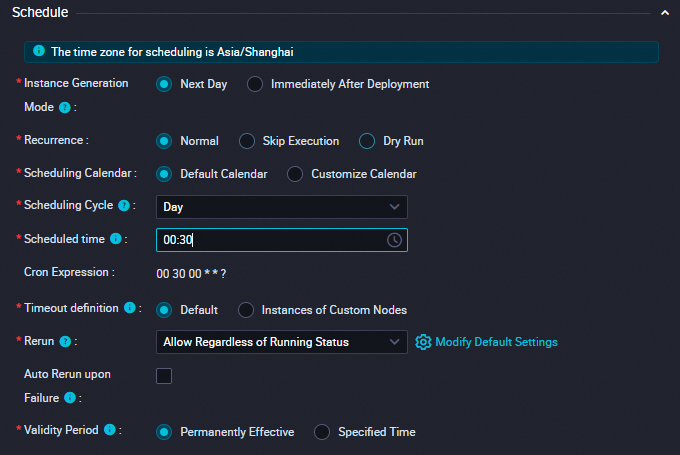
この例では、workshop_start_spark ゼロロードノードを使用して、毎日 00:30 にワークフローの実行をトリガーします。次の表に、ゼロロードノードのスケジューリングプロパティの構成を示します。他のノードのスケジューリング構成を変更する必要はありません。実装ロジックについては、「さまざまなシナリオでワークフロー内のノードのスケジューリング時間を構成する」をご参照ください。その他のスケジューリング構成については、「概要」をご参照ください。
構成項目 | スクリーンショット | 説明 |
スケジューリング時間 |
| ゼロロードノードのスケジューリング時間は 00:30 に設定されています。ゼロロードノードは、毎日 00:30 に現在のワークフローの実行をトリガーします。 |
スケジューリングの依存関係 |
|
|
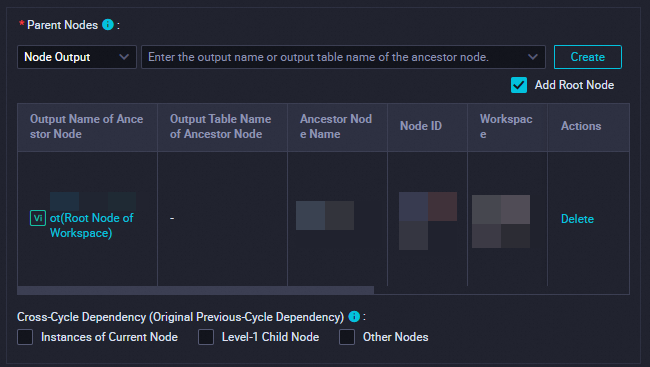
DataWorks ワークフローのすべてのノードは、別のノードに依存しています。データ同期フェーズのすべてのノードは、workshop_start_spark ゼロロードノードに依存しています。したがって、workshop_start_spark ノードはデータ同期ワークフローの実行をトリガーします。
ステップ 2: データ同期タスクを構成する
ワークフローを構成した後、ods_user_info_d_2oss_spark ノードと ods_raw_log_d_2oss_spark ノードをダブルクリックできます。ノードの構成タブで、ユーザーの基本情報と Web サイトアクセスログを非公開 OSS バケットに同期するためのパラメーターを構成します。次に、ods_raw_log_d_spark ノードと ods_user_info_d_spark ノードに Spark SQL コードを記述して、外部テーブルを作成し、非公開 OSS バケット内の同期データにアクセスします。
ユーザーの基本情報と Web サイトアクセスログを非公開 OSS バケットに同期する
Data Integration を使用して、DataWorks によって提供されるユーザーの基本情報と Web サイトアクセスログを、非公開 OSS [バケット] のディレクトリに同期します。
ユーザーの Web サイトアクセスログを非公開 OSS バケットに同期するようにノードを構成する
バッチ同期タスクを使用して、HttpFile データソースに格納されているユーザーの Web サイトアクセスログを非公開 OSS バケットに同期できます。
HttpFile データソースの Web サイトアクセスログを作成した OSS バケットに同期します。
[DataStudio] ページで、ods_raw_log_d_2oss_spark ノードをダブルクリックして、ノードの構成タブに移動します。
使用するリソースグループとデータソースの間にネットワーク接続を確立します。
ネットワーク接続とリソースの構成が完了したら、[次へ] をクリックし、プロンプトに従って接続テストを完了します。
パラメーター
説明
[ソース]
ソース: 値を HttpFile に設定します。
データソース名: 値を user_behavior_analysis_httpfile に設定します。
[リソースグループ]
購入した [サーバーレスリソースグループ] を選択します。
[デスティネーション]
デスティネーション: 値を OSS に設定します。
データソース名: 追加した非公開 OSS データソースの名前を指定する test_g に設定します。
データ同期ノードを構成します。
パラメーター
説明
ソース
