このトピックでは、Spark SQL を使用して外部ユーザー情報テーブル ods_user_info_d_spark とログ情報テーブル ods_raw_log_d_spark を作成し、プライベート OSS に保存されているユーザーデータとログデータにアクセスする方法について説明します。また、DataWorks EMR Spark SQL ノードを介してデータを処理し、ターゲットユーザーのプロファイルデータを取得する方法についても説明します。このトピックを読むと、Spark SQL を使用して同期されたデータを計算および分析し、データウェアハウジングにおける簡単なデータ処理シナリオを完了する方法を理解できます。
前提条件
必要なデータが同期されていること。詳細については、「データの同期」をご参照ください。
ods_user_info_d_spark外部テーブルは EMR Spark SQL ノードに基づいて作成され、この外部テーブルを使用して、プライベート OSS バケットに同期された基本的なユーザー情報にアクセスできます。ods_raw_log_d_spark外部テーブルは EMR Spark SQL ノードに基づいて作成され、この外部テーブルを使用して、プライベート OSS バケットに同期されたユーザーのウェブサイトアクセスログにアクセスできます。
注意事項
EMR Serverless Spark ワークスペースは関数の登録をサポートしていません。そのため、ログ情報を分割したり、IP アドレスをリージョンに変換したりする関数を登録することはできません。このトピックでは、ods_raw_log_d_spark テーブルを組み込みの Spark SQL 関数を使用して分割し、ユーザープロファイル分析用の dwd_log_info_di_spark テーブルを生成します。
目的
ods_user_info_d_spark テーブルと ods_raw_log_d_spark 外部テーブルを処理して、基本的なユーザープロファイルテーブルを生成します。
Spark SQL を使用して
ods_raw_log_d_sparkテーブルを処理し、dwd_log_info_di_sparkという名前の新しいログテーブルを生成します。dwd_log_info_di_sparkテーブルとods_user_info_d_sparkテーブルを uid フィールドに基づいて結合し、dws_user_info_all_di_sparkという名前の集計テーブルを生成します。dws_user_info_all_di_sparkテーブルを処理して、ads_user_info_1d_sparkという名前のテーブルを生成します。dws_user_info_all_di_spark テーブルには多数のフィールドと大量のデータが含まれています。この場合、データ消費に長時間を要する可能性があります。そのため、さらなるデータ処理が必要です。
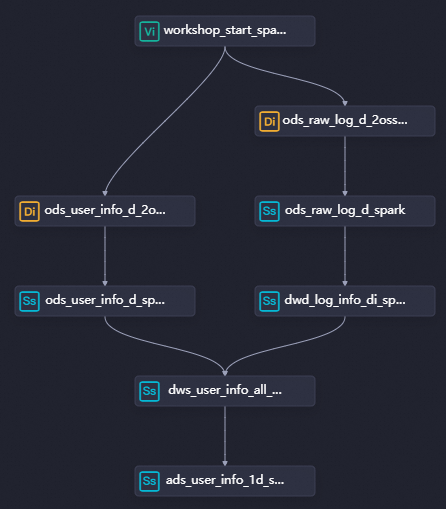
ステップ 1: ワークフローの設計
データ同期フェーズでは、基本的なユーザー情報とユーザーのウェブサイトアクセスログが同期されます。データ処理フェーズでは、dwd_log_info_di_spark ノードを追加してログテーブルを分割し、新しいログテーブルを生成します。次に、dws_user_info_all_di_spark ノードを追加して新しいログテーブルと基本的なユーザー情報テーブルを結合し、集計テーブルを生成します。その後、ads_user_info_1d_spark ノードを追加して集計テーブルをさらに処理し、基本的なユーザープロファイルテーブルを生成します。
DataStudio ページに移動します。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発へ] をクリックします。
データ処理用のノードを作成します。データ同期フェーズでは、EMR Spark SQL ノードに基づいて外部テーブルが作成され、プライベート OSS バケットに保存されている同期データにアクセスします。データ処理フェーズでは、同期されたデータを処理して基本的なユーザープロファイルデータを生成することが目的です。
さまざまなレベルのノードとノードの作業ロジック
ワークフローキャンバスの上部で、[ノードの作成] をクリックして、データ処理のために次の表で説明するノードを作成します。
ノードカテゴリ
ノードタイプ
ノード名
(出力テーブルにちなんで命名)
コードロジック
EMR
 EMR Spark SQL
EMR Spark SQLdwd_log_info_di_spark
ods_raw_log_d_spark テーブルを分割して、後続の結合操作のために新しいログテーブルを生成します。
EMR
 EMR Spark SQL
EMR Spark SQLdws_user_infor_all_di_spark
基本的なユーザー情報テーブルと新しいログテーブルを結合して、集計テーブルを生成します。
EMR
