Apache Tez は、Apache Hadoop 上に構築された分散コンピューティングフレームワークであり、有向非循環グラフ (DAG) を用いてビッグデータタスクを実行します。ECS 上の EMR では、Apache Tez は Apache Hive の代替実行エンジンとして機能し、デフォルトの MapReduce バックエンドと比較して、クエリ性能および安定性を向上させます。
以下の図は、Hive が MapReduce を使用する場合と Tez を使用する場合のタスク送信方法を示しています。
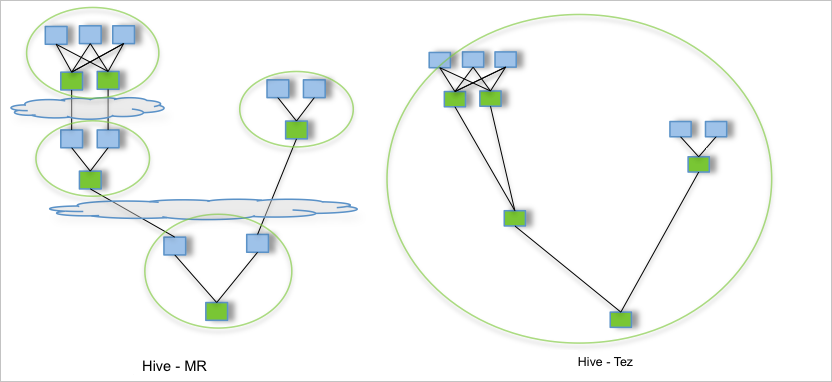
Apache Tez の詳細については、「Apache Tez ドキュメント」をご参照ください。
Tez エンジンの有効化
hive.execution.engine パラメーターを tez に設定し、Hive を再起動することで、クラスター上のすべての Hive SQL クエリに対して Tez をアクティブな実行エンジンとして適用できます。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
Hive がインストール済みの ECS 上の EMR クラスター
EMR コンソール へのアクセス権限
操作手順
お使いのクラスターの[サービス] タブに移動します。
EMR コンソールにログインします。左側のナビゲーションウィンドウで、[EMR On ECS] をクリックします。
上部のナビゲーションバーから、クラスターが配置されているリージョンを選択し、ビジネス要件に応じてリソースグループを選択します。
EMR on ECS ページで、管理するクラスターの [アクション] 列の [サービス] をクリックします。
[サービス] タブで、Hive セクションの [設定] をクリックします。
hive.execution.engineパラメーターをtezに設定します。検索ボックスに
hive.execution.engineを入力します。値を
tezに設定し、[保存] をクリックします。表示されたダイアログボックスで、[実行理由] フィールドに理由を入力し、[保存] をクリックします。
変更を反映させるために Hive を再起動します。
[ステータス] タブをクリックします。
右上隅で、[その他] > [再起動] を選択します。
表示されるダイアログボックスで、[実行理由] フィールドに理由を入力し、[OK] をクリックします。
[確認] ダイアログボックスで、[OK] をクリックします。
Tez Web UI へのアクセス
[アクセス リンクとポート] タブで、[Tez UI] に対応する URL をクリックして、Tez Web UI を開きます。
詳細については、「オープンソースコンポーネントの Web UI へのアクセス」をご参照ください。