[ファイルパス]: 値を /user_log.txt に設定します。
[テキストタイプ]: 値を text に設定します。
[列区切り文字]: | を入力します。
[圧縮形式]: OSS オブジェクトの圧縮形式。有効な値: なし、Gzip、Bzip2、および Zip。 なし を選択します。
[ヘッダーをスキップ]: 値を いいえ に設定します。
[デスティネーション]
[テキストタイプ]: 値を text に設定します。
[オブジェクト名 (パスを含む)]: OSS オブジェクトのパス。OSS バケットに作成したフォルダーに基づいてこのパラメーターを構成します。この例では、ods_raw_log_d/log_${bizdate}/log_${bizdate}.txt が入力されています。 ods_raw_log_d は、OSS バケットに作成したフォルダーの名前です。 $bizdate は前日の日付を示します。
[列区切り文字]: | を入力します。
スケジューリングプロパティを構成します。
ノードの構成タブの右側のナビゲーションウィンドウで、[プロパティ] をクリックします。 [プロパティ] タブで、ノードのスケジューリングプロパティと基本情報を構成します。次の表に、構成を示します。
説明DataWorks は、スケジューリングシナリオで日次データを OSS バケットのさまざまなディレクトリとオブジェクトに書き込むために使用できるスケジューリングパラメーターを提供します。ディレクトリとオブジェクトには、データタイムスタンプに基づいて名前が付けられます。
ビジネスシナリオに基づいて、非公開 OSS バケットの [オブジェクト名 (パスを含む)] パラメーターを構成するときに、
${変数名}形式でディレクトリに変数を構成できます。次に、ノードの構成タブの [プロパティ] タブで、変数にスケジューリングパラメーターを値として割り当てることができます。このようにして、非公開 OSS バケット内のディレクトリ名とオブジェクト名を、スケジューリングシナリオで動的に生成できます。セクション
説明
スクリーンショット
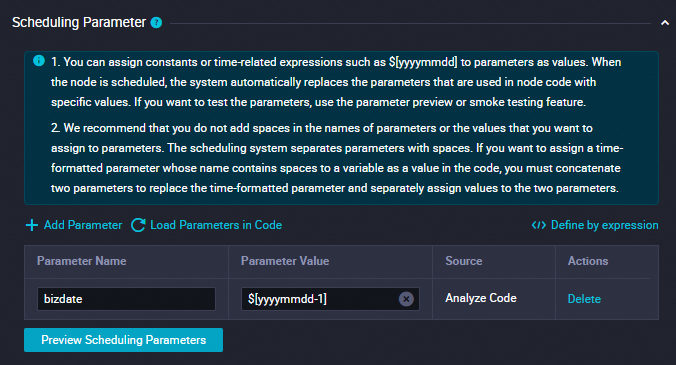
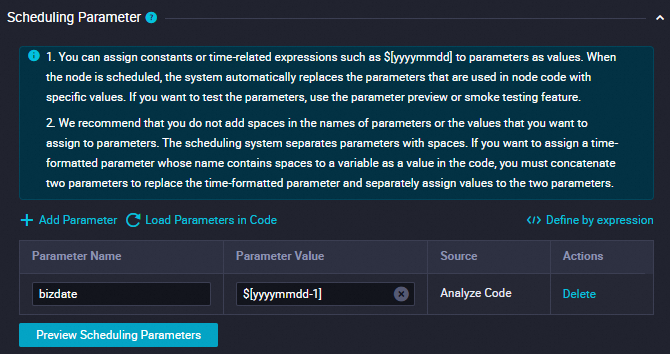
[スケジューリングパラメーター]
このセクションで、[パラメーターを追加] をクリックしてスケジューリングパラメーターを追加します。
パラメーター名を
bizdateに設定します。パラメーター値を
$[yyyymmdd-1]に設定します。
詳細については、「スケジューリングパラメーターを構成する」をご参照ください。
[依存関係]
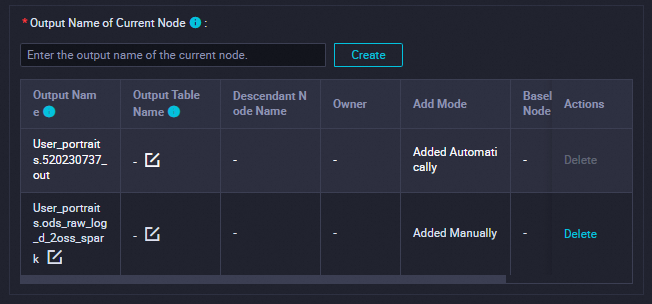
このセクションで、出力テーブルが現在のノードの出力名として使用されていることを確認します。
出力テーブルには、
ワークスペース名.ノード名の形式で名前が付けられます。詳細については、「スケジューリングの依存関係を構成する」をご参照ください。
構成が完了したら、ツールバーの
 アイコンをクリックします。
アイコンをクリックします。
ユーザーの基本情報を非公開 OSS バケットに同期するようにノードを構成する
バッチ同期タスクを使用して、MySQL データソースに格納されているユーザーの基本情報を非公開 OSS バケットに同期できます。
[DataStudio] ページで、ods_user_info_d_2oss_spark ノードをダブルクリックして、ノードの構成タブに移動します。
使用するリソースグループとデータソースの間にネットワーク接続を確立します。
ネットワーク接続とリソースの構成が完了したら、[次へ] をクリックし、プロンプトに従って接続テストを完了します。
