Kafka ブローカーに接続されたディスクの空き容量が不足すると、そのディスク上の Kafka ログディレクトリがオフラインになります。オフライン状態になったディレクトリ内のパーティションレプリカは読み取りおよび書き込みができなくなり、対象のパーティションは可用性を失います。また、リーダーレプリカは他のブローカーへ移行し、それらの負荷が増加します。クラスターの健全性を早期に回復させるため、ディスク使用量の過剰な増加を速やかに解消してください。
本トピックでは、E-MapReduce (EMR) Kafka のバージョン 2.4.1 を例として説明します。
仕組み
Kafka はすべてのメッセージデータをディスク上のログディレクトリに書き込みます。各ブローカーには複数のディスクが接続されており、それぞれに 1 つ以上のログディレクトリが配置されます。ディスクの使用率が上限に達した場合、以下の処理が実行されます:
-
当該ディスク上のログディレクトリが オフライン になります。
-
オフライン状態のディレクトリ内のパーティションレプリカは、読み取りおよび書き込みを受け付けなくなります。
-
Kafka はリーダーレプリカを他のブローカーへ移行させ、それらの負荷を増加させます。
-
ディスクの問題が解決されるまで、クラスターの可用性およびフォールトトレランスが低下します。
ディスク使用率の監視
EMR Kafka クラスターに対して、OfflineLogDirectoryCount メトリックを用いた CloudMonitor アラートを設定します。この値が 0 を超える場合、少なくとも 1 つのログディレクトリが既にオフラインになっています。直ちに、以下のいずれかの回復戦略を適用してください。
回復戦略の選択
| 戦略 | 適用タイミング | リスク | 工数 |
|---|---|---|---|
| ディスクのサイズ変更 | ブローカーにアタッチされたディスクの容量が不足している場合 | 低 | 低 |
| ブローカー内でのパーティションの移行 | 同一ブローカー上の複数ディスク間でディスク使用率が不均等な場合 | 中 — I/O ホットスポットが発生する可能性あり | 高 |
| ログの削除 | 不要となったビジネスログデータを削除可能、または特別なイベントにより一時的にデータ量が急増した場合 | 中 — データが完全に削除される | 中 |
ディスクのサイズ変更
満杯となったディスクのサイズを直接変更することで、データの移動を伴わずに容量を追加できます。これは、ブローカーのディスクが満杯となった際にサービスを復旧させる最もリスクが低く、かつ最も迅速な方法です。
EMR コンソールから、影響を受けたブローカーに接続されたディスクのサイズを変更します。詳細な手順については、「ディスクの拡張」をご参照ください。
ブローカー内でのパーティションの移行
ディスクが満杯になると、そのログディレクトリはオフラインとなり、kafka-reassign-partitions.sh によるパーティションの移動はできなくなります。このツールは、対象ディレクトリへのアクセスが可能な状態であることを前提としています。代わりに、ブローカーを実行している Elastic Compute Service (ECS) インスタンス上でパーティションのデータファイルを直接移動し、Kafka のメタデータファイルを更新して新しい場所を反映させます。
この戦略は、同一ブローカー内のディスク間でのみパーティションを移動します。ブローカー間でのデータ移動は行いません。
注意事項
-
パーティションの移行により、特定のディスクで I/O ホットスポットが発生し、クラスターのパフォーマンスに影響を与える可能性があります。移行を実行する前に、各移行の規模および所要時間について評価を行ってください。
-
本手順を本番環境に適用する前に、同じ Kafka バージョンを実行する非本番クラスターで事前に検証を行ってください。
操作手順
以下の手順では、テスト用トピックを用いて移行の流れを説明します。実際の環境に適用する際は、例示されているパス、トピック名、ブローカー ID をご自身の値に置き換えてください。
-
テスト用トピックの作成
-
SSH を使用して、Kafka クラスターのマスターノードにログインします。詳細については、「クラスターへのログイン」をご参照ください。
-
Broker 0 および Broker 1 上にレプリカを持つテスト用トピック
test-topicを作成します:kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --replica-assignment 0:1 --create -
トピックの状態を確認します。両方のブローカーが同期済みレプリカ (ISR) リストに表示される必要があります:
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describe期待される出力 — Broker 0 がリーダーであり、両ブローカーが ISR リストに含まれていること:
Topic: test-topic PartitionCount: 1 ReplicationFactor: 2 Configs: Topic: test-topic Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
