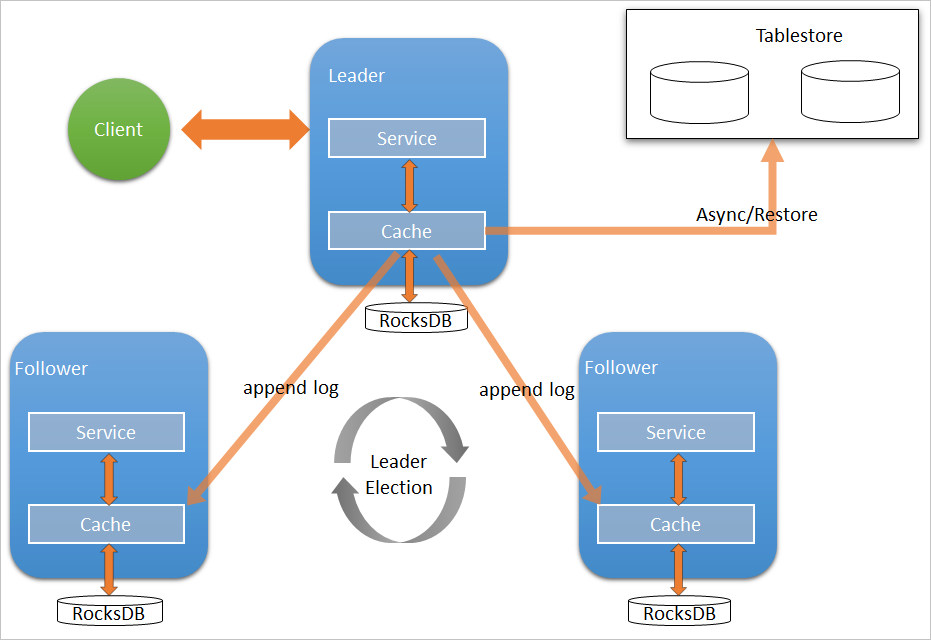
E-MapReduce (EMR) V3.27.0 以降では、JindoFS 名前空間サービスのメタデータストレージバックエンドとして Raft-RocksDB-Tablestore をサポートしています。このアーキテクチャにより、3 台のマスターノード間で高可用性が実現され、さらに Tablestore を使用したクラスター外の完全なバックアップもオプションで利用可能です(クラスター終了後も保持されます)。
仕組み
Raft-RocksDB-Tablestore アーキテクチャは、以下の 3 つのレイヤーで構成されます:
| レイヤー | 役割 | 責任 |
|---|---|---|
| Raft 合意形成 | 3 台のマスターノードが Raft グループを構成 | 書き込み成功を確認する前に、メタデータの書き込みを過半数のノードに複製します。1 台のノード障害を許容し、データ損失を防ぎます。 |
| RocksDB ローカル記憶域 | 各マスターノード | メタデータをローカルに保存します。読み取りおよび書き込みはローカルの RocksDB に対して行われるため、レイテンシーを低く保てます。 |
| Tablestore リモートバックアップ | クラスター外のオプションストア | EMR がリアルタイムで非同期にメタデータの変更を Tablestore にアップロードし、クラスター終了後も永続化される完全なレプリカを作成します。 |
Raft は書き込みのコミットに過半数(quorum)を必要とするため、3 台のマスターノードが必要です。3 台構成の場合、1 台のノード障害を許容できます。3 台未満では有効な Raft グループを構成できません。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
Tablestore インスタンスが作成済みであること。高性能インスタンスの使用を推奨します。また、トランザクション機能が有効化されている必要があります。詳細については、「インスタンスの作成」をご参照ください。
3 台のマスターノードを持つ EMR クラスターが存在すること。詳細については、「クラスターの作成」をご参照ください。
Raft-RocksDB をローカルストレージバックエンドとして構成する
ステップ 1:すべての SmartData コンポーネントを停止する
Alibaba Cloud EMR コンソールにログインします。
上部ナビゲーションバーで、クラスターが配置されているリージョンとリソースグループを選択します。
クラスター管理 タブをクリックします。
対象のクラスターを検索し、詳細 をクリックします(操作 列内)。
左側ナビゲーションウィンドウで、クラスターサービス > SmartData を選択します。
右上隅の 操作 ドロップダウンリストから、すべてのコンポーネントを停止 を選択します。
ステップ 2:名前空間サービスのパラメーターを構成する
ブロックストレージモードでの名前空間サービスパラメーターを構成します。詳細については、「JindoFS のブロックストレージモードでの使用」をご参照ください。
ステップ 3:bigboot タブで Raft パラメーターを構成する
左側ナビゲーションウィンドウで、クラスターサービス > SmartData を選択します。
構成 タブをクリックします。
サービス構成 セクションで、bigboot タブをクリックします。
以下のパラメーターを設定します:
パラメーター 説明 例 namespace.backend.type名前空間サービスのバックエンドストレージタイプ。値を raftに設定します。有効な値:rocksdb、ots、raft。デフォルト値:rocksdb。raftnamespace.backend.raft.initial-confRaft インスタンスが実行される 3 台のマスターノードのアドレス。Raft が過半数(quorum)を達成できるよう、3 台のノードが必要です(クラスターは 1 台のノード障害を許容)。それより少ない台数は使用できません。 emr-header-1:8103:0,emr-header-2:8103:0,emr-header-3:8103:0jfs.namespace.server.rpc-addressクライアントが Raft インスタンスにアクセスするための 3 台のマスターノードのアドレス。 emr-header-1:8101,emr-header-2:8101,emr-header-3:8101
ステップ 4(任意):Tablestore をリモートバックアップバックエンドとして構成する
クラスター外のメタデータバックアップを必要としない場合は、このステップをスキップしてください。
bigboot タブで、以下のパラメーターを設定します:
| パラメーター | 説明 | 例 |
|---|---|---|
namespace.ots.instance | Tablestore インスタンスの名称。 | emr-jfs |
namespace.ots.accessKey | Tablestore へのアクセスに使用する AccessKey ID。 | kkkkkk |
namespace.ots.accessSecret | Tablestore へのアクセスに使用する AccessKey Secret。 | XXXXXX |
namespace.ots.endpoint | Tablestore インスタンスのエンドポイント。トラフィックをプライベートネットワーク内に留めるため、VPC エンドポイントを使用してください。 | http://emr-jfs.cn-hangzhou.vpc.tablestore.aliyuncs.com |
namespace.backend.raft.async.ots.enabled | Tablestore への非同期アップロードを有効化します。値を true に設定します。SmartData の初期化が完了する前に、この設定を行う必要があります。 初期化がすでに完了している場合、メタデータは既にローカルの RocksDB に書き込まれており、この設定は無効になります。 | true |
ステップ 5:構成を保存してすべてのコンポーネントを起動する
サービス構成 セクションの右上隅で、保存 をクリックします。
変更の確認 ダイアログボックスで、説明を入力し、自動構成更新 を有効化します。
OK をクリックします。
右上隅の 操作 ドロップダウンリストから、すべてのコンポーネントを起動 を選択します。
Tablestore からのメタデータ回復
Tablestore をリモートバックアップバックエンドとして構成した場合、Tablestore には JindoFS のメタデータの完全なレプリカが保持されます。元の EMR クラスターが停止またはリリースされた後でも、新しいクラスターにメタデータを復元することで、元のファイルに再度アクセスできます。
ステップ 1(任意):回復の準備
回復結果の検証のために、元のクラスターのメタデータ統計情報を記録します:
hadoop fs -count jfs://test/ 1596 1482809 25 jfs://test/ (フォルダ数) (ファイル数)元のクラスター上で実行中のすべてのジョブを停止します。EMR がすべてのメタデータを Tablestore に同期するまで、30~120 秒待ちます。同期状況を確認するには、以下のコマンドを実行します:
jindo jfs -metaStatus -detail出力にリーダーノードの
_synced=1が表示された場合、すべてのメタデータが Tablestore に同期されています。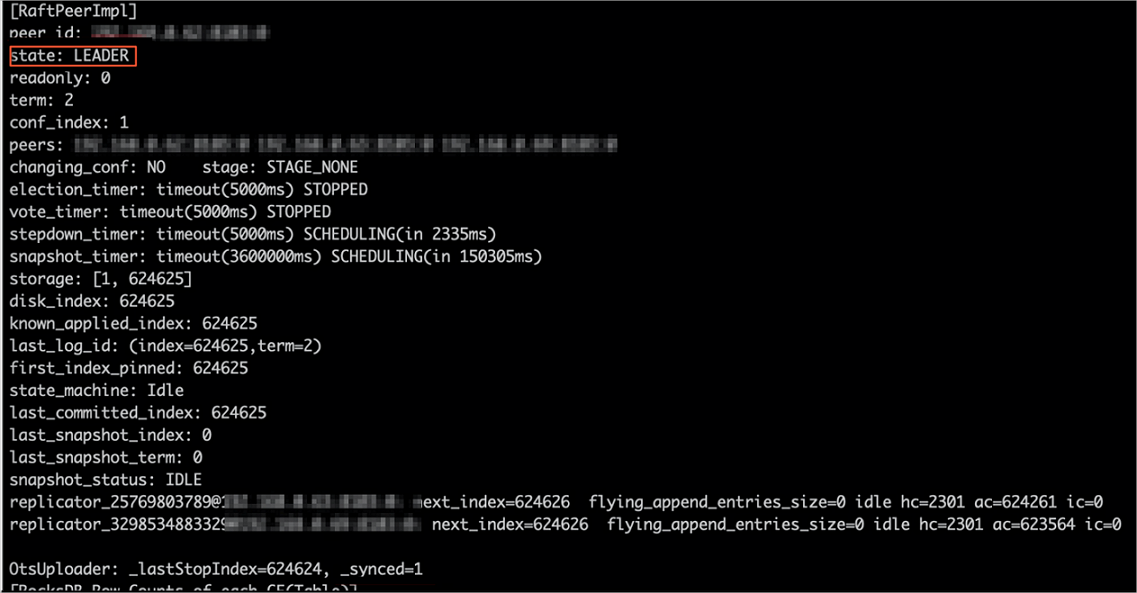
元のクラスターを停止またはリリースします。進行前に、Tablestore インスタンスにアクセスするクラスターが存在しないことを確認してください。