パラメーター
説明
ソース
ソース: 値を MySQL に設定します。
データソース名: 値を user_behavior_analysis_mysql に設定します。
[リソースグループ]
購入した [サーバーレスリソースグループ] を選択します。
[デスティネーション]
デスティネーション: 値を OSS に設定します。
データソース名: 追加した非公開 OSS データソースの名前である test_g に設定します。
データ同期ノードを構成します。
パラメーター
説明
[ソース]
[テーブル]: データソースの ods_user_info_d テーブルを選択します。
[分割キー]: 読み取るデータの分割キー。プライマリキーまたはインデックス付き列を分割キーとして使用することをお勧めします。 INTEGER タイプのフィールドのみがサポートされています。この例では、uid が使用されます。
[デスティネーション]
[テキストタイプ]: 値を text に設定します。
[オブジェクト名 (パスを含む)]: OSS オブジェクトのパス。OSS バケットに作成したフォルダーに基づいてこのパラメーターを構成します。この例では、ods_user_info_d/user_${bizdate}/user_${bizdate}.txt が入力されています。 ods_user_info_d は、OSS バケットに作成したフォルダーの名前です。 $bizdate は前日の日付を示します。
[列区切り文字]: | を入力します。
スケジューリングプロパティを構成します。
ノードの構成タブの右側のナビゲーションウィンドウで、[プロパティ] をクリックします。[プロパティ] タブで、ノードのスケジューリングプロパティと基本情報を構成します。次の表は、構成について説明しています。
説明DataWorks は、スケジューリングシナリオで日次データを OSS バケットのさまざまなディレクトリとオブジェクトに書き込むために使用できるスケジューリングパラメーターを提供します。ディレクトリとオブジェクトには、データタイムスタンプに基づいて名前が付けられます。
ビジネスシナリオに基づいて、非公開 OSS バケットの [オブジェクト名 (パスを含む)] パラメーターを構成するときに、
${変数名}形式でディレクトリに変数を構成できます。次に、ノードの構成タブの [プロパティ] タブで、変数にスケジューリングパラメーターを値として割り当てることができます。このようにして、非公開 OSS バケット内のディレクトリ名とオブジェクト名を、スケジューリングシナリオで動的に生成できます。セクション
説明
スクリーンショット
[スケジューリングパラメーター]
このセクションで、[パラメーターを追加] をクリックしてスケジューリングパラメーターを追加します。
パラメーター名を
bizdateに設定します。パラメーター値を
$[yyyymmdd-1]に設定します。
詳細については、「スケジューリングパラメーターを構成する」をご参照ください。
[依存関係]
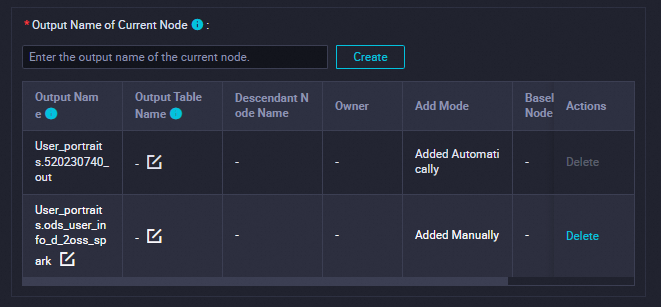
このセクションで、出力テーブルが現在のノードの出力名として使用されていることを確認します。
出力テーブルには、
ワークスペース名.ノード名の形式で名前が付けられます。詳細については、「スケジューリングの依存関係を構成する」をご参照ください。
構成が完了したら、ツールバーの
アイコンをクリックします。
Spark SQL を使用して OSS データをロードする外部テーブルを作成する