 EMR Spark SQL
EMR Spark SQLads_user_info_1d_spark
集計テーブルをさらに処理して、基本的なユーザープロファイルテーブルを生成します。
ワークフロー内の有向非巡回グラフ (DAG)
ノードをワークフローキャンバスにドラッグし、線を描画してノード間の依存関係を構成し、データ処理のワークフローを設計します。
ステップ 2: EMR Spark SQL ノードの構成
ワークフローの構成が完了したら、EMR Spark SQL ノードの Spark SQL 関数を使用して ods_raw_log_d_spark テーブルを分割し、新しいログテーブルを取得できます。その後、新しいログテーブルを基本的なユーザー情報テーブルと結合して集計テーブルを生成し、集計テーブルをさらにクレンジングおよび処理して、各ユーザーのユーザープロファイルを生成できます。
dwd_log_info_di_spark ノードの構成
ワークフローの構成タブで、dwd_log_info_di_spark ノードをダブルクリックします。ノードの構成タブで、ods_raw_log_d_spark テーブルを処理し、処理されたデータを dwd_log_info_di_spark テーブルに書き込む SQL コードを入力します。
ノードコードの構成
dwd_log_info_di_sparkノードをダブルクリックして、ノードの構成タブに移動します。次のステートメントを記述します。-- シナリオ: 以下のサンプルコードの SQL ステートメントは Spark SQL ステートメントです。Spark SQL 関数を使用して、##@@ を使用して Spark にロードされた ods_raw_log_d_spark テーブルのデータを分割して複数のフィールドを生成し、そのフィールドを dwd_log_info_di_spark テーブルに書き込むことができます。 -- 注: -- DataWorks は、スケジューリングシナリオで日次増分データを宛先テーブルの対応するパーティションに書き込むために使用できるスケジューリングパラメーターを提供します。 -- 実際の開発シナリオでは、ノードコード内で ${変数名} 形式で変数を定義できます。その後、ノードの構成タブの [プロパティ] タブで、スケジューリングパラメーターを値として変数に割り当てることができます。これにより、スケジューリングシナリオでのスケジューリングパラメーターの構成に基づいて、ノードコード内のスケジューリングパラメーターの値が動的に置き換えられます。 CREATE TABLE IF NOT EXISTS dwd_log_info_di_spark ( ip STRING COMMENT 'IP アドレス', uid STRING COMMENT 'ユーザー ID', tm STRING COMMENT 'yyyymmddhh:mi:ss 形式の時間', status STRING COMMENT 'サーバーから返される状態コード', bytes STRING COMMENT 'クライアントに返されるバイト数', method STRING COMMENT'リクエストメソッド', url STRING COMMENT 'url', protocol STRING COMMENT 'プロトコル', referer STRING , device STRING, identity STRING ) PARTITIONED BY ( dt STRING ); ALTER TABLE dwd_log_info_di_spark ADD IF NOT EXISTS PARTITION (dt = '${bizdate}'); INSERT OVERWRITE TABLE dwd_log_info_di_spark PARTITION (dt='${bizdate}') SELECT ip, uid, tm, status, bytes, regexp_extract(request, '(^[^ ]+) .*', 1) AS method, regexp_extract(request, '^[^ ]+ (.*) [^ ]+$', 1) AS url, regexp_extract(request, '.* ([^ ]+$)', 1) AS protocol, regexp_extract(referer, '^[^/]+://([^/]+){1}', 1) AS referer, CASE WHEN lower(agent) RLIKE 'android' THEN 'android' WHEN lower(agent) RLIKE 'iphone' THEN 'iphone' WHEN lower(agent) RLIKE 'ipad' THEN 'ipad' WHEN lower(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN lower(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN lower(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device, CASE WHEN lower(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN lower(agent) RLIKE 'feed' OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$', 1) RLIKE 'feed' THEN 'feed' WHEN lower(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^(Mozilla|Opera)' AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$', 1) NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM ( SELECT SPLIT(col, '##@@')[0] AS ip, SPLIT(col, '##@@')[1] AS uid, SPLIT(col, '##@@')[2] AS tm, SPLIT(col, '##@@')[3] AS request, SPLIT(col, '##@@')[4] AS status, SPLIT(col, '##@@')[5] AS bytes, SPLIT(col, '##@@')[6] AS referer, SPLIT(col, '##@@')[7] AS agent FROM ods_raw_log_d_spark WHERE dt = '${bizdate}' ) a;ノードのスケジューリングプロパティの構成
セクション
スクリーンショット
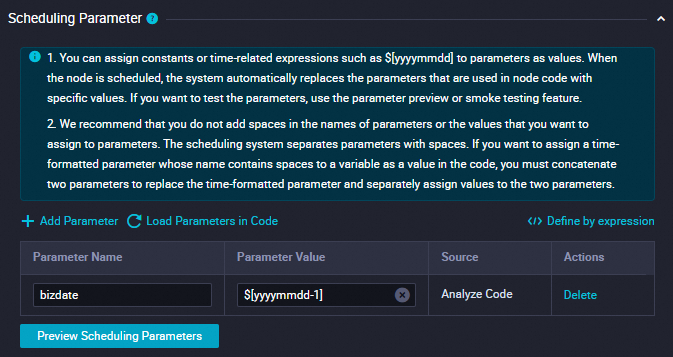
パラメーターの追加
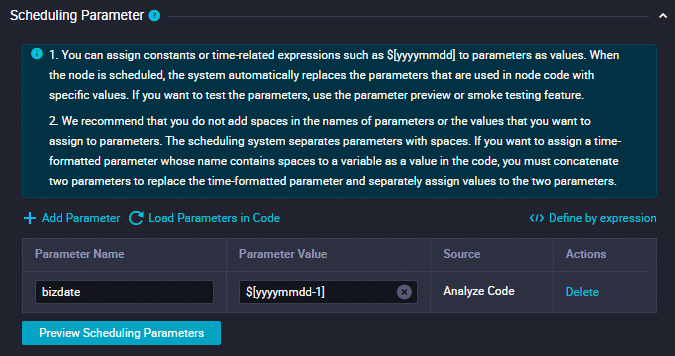
[スケジューリングパラメーター] セクションで [パラメーターの追加] をクリックします。テーブルに表示される行で、スケジューリングパラメーターとその値を指定できます。
パラメーター名を
bizdateに設定します。パラメーター値を
$[yyyymmdd-1]に設定します。
詳細については、「スケジューリングパラメーターの構成」をご参照ください。
依存関係
このセクションでは、出力テーブルが現在のノードの出力名として使用されていることを確認します。
出力テーブルは
workspacename.nodename形式で命名されます。詳細については、「スケジューリング依存関係の構成」をご参照ください。
 説明
説明[スケジュール] セクションで、[スケジューリングサイクル] パラメーターを [日] に設定します。現在のノードの [スケジュールされた時間] パラメーターを個別に構成する必要はありません。現在のノードが毎日実行されるようにスケジュールされる時間は、ワークフローの workshop_start_spark ゼロロードノードのスケジューリング時間によって決まります。現在のノードは、毎日 00:30 以降に実行されるようにスケジュールされます。
構成の保存
この例では、ビジネス要件に基づいて他の必要な設定項目を構成できます。構成が完了したら、ノードの構成タブの上部ツールバーにある
 アイコンをクリックして、ノードの構成を保存します。
アイコンをクリックして、ノードの構成を保存します。ログテーブルの分割結果の検証
先祖ノードと現在のノードが正常に実行された後、DataStudio ページの左側のナビゲーションウィンドウで [アドホッククエリ] をクリックします。アドホッククエリウィンドウで、[EMR Spark SQL] タイプのアドホッククエリタスクを作成し、SQL ステートメントを記述して、現在のノードによって作成されたテーブルが期待どおりに生成されたかどうかを確認します。
-- パーティションフィルター条件を現在の操作のデータタイムスタンプに更新する必要があります。たとえば、ノードが 2023 年 2 月 22 日に実行されるようにスケジュールされている場合、ノードのデータタイムスタンプは 20230221 であり、ノードのスケジューリング時間より 1 日早くなります。 SELECT * FROM dwd_log_info_di_spark WHERE dt ='データタイムスタンプ';説明このトピックの SQL ステートメントでは、スケジューリングパラメーター
${bizdate}が構成され、値T-1がスケジューリングパラメーターに割り当てられます。バッチコンピューティングシナリオでは、bizdate はビジネストランザクションが実行された日付を示し、これはしばしばデータタイムスタンプと呼ばれます。たとえば、当日に前日の売上高に関する統計データを収集する場合、前日はビジネストランザクションが実行された日付であり、データタイムスタンプを表します。