同期が完了する前にクラスターを停止した場合(_synced=1 がまだ表示されていない場合)、最後の同期ポイント以降に書き込まれたメタデータは、回復後に利用できなくなります。クラスターを停止する前に、必ず同期が完了していることを確認してください。
ステップ 2:新しい EMR クラスターを作成する
Tablestore インスタンスと同じリージョンに EMR クラスターを作成します。その後、すべての SmartData コンポーネントを停止します。詳細については、「Raft-RocksDB をローカルストレージバックエンドとして構成する」の「ステップ 1」をご参照ください。
ステップ 3:回復パラメーターを設定する
SmartData サービスの bigboot タブで、以下のパラメーターを設定します:
| パラメーター | 説明 | 必須値 |
|---|---|---|
namespace.backend.raft.async.ots.enabled | 回復中に Tablestore への非同期アップロードを無効化します。この値を false に設定すると、メタデータの復元中に Tablestore への書き込みが防止され、データの不整合が回避されます。 | false |
namespace.backend.raft.recovery.mode | Tablestore からのメタデータ回復を有効化します。 | true |
ステップ 4:構成を保存してすべてのコンポーネントを起動する
サービス構成 セクションの右上隅で、保存 をクリックします。
変更の確認 ダイアログボックスで、説明を入力し、自動構成更新 を有効化します。
OK をクリックします。
右上隅の 操作 ドロップダウンリストから、すべてのコンポーネントを起動 を選択します。
ステップ 5:回復進捗を監視する
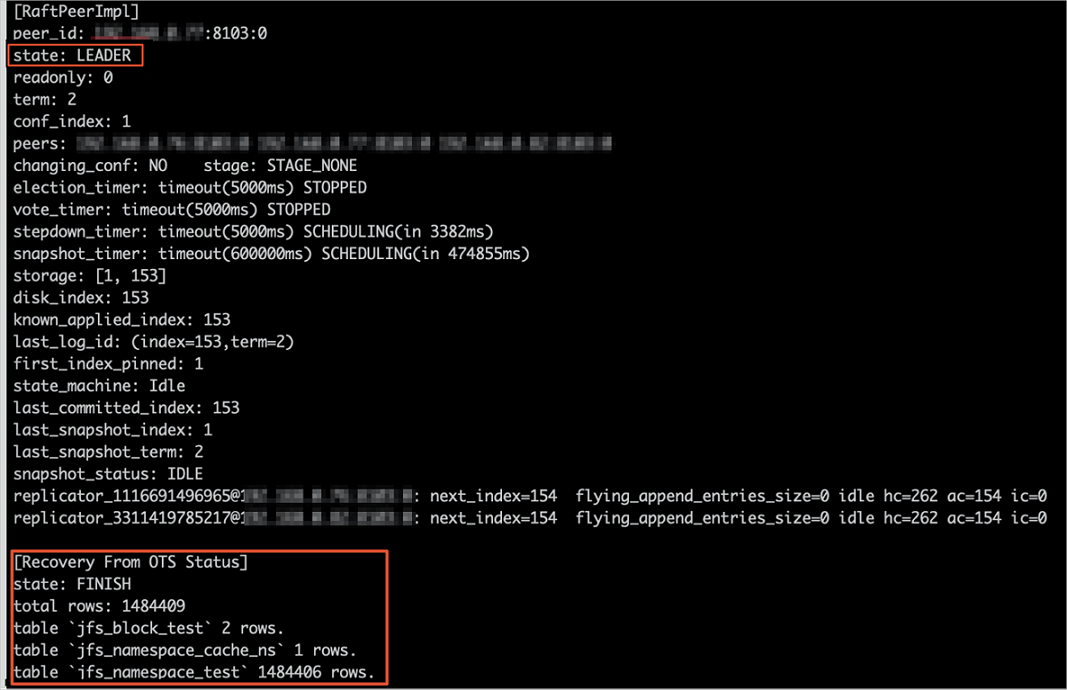
SmartData の起動後、EMR は自動的に Tablestore からメタデータをローカルの Raft-RocksDB にプルします。進捗を確認するには、以下のコマンドを実行します:
jindo jfs -metaStatus -detailリーダーノードの状態が FINISH になった場合、回復は完了です。
回復中はクラスターが読み取り専用になります。書き込み操作は以下のエラーを返します。これは想定される動作です。クラスターは、まだ復元されていないデータを上書きして不整合を引き起こすことを防ぐため、読み取り専用モードを強制します。
java.io.IOException: ErrorCode : 25021 , ErrorMsg: Namespace is under recovery mode, and is read-only.ステップ 6(任意):ファイルおよびフォルダー数の検証
以下のコマンドを実行して、メタデータが元のクラスターと一致していることを確認します:
# ファイルおよびフォルダー数が元のクラスターと一致することを確認
[hadoop@emr-header-1 ~]$ hadoop fs -count jfs://test/
1596 1482809 25 jfs://test/
# ファイル内容を読み取り
[hadoop@emr-header-1 ~]$ hadoop fs -cat jfs://test/testfile
this is a test file
# ディレクトリを一覧表示
[hadoop@emr-header-1 ~]$ hadoop fs -ls jfs://test/
Found 3 items
drwxrwxr-x - root root 0 2020-03-25 14:54 jfs://test/emr-header-1.cluster-50087
-rw-r----- 1 hadoop hadoop 5 2020-03-25 14:50 jfs://test/haha-12096RANDOM.txt