バッチ同期タスクを使用してデータが非公開 OSS バケットに同期された後、生成された OSS オブジェクトに基づいて Spark SQL の CREATE ステートメントを実行して、ods_raw_log_d_spark 外部テーブルと ods_user_info_d_spark 外部テーブルを作成できます。次に、LOCATION を使用して、非公開 OSS バケット内の同期されたユーザーの基本情報と Web サイトアクセスログにアクセスし、後続のデータ処理を行います。
ods_raw_log_d_spark ノードを構成する
EMR Spark SQL ノードを使用して作成された ods_raw_log_d_spark 外部テーブルに基づいて、LOCATION を使用して、関連するバッチ同期タスクによって [非公開 OSS] [バケット] に同期されたユーザーの Web サイトアクセスログにアクセスできます。
コードを構成します。
-- シナリオ: 次のサンプルコードでは、Spark SQL の SQL ステートメントが使用されています。コードでは、ods_raw_log_d_spark 外部テーブルが EMR Spark SQL ノードを使用して作成され、LOCATION を使用して、関連するバッチ同期タスクによって非公開 OSS バケットに同期されたユーザーの Web サイトアクセスログにアクセスします。 -- 注: -- DataWorks は、スケジューリングシナリオで日次の増分データをデスティネーションテーブルの対応するパーティションに書き込むために使用できるスケジューリングパラメーターを提供します。 -- 実際の開発シナリオでは、ノードコードで ${変数名} 形式で変数を定義できます。次に、ノードの構成タブの [プロパティ] タブで、変数にスケジューリングパラメーターを値として割り当てることができます。このようにして、スケジューリングパラメーターの値は、スケジューリングシナリオでのスケジューリングパラメーターの構成に基づいて、ノードコードで動的に置き換えられます。 CREATE EXTERNAL TABLE IF NOT EXISTS ods_raw_log_d_spark ( `col` STRING ) PARTITIONED BY ( dt STRING ) LOCATION 'oss://dw-emr-demo/ods_raw_log_d/log_${bizdate}/'; ALTER TABLE ods_raw_log_d_spark ADD IF NOT EXISTS PARTITION (dt = '${bizdate}') LOCATION 'oss://dw-emr-demo/ods_raw_log_d/log_${bizdate}/' ;説明上記のコードでは、LOCATION にサンプルパスが使用されています。パスは、関連するバッチ同期ノードを構成するときの [オブジェクト名 (パスを含む)] パラメーターの値に基づいています。 LOCATION パラメーターを作成したフォルダーのパスに設定する必要があります。 dw-emr-demo は、環境を準備したときに作成した OSS バケットのドメイン名です。
スケジューリングプロパティを構成します。
ods_raw_log_d_sparkノードのスケジューリングパラメーターを構成して、特定のデータタイムスタンプを持つ非公開 OSS ログオブジェクトを取得し、Spark テーブルの同じデータタイムスタンプを持つ対応するパーティションにデータを書き込みます。セクション
説明
スクリーンショット
[スケジューリングパラメーター]
このセクションで、[パラメーターを追加] をクリックしてスケジューリングパラメーターを追加します。
パラメーター名を
bizdateに設定します。パラメーター値を
