Jindo AuditLog は、ブロックストレージモードまたはキャッシュモードで動作する E-MapReduce (EMR) JindoFS 名前空間における追加、削除、名前変更操作を記録します。AuditLog を使用して、名前空間へのアクセスを追跡し、異常なリクエストを検出し、エラーのトラブルシューティングを行います。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
AuditLog の仕組み
名前空間に対して AuditLog を有効化すると、JindoFS は追加、削除、名前変更の各操作ごとに OSS にログエントリを書き込みます。続行する前に理解しておくべき主な動作は以下のとおりです。
-
ログファイルは指定した OSS パスに保存され、1 ファイルあたり最大 5 GB までとなります。
-
OSS のライフサイクルルールを使用して、ログの保存期間を制御します。保存期間を指定しない場合、ログは無期限に蓄積されます。
AuditLog のフォーマット
各ログエントリには、以下のフィールドが含まれます。
| フィールド | 説明 |
|---|---|
Time |
タイムスタンプ(yyyy-MM-dd hh:mm:ss.SSS 形式) |
allowed |
操作が許可されたかどうか: true または false |
ugi |
操作を実行したユーザー(認証方式を含む) |
ip |
クライアントの IP アドレス |
ns |
ブロックストレージモードでの名前空間名 |
cmd |
操作コマンド |
src |
ソースパス |
dest |
宛先パス(空欄可) |
perm |
操作対象ファイルの権限 |
ログエントリの例:
2020-07-09 18:29:24.689 allowed=true ugi=hadoop (auth:SIMPLE) ip=127.0.0.1 ns=test-block cmd=CreateFileletRequest src=jfs://test-block/test/test.snappy.parquet dst=null perm=::rwxrwxr-xAuditLog の有効化
手順 1:構成パラメーターの追加
-
Alibaba Cloud EMR コンソールにログインします。
-
上部ナビゲーションバーで、ご利用のクラスターが配置されているリージョンを選択します。必要に応じてリソースグループも選択します。デフォルトでは、アカウントのすべてのリソースが表示されます。
-
クラスターマネジメント タブをクリックします。
-
一覧から対象のクラスターを見つけ、[操作] 列の 詳細 をクリックします。
-
左側ナビゲーションウィンドウで、クラスターサービス > SmartData をクリックします。
-
構成 タブをクリックし、サービス構成セクションで 名前空間 タブをクリックします。
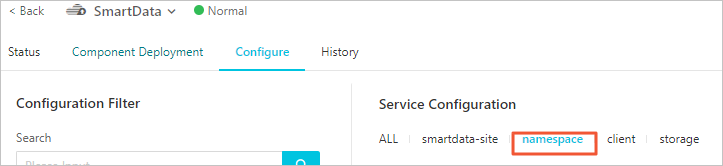
-
右上隅の カスタム構成 をクリックします。
-
構成項目の追加 ダイアログボックスで、以下のパラメーターを設定します。
パラメーター 説明 必須 jfs.namespaces.{ns}.auditlog.enable特定の名前空間に対して AuditLog を有効化します。 trueを指定すると有効化、falseを指定すると無効化されます。はい namespace.sysinfo.oss.uriログ保存用の OSS パス。形式は oss://<yourbucket>/auditLogで、<yourbucket>の部分を実際のバケット名に置き換えてください。はい namespace.sysinfo.oss.access.keyOSS バケット用の AccessKey ID。 いいえ namespace.sysinfo.oss.access.secretOSS バケット用の AccessKey Secret。 いいえ namespace.sysinfo.oss.endpointOSS バケットのエンドポイント。 いいえ