-
-
データ書き込みのシミュレーション(既に満杯のディスクで作業中の場合は省略可):
kafka-producer-perf-test.sh --topic test-topic --record-size 1000 --num-records 600000000 --print-metrics --throughput 10240 --producer-props linger.ms=0 bootstrap.servers=core-1-1:9092 -
Broker 0 のログディレクトリの権限を制限して、ディスク満杯状態をシミュレートします。マスターノードで
emr-userアカウントに切り替え、コアノードにログインします:su emr-user ssh core-1-1root 権限を取得します:
sudo su - roottest-topic-0パーティションがどのディスク上にあるかを確認します:sudo find / -name test-topic-0出力が
/mnt/disk4/kafka/log/test-topic-0の場合、当該パーティションは/mnt/disk4上に存在します。000の権限を設定してログディレクトリをオフライン状態にシミュレートします:sudo chmod 000 /mnt/disk4/kafka/logBroker 0 が ISR リストから除外されたことを確認します:
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describe期待される出力 — Broker 0 が ISR リストから除外されていること:
Topic: test-topic PartitionCount: 1 ReplicationFactor: 2 Configs: Topic: test-topic Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1 -
Broker 0 の停止:EMR コンソールから、Broker 0 上の Kafka サービスを停止します。
-
Broker 0 上の別のディスクへパーティションデータを移動:
mv /mnt/disk4/kafka/log/test-topic-0 /mnt/disk1/kafka/log/ -
Kafka のメタデータファイルの更新:ソースディレクトリ(
/mnt/disk4/kafka/log)および送信先ディレクトリ(/mnt/disk1/kafka/log)の両方で、以下のファイルを更新します:-
replication-offset-checkpoint:ソースファイルから
test-topic関連のエントリを送信先ファイルへ移動し、両ファイルのエントリ数を更新します。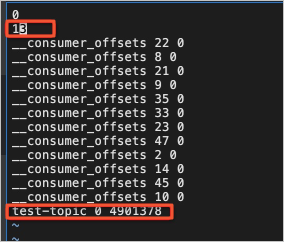
-
recovery-point-offset-checkpoint:ソースファイルから
test-topic関連のエントリを送信先ファイルへ移動し、両ファイルのエントリ数を更新します。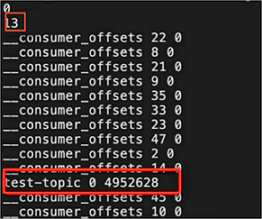
-
-
Broker 0 のログディレクトリ権限の復元:
sudo chmod 755 /mnt/disk4/kafka/log -
Broker 0 の起動:EMR コンソールから、Broker 0 上の Kafka サービスを起動します。
-
クラスターの健全性確認:
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describe両ブローカーが再び ISR リストに表示されれば、パーティションの移行が正常に完了したことを確認できます。
ログの削除
満杯となったディスクからビジネスログデータを削除し、空き容量を確保します。削除は、最も古いログセグメントから時系列順に行われます。
ログデータの削除は元に戻せません。内部 Kafka トピック(__consumer_offsets や _schema など)のデータは絶対に削除しないでください。また、アンダースコア(_)で始まるトピック名のデータも削除しないでください。
この戦略は、特別なイベントによって引き起こされた一時的なデータ量の急増からの回復に適しています。ログ削除後に保存期間(retention period)を調整しないと、再度ディスクが満杯になる可能性があります。
操作手順
-
フルディスクが存在するマシンにログオンしてください。
-
満杯となったディスクを特定し、不要なビジネスログデータを削除します:
-
Kafka クラスターのデータディレクトリ自体は削除しないでください。
-
占有容量が大きく、または不要となったトピックを特定します。
-
特定したトピックについて、最も古いデータから順にログセグメントを削除します。各ログセグメントに対応するインデックスファイルおよび timeindex ファイルも併せて削除します。
-
__consumer_offsetsや_schemaなどの内部トピックのデータは削除しないでください。
-
-
満杯となったディスクが接続されたブローカーを再起動し、ログディレクトリをオンライン状態に戻します。