$[yyyymmdd-1]に設定します。詳細については、「スケジューリングパラメーターを構成する」をご参照ください。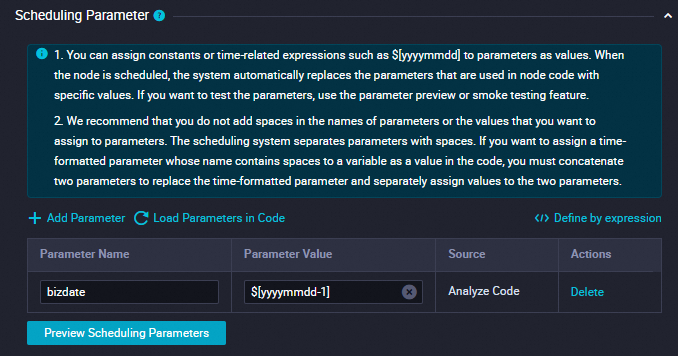
[依存関係]
このセクションで、出力テーブルが現在のノードの出力名として使用されていることを確認します。
出力テーブルには、
ワークスペース名.ノード名の形式で名前が付けられます。詳細については、「スケジューリングの依存関係を構成する」をご参照ください。
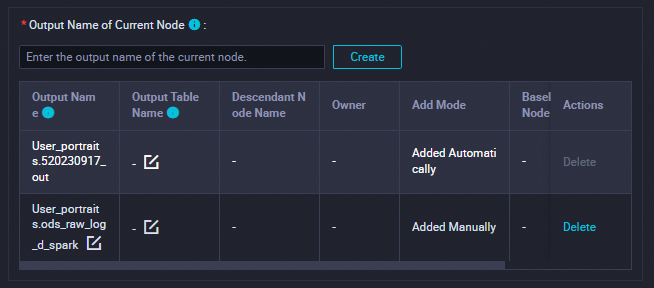 説明
説明このトピックの SQL ステートメントでは、
${bizdate}スケジューリングパラメーターが構成され、値T-1がスケジューリングパラメーターに割り当てられます。バッチコンピューティングシナリオでは、bizdate はビジネストランザクションが実行された日付を示し、これは多くの場合データタイムスタンプと呼ばれます。たとえば、現在の日に前日の売上高の統計データを収集する場合、前日はビジネストランザクションが実行された日付であり、データタイムスタンプを表します。構成が完了したら、
 アイコンをクリックします。
アイコンをクリックします。
ods_user_info_d_spark ノードを構成する
EMR Spark SQL ノードを使用して作成された ods_user_info_d_spark 外部テーブルに基づいて、LOCATION を使用して、関連するバッチ同期タスクによって [非公開 OSS] [バケット] に同期されたユーザーの基本情報にアクセスできます。
コードを構成します。
-- シナリオ: 次のサンプルコードでは、Spark SQL の SQL ステートメントが使用されています。コードでは、ods_user_info_d_spark 外部テーブルが EMR Spark SQL ノードを使用して作成され、LOCATION を使用して、関連するバッチ同期タスクによって非公開 OSS バケットに同期されたユーザーの基本情報にアクセスします。次に、データは dt パーティションに書き込まれます。 -- 注: -- DataWorks は、スケジューリングシナリオで日次の増分データをデスティネーションテーブルの対応するパーティションに書き込むために使用できるスケジューリングパラメーターを提供します。 -- 実際の開発シナリオでは、ノードコードで ${変数名} 形式で変数を定義できます。次に、ノードの構成タブの [プロパティ] タブで、変数にスケジューリングパラメーターを値として割り当てることができます。このようにして、スケジューリングパラメーターの値は、スケジューリングシナリオでのスケジューリングパラメーターの構成に基づいて、ノードコードで動的に置き換えられます。 CREATE EXTERNAL TABLE IF NOT EXISTS ods_user_info_d_spark ( `uid` STRING COMMENT 'ユーザー ID' ,`gender` STRING COMMENT '性別' ,`age_range` STRING COMMENT '年齢層' ,`zodiac` STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY'|' STORED AS TEXTFILE LOCATION 'oss://dw-emr-demo/ods_user_info_d/user_${bizdate}/' ; ALTER TABLE ods_user_info_d_spark ADD IF NOT EXISTS PARTITION (dt = '${bizdate}') LOCATION'oss://dw-emr-demo/ods_user_info_d/user_${bizdate}/' ;説明上記のコードでは、LOCATION にサンプルパスが使用されています。パスは、関連するバッチ同期ノードを構成するときの [オブジェクト名 (パスを含む)] パラメーターの値に基づいています。 LOCATION パラメーターを作成したフォルダーのパスに設定する必要があります。 dw-emr-demo は、環境を準備したときに作成した OSS バケットのドメイン名です。