手順 2: デプロイと再起動
-
サービス構成セクションの右上隅にある クライアント構成のデプロイ をクリックします。
-
クラスター活動 ダイアログボックスで説明を入力し、OK をクリックします。
-
確認ダイアログボックスで OK をクリックします。
-
右上隅の 操作 > Jindo 名前空間サービスの再起動 を選択します。
-
クラスター活動 ダイアログボックスで説明を入力し、OK をクリックします。
-
確認ダイアログボックスで OK をクリックします。
手順 3:ログの保存期間の設定
OSS のライフサイクルルールを設定して、指定日数経過後にログファイルを自動的に有効期限切れにします。
-
OSS コンソールにログインします。
-
左側ナビゲーションウィンドウで バケット をクリックし、対象のバケット名をクリックします。
-
基本設定 > ライフサイクル を選択します。ライフサイクルセクションで 設定 をクリックします。
-
ルールの作成 をクリックし、ルールのパラメーターを設定します。
-
OK をクリックします。
ログファイルの分析
jindo sql コマンドを使用して、AuditLog データに対して Spark SQL クエリを実行します。このコマンドでは、以下の 3 つの組み込みテーブルが提供されます。
| テーブル | 説明 |
|---|---|
audit_log_source |
生の AuditLog データ(パーティションテーブル) |
audit_log |
クリーンアップ済みの AuditLog データ |
fs_image |
fsimage ログデータ(パーティションテーブル) |
利用可能なパラメーターを確認するには、jindo sql --help を実行します。
| パラメーター | 説明 |
|---|---|
-f |
実行する SQL ファイルを指定します |
-i |
コマンド起動後に初期化 SQL スクリプトを自動的に実行します |
Spark リソースのチューニング
jindo sql は Spark を基盤としているため、デフォルトでは限定的なリソースで起動することがあります。クエリ実行前に、環境変数 JINDO_SPARK_OPTS を設定してリソース割り当てを調整してください。
export JINDO_SPARK_OPTS="--conf spark.driver.memory=4G --conf spark.executor.instances=20 --conf spark.executor.cores=5 --conf spark.executor.memory=20G"クエリの例
以下のコマンドで利用可能なデータを確認できます。
-- 利用可能なすべてのテーブルを一覧表示
show tables;
-- audit_log_source テーブルのパーティションを表示
show partitions audit_log_source;
-- テーブル構造を確認
desc formatted audit_log_source;show tables の出力例:

show partitions audit_log_source の出力例:

生ログデータをクエリします。
select * from audit_log_source limit 10;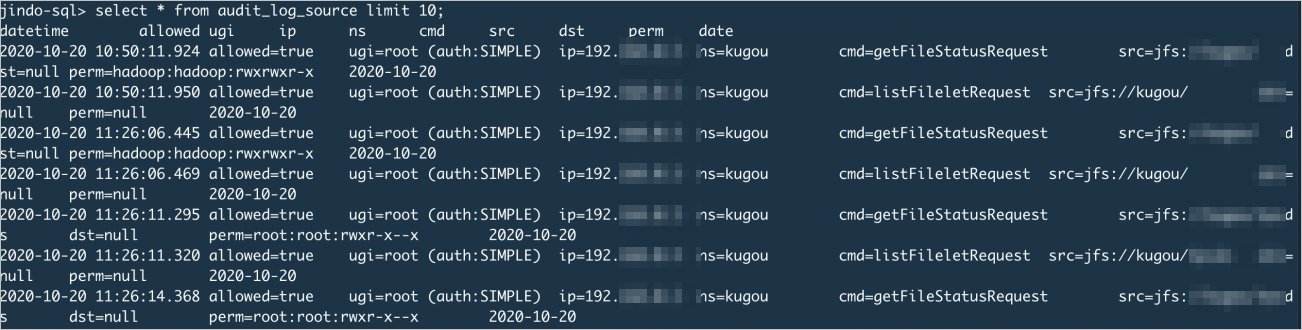
クリーンアップ済みログデータをクエリします。
select * from audit_log limit 10;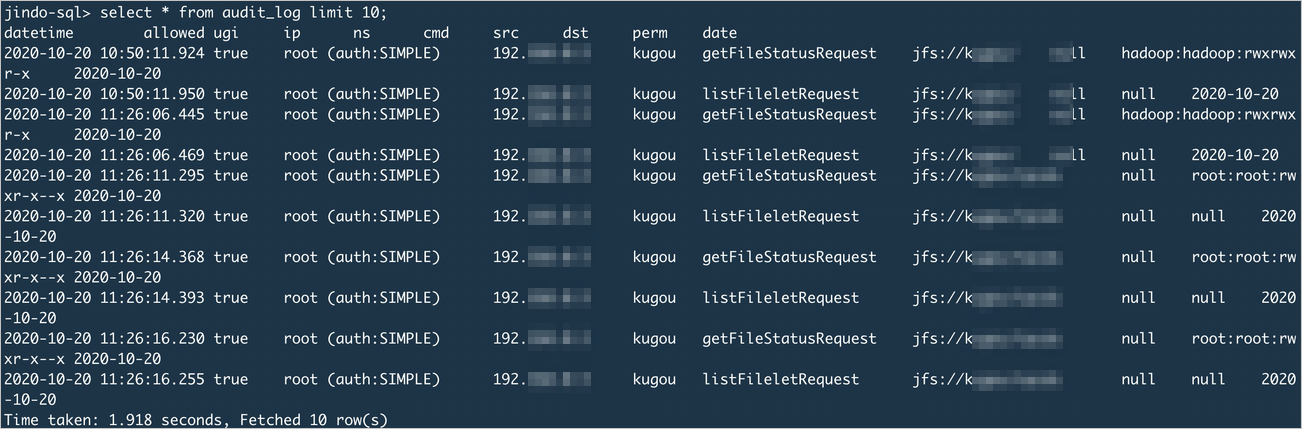
特定の日付におけるコマンド使用頻度の統計情報を収集します。