dws_user_info_all_di_spark ノードの構成
dwd_log_info_di_spark テーブルと ods_user_info_d_spark テーブルを uid フィールドに基づいて結合し、dws_user_info_all_di_spark テーブルを生成します。
ノードコードの構成
dws_user_info_all_di_spark ノードをダブルクリックして、ノードの構成タブに移動します。構成タブで、次のステートメントを記述します。
-- シナリオ: 以下のサンプルコードの SQL ステートメントは Spark SQL ステートメントです。dwd_log_info_di_spark テーブルと ods_user_info_d_spark テーブルを uid フィールドに基づいて結合し、指定された dt パーティションにデータを書き込むことができます。 -- 注: -- DataWorks は、スケジューリングシナリオで日次増分データを宛先テーブルの対応するパーティションに書き込むために使用できるスケジューリングパラメーターを提供します。 -- 実際の開発シナリオでは、ノードコード内で ${変数名} 形式で変数を定義できます。その後、ノードの構成タブの [プロパティ] タブで、スケジューリングパラメーターを値として変数に割り当てることができます。これにより、スケジューリングシナリオでのスケジューリングパラメーターの構成に基づいて、ノードコード内のスケジューリングパラメーターの値が動的に置き換えられます。 CREATE TABLE IF NOT EXISTS dws_user_info_all_di_spark ( uid STRING COMMENT 'ユーザー ID', gender STRING COMMENT '性別', age_range STRING COMMENT '年齢範囲', zodiac STRING COMMENT '星座', device STRING COMMENT '端末タイプ', method STRING COMMENT 'HTTP リクエストタイプ', url STRING COMMENT 'url', `time` STRING COMMENT 'yyyymmddhh:mi:ss 形式の時間' ) PARTITIONED BY (dt STRING); -- パーティションの追加 ALTER TABLE dws_user_info_all_di_spark ADD IF NOT EXISTS PARTITION (dt = '${bizdate}'); -- 基本的なユーザー情報テーブルと新しいログテーブルからデータを挿入 INSERT OVERWRITE TABLE dws_user_info_all_di_spark PARTITION (dt = '${bizdate}') SELECT COALESCE(a.uid, b.uid) AS uid, b.gender AS gender, b.age_range AS age_range, b.zodiac AS zodiac, a.device AS device, a.method AS method, a.url AS url, a.tm FROM dwd_log_info_di_spark as a LEFT OUTER JOIN ods_user_info_d_spark as b ON a.uid = b.uid ;ノードのスケジューリングプロパティの構成
セクション
説明
スクリーンショット
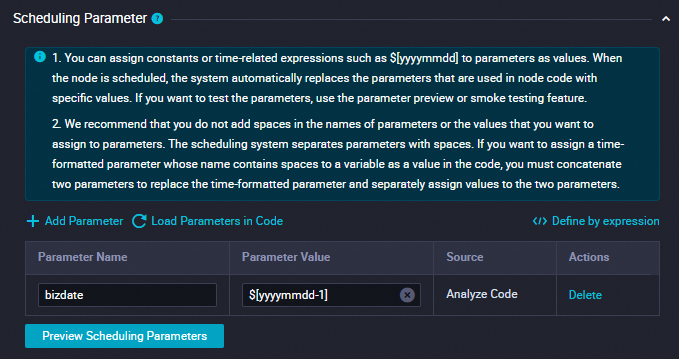
パラメーターの追加
[スケジューリングパラメーター] セクションで [パラメーターの追加] をクリックします。テーブルに表示される行で、スケジューリングパラメーターとその値を指定できます。
パラメーター名を
bizdateに設定します。パラメーター値を
$[yyyymmdd-1]に設定します。
詳細については、「スケジューリングパラメーターの構成」をご参照ください。
依存関係
このセクションでは、出力テーブルが現在のノードの出力名として使用されていることを確認します。
出力テーブルは
workspacename.nodename形式で命名されます。詳細については、「スケジューリング依存関係の構成」をご参照ください。
 説明
説明[スケジュール] セクションで、[スケジューリングサイクル] パラメーターを [日] に設定します。現在のノードの [スケジュールされた時間] パラメーターを個別に構成する必要はありません。現在のノードが毎日実行されるようにスケジュールされる時間は、ワークフローの workshop_start_spark ゼロロードノードのスケジューリング時間によって決まります。現在のノードは、毎日 00:30 以降に実行されるようにスケジュールされます。
構成の保存
この例では、ビジネス要件に基づいて他の必要な設定項目を構成できます。構成が完了したら、ノードの構成タブの上部ツールバーにある