スケジューリングプロパティを構成します。
ods_user_info_d_sparkノードのスケジューリングパラメーターを構成して、特定のデータタイムスタンプを持つ非公開 OSS ユーザー情報オブジェクトを取得し、Spark テーブルの同じデータタイムスタンプを持つ対応するパーティションにデータを書き込みます。セクション
説明
スクリーンショット
[スケジューリングパラメーター]
このセクションで、[パラメーターを追加] をクリックしてスケジューリングパラメーターを追加します。
パラメーター名を
bizdateに設定します。パラメーター値を
$[yyyymmdd-1]に設定します。詳細については、「スケジューリングパラメーターを構成する」をご参照ください。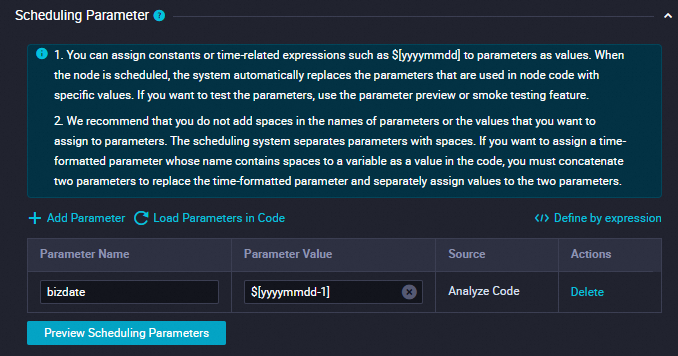
[依存関係]
このセクションで、出力テーブルが現在のノードの出力名として使用されていることを確認します。
出力テーブルには、
ワークスペース名.ノード名の形式で名前が付けられます。詳細については、「スケジューリングの依存関係を構成する」をご参照ください。
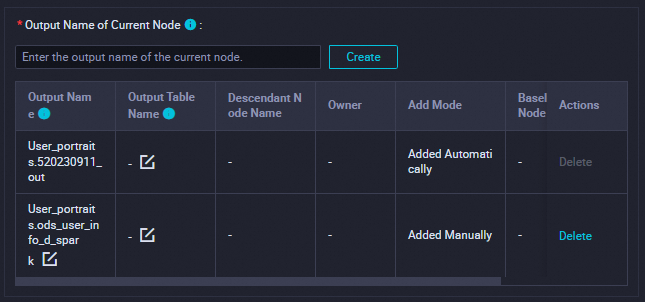
構成が完了したら、
アイコンをクリックします。
ステップ 3: 同期されたデータを確認する
このトピックのすべてのノードが正常に実行された後、DataStudio ページの左側のナビゲーションウィンドウで [アドホッククエリ] をクリックします。 [アドホッククエリ] ウィンドウで、[EMR Spark SQL] タイプのアドホッククエリタスクを作成し、SQL ステートメントを記述して、EMR Spark SQL ノードに基づいて外部テーブルが期待どおりに作成されたかどうかを確認します。
-- パーティションフィルター条件を現在の操作のデータタイムスタンプに更新する必要があります。たとえば、タスクが 2024 年 8 月 8 日に実行された場合、データタイムスタンプは 20240807 であり、タスクの実行日よりも 1 日前になります。
SELECT * FROM ods_raw_log_d_spark WHERE dt ='データタイムスタンプ';-- ods_raw_log_d_spark テーブルのデータをクエリします。
SELECT * FROM ods_user_info_d_spark WHERE dt ='データタイムスタンプ';-- ods_user_info_d_spark テーブルのデータをクエリします。同期されたデータを確認するために使用される SQL ステートメントで、WHERE 条件を "dt = ${bizdate}" に置き換えます。アドホッククエリタスクで、 ([パラメーター付きで実行]) アイコンをクリックし、SQL プレースホルダー
([パラメーター付きで実行]) アイコンをクリックし、SQL プレースホルダー ${bizdate} に値を割り当てて、アドホッククエリタスクを実行します。
次のステップ
データ同期は完了です。次のチュートリアルに進むことができます。次のチュートリアルでは、Spark でユーザーの基本情報と Web サイトアクセスログを処理する方法について学習します。詳細については、「データを処理する」をご参照ください。