-rw-r----- 1 hadoop hadoop 20 2020-03-25 15:07 jfs://test/testfileステップ 7:回復モードを終了する
メタデータの検証が完了したら、Tablestore への非同期アップロードを再び有効化し、回復モードを無効化します。
bigboot タブで、以下のパラメーターを更新します:
| パラメーター | 説明 | 必須値 |
|---|---|---|
namespace.backend.raft.async.ots.enabled | 非同期アップロードを再び有効化し、新しいクラスターが Tablestore へのバックアップを開始できるようにします。 | true |
namespace.backend.raft.recovery.mode | 回復モードを無効化し、クラスターを書き込み可能にします。 | false |
その後、クラスターを再起動します:
クラスター管理 タブをクリックします。
対象のクラスターを検索し、操作 列で その他 をクリックして、再起動 を選択します。
クイックリファレンス:主なコマンド
| タスク | コマンド |
|---|---|
| メタデータ同期および回復状況の確認 | jindo jfs -metaStatus -detail |
| ファイルおよびフォルダー数のカウント | hadoop fs -count jfs://test/ |
| ファイルの読み取り | hadoop fs -cat jfs://test/<filename> |
| ディレクトリの一覧表示 | hadoop fs -ls jfs://test/ |
よくある質問
同期が完了する前に元のクラスターを停止した場合、どうなりますか?
最後の同期チェックポイント以降に書き込まれたメタデータは、回復後に利用できなくなります。データ損失を最小限に抑えるため、クラスターを停止する前に、_synced=1 が jindo jfs -metaStatus -detail の出力にリーダーノードで表示されていることを必ず確認してください。
3 台ではなく 2 台のマスターノードを使用できますか?
いいえ。Raft は書き込みのコミットに過半数(ノードの多数派)を必要とします。2 台のノードでは、1 台の障害発生時に過半数が成立せず、Raft グループは機能しません。1 台の障害を許容可能な有効な Raft グループを構成するには、最低でも 3 台のノードが必要です。
なぜ回復中はクラスターが読み取り専用になるのですか?
回復モードでは、Tablestore からまだ復元されていないデータを上書きすることを防ぐため、書き込み操作が禁止されます。書き込みを許可すると、後から復元されるメタデータが、より新しいデータと競合または上書きされ、データの不整合を引き起こす可能性があります。ステップ 7 を完了してクラスターを再起動すると、クラスターは自動的に読み取り専用モードを終了します。
回復途中で失敗した場合はどうすればよいですか?
回復が中断された場合、新しいクラスターを namespace.backend.raft.recovery.mode=true を指定して再起動します。EMR は Tablestore からのメタデータのプルを再開します。jindo jfs -metaStatus -detail で進捗を確認し、リーダーノードの状態が FINISH になるまで待ってから、次の手順に進んでください。
複数のクラスターが同じ Tablestore インスタンスを共有できますか?
いいえ。新しいクラスターでの回復を開始する前に、Tablestore インスタンスにアクセスするすべてのクラスターを停止またはリリースしてください。複数のクラスターが同時に同じ Tablestore インスタンスに書き込みまたは読み取りを行うと、メタデータバックアップが破損する可能性があります。