アイコンをクリックして、ノードの構成を保存します。データマージ結果の検証
先祖ノードと現在のノードが正常に実行された後、DataStudio ページの左側のナビゲーションウィンドウで [アドホッククエリ] をクリックします。アドホッククエリウィンドウで、[EMR Spark SQL] タイプのアドホッククエリタスクを作成し、SQL ステートメントを記述して、現在のノードによって作成されたテーブルが期待どおりに生成されたかどうかを確認します。
-- パーティションフィルター条件を現在の操作のデータタイムスタンプに更新する必要があります。たとえば、ノードが 2024 年 8 月 8 日に実行されるようにスケジュールされている場合、ノードのデータタイムスタンプは 20240807 であり、ノードのスケジューリング時間より 1 日早くなります。 SELECT * FROM dws_user_info_all_di_spark WHERE dt ='データタイムスタンプ';説明このトピックの SQL ステートメントでは、スケジューリングパラメーター
${bizdate}が構成され、値T-1がスケジューリングパラメーターに割り当てられます。バッチコンピューティングシナリオでは、bizdate はビジネストランザクションが実行された日付を示し、これはしばしばデータタイムスタンプと呼ばれます。たとえば、当日に前日の売上高に関する統計データを収集する場合、前日はビジネストランザクションが実行された日付であり、データタイムスタンプを表します。
ads_user_info_1d_spark ノードの構成
dws_user_info_all_di_spark テーブルに対して最大値とカウント計算を実行し、消費用の基本的なユーザープロファイルテーブルとして ads_user_info_1d_spark テーブルを生成します。
ノードコードの構成
ads_user_info_1d_spark ノードをダブルクリックして、ノードの構成タブに移動します。構成タブで、次のステートメントを記述します。
-- シナリオ: 以下のサンプルコードの SQL ステートメントは Spark SQL ステートメントです。Spark SQL 関数を使用して、Spark SQL で dws_user_info_all_di_spark テーブルをさらに処理し、ads_user_info_1d_spark テーブルにデータを書き込むことができます。 -- 注: -- DataWorks は、スケジューリングシナリオで日次増分データを宛先テーブルの対応するパーティションに書き込むために使用できるスケジューリングパラメーターを提供します。 -- 実際の開発シナリオでは、ノードコード内で ${変数名} 形式で変数を定義できます。その後、ノードの構成タブの [プロパティ] タブで、スケジューリングパラメーターを値として変数に割り当てることができます。これにより、スケジューリングシナリオでのスケジューリングパラメーターの構成に基づいて、ノードコード内のスケジューリングパラメーターの値が動的に置き換えられます。 CREATE TABLE IF NOT EXISTS ads_user_info_1d_spark ( uid STRING COMMENT 'ユーザー ID', device STRING COMMENT '端末タイプ', pv BIGINT COMMENT 'pv', gender STRING COMMENT '性別', age_range STRING COMMENT '年齢範囲', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING ); ALTER TABLE ads_user_info_1d_spark ADD IF NOT EXISTS PARTITION (dt='${bizdate}'); INSERT OVERWRITE TABLE ads_user_info_1d_spark PARTITION (dt='${bizdate}') SELECT uid , MAX(device) , COUNT(0) AS pv , MAX(gender) , MAX(age_range) , MAX(zodiac) FROM dws_user_info_all_di_spark WHERE dt = '${bizdate}' GROUP BY uid;ノードのスケジューリングプロパティの構成
セクション
説明
スクリーンショット
パラメーターの追加
[スケジューリングパラメーター] セクションで [パラメーターの追加] をクリックします。テーブルに表示される行で、スケジューリングパラメーターとその値を指定できます。
パラメーター名を
bizdateに設定します。パラメーター値を
$[yyyymmdd-1]に設定します。
詳細については、「スケジューリングパラメーターの構成」をご参照ください。
依存関係
このセクションでは、出力テーブルが現在のノードの出力名として使用されていることを確認します。
出力テーブルは
workspacename.nodename形式で命名されます。詳細については、「スケジューリング依存関係の構成」をご参照ください。
 説明
説明[スケジュール] セクションで、[スケジューリングサイクル] パラメーターを [日] に設定します。現在のノードの [スケジュールされた時間] パラメーターを個別に構成する必要はありません。現在のノードが毎日実行されるようにスケジュールされる時間は、ワークフローの workshop_start_spark ゼロロードノードのスケジューリング時間によって決まります。現在のノードは、毎日 00:30 以降に実行されるようにスケジュールされます。
構成の保存
この例では、ビジネス要件に基づいて他の必要な設定項目を構成できます。構成が完了したら、ノードの構成タブの上部ツールバーにある
アイコンをクリックして、ノードの構成を保存します。ユーザープロファイルテーブルの結果の検証
先祖ノードと現在のノードが正常に実行された後、DataStudio ページの左側のナビゲーションウィンドウで [アドホッククエリ] をクリックします。アドホッククエリウィンドウで、[EMR Spark SQL] タイプのアドホッククエリタスクを作成し、SQL ステートメントを記述して、現在のノードによって作成されたテーブルが期待どおりに生成されたかどうかを確認します。
-- パーティションフィルター条件を現在の操作のデータタイムスタンプに更新する必要があります。たとえば、ノードが 2023 年 2 月 22 日に実行されるようにスケジュールされている場合、ノードのデータタイムスタンプは 20230221 であり、ノードのスケジューリング時間より 1 日早くなります。 SELECT * FROM ads_user_info_1d_spark WHERE dt ='データタイムスタンプ';説明このトピックの SQL ステートメントでは、スケジューリングパラメーター
${bizdate}が構成され、値T-1がスケジューリングパラメーターに割り当てられます。バッチコンピューティングシナリオでは、bizdate はビジネストランザクションが実行された日付を示し、これはしばしばデータタイムスタンプと呼ばれます。たとえば、当日に前日の売上高に関する統計データを収集する場合、前日はビジネストランザクションが実行された日付であり、データタイムスタンプを表します。
ステップ 4: ワークフローのコミット
ワークフローを構成した後、ワークフローが期待どおりに実行できるかどうかをテストします。テストが成功したら、ワークフローをコミットし、ワークフローがデプロイされるのを待ちます。
ワークフローの構成タブで、
 アイコンをクリックしてワークフローを実行します。
アイコンをクリックしてワークフローを実行します。ワークフロー内のすべてのノードの横に
 アイコンが表示されたら、
アイコンが表示されたら、 アイコンをクリックしてワークフローをコミットします。
アイコンをクリックしてワークフローをコミットします。[コミット] ダイアログボックスで、コミットするノードを選択し、説明を入力してから、[I/O の不整合に関するアラートを無視] を選択します。次に、[確認] をクリックします。
ワークフローがコミットされた後、ワークフロー内のノードをデプロイできます。
ワークフローの構成タブの右上隅にある [デプロイ] をクリックします。[デプロイタスクの作成] ページが表示されます。
デプロイするノードを選択し、[デプロイ] をクリックします。[デプロイタスクの作成] ダイアログボックスで、[デプロイ] をクリックします。
ステップ 4: 本番環境でのノードの実行
ある日にノードをデプロイすると、ノードに対して生成されたインスタンスは翌日に実行されるようにスケジュールできます。[データバックフィル] 機能を使用して、デプロイされたワークフロー内のノードのデータをバックフィルできます。これにより、ノードが本番環境で実行できるかどうかを確認できます。詳細については、「データのバックフィルとデータバックフィルインスタンスの表示 (新バージョン)」をご参照ください。
ノードをデプロイした後、右上隅にある [オペレーションセンター] をクリックします。
ワークフローの構成タブの上部ツールバーにある [オペレーションセンター] をクリックして、[オペレーションセンター] ページに移動することもできます。
左側のナビゲーションウィンドウで、 を選択します。[自動トリガーノード] ページで、workshop_start_spark ゼロロードノードを見つけてクリックします。ノードの DAG が表示されます。
workshop_start_spark ノードを右クリックし、 を選択します。
[データバックフィル] パネルで、データをバックフィルするノードを選択し、[データタイムスタンプ] パラメーターを構成してから、[送信してリダイレクト] をクリックします。[データバックフィルインスタンスが一覧表示される] ページが表示されます。
すべての SQL ノードが正常に実行されるまで [更新] をクリックします。