JindoFS は、Alibaba Cloud Object Storage Service (OSS) 上に構築された Hadoop互換ファイルシステム (HCFS) であり、OSS をオープンソースのビッグデータエコシステムと統合するように設計されています。クライアント専用モード (SDK)、キャッシュモード、ブロックストレージモードの3つのストレージモードを提供し、それぞれ異なるパフォーマンス、コスト、運用要件に合わせて最適化されています。
ほとんどのデータレイクや AI トレーニングのワークロードでは、クライアント専用モード (SDK) またはキャッシュモードを使用します。ワークロードが完全な POSIX セマンティクス、アトミックな名前変更操作、または OSS から独立したメタデータ管理を必要とする場合は、ブロックストレージモードを使用します。
背景: オブジェクトストレージとファイルシステムの違い
OSS は、データを階層型ファイルシステムとしてではなく、オブジェクトとして保存します。これにより、オブジェクトストレージは高度にスケーラブルでコスト効率が高くなりますが、アトミックな名前変更、高速シーク、追加操作などの POSIX ファイルセマンティクスに依存するワークロードにはギャップが生じます。JindoFS は、OSS の上にファイルシステムセマンティクスをレイヤー化することで、このギャップを埋めます。3つのモードはそれぞれ、シンプルさ、パフォーマンス、運用オーバーヘッドのバランスが異なります。
クライアント専用モード (SDK)
クライアント専用モードは、分散サービスなしで OSS への Hadoop互換インターフェイスを提供します。Hadoop コミュニティの OSS FileSystem や S3A FileSystem と同様に機能し、Apache Hive や Apache Spark などのコンピューティングエンジンが OSS データにアクセスする方法を最適化します。
ファイルは OSS にオブジェクトとして保存されたままです。JindoFS は、Hadoop エコシステム向けにクライアント側の接続、拡張、最適化されたアクセスのみを追加します。このモードを設定するには、JindoFS SDK JAR パッケージをクラスパスディレクトリにアップロードします。
このモードは、最低限の運用オーバーヘッドと最高の拡張性を備えています。シンプルさと弾力的スケーリングがキャッシングよりも重要となるバッチ分析やワークロードに適しています。
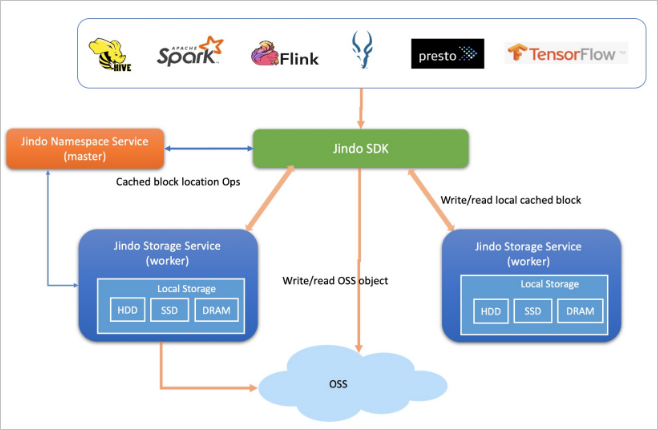
キャッシュモード
キャッシュモードは、Jindo のキャッシングレイヤーを使用した分散データキャッシングにより、クライアント専用モード (SDK) を拡張します。メタデータキャッシングと分散データキャッシングをサポートし、OSS との完全なデータ互換性と同期を維持します。ホットデータ (総データ量の約20%) は、クラスター構成に応じて、メモリ、SSD、または基本ディスクにローカルでキャッシュされます。
キャッシュモードは、次の2つのアクセスパターンをサポートしています。
oss://<oss_bucket>/<oss_dir>/— オプションのキャッシングを有効にして OSS に直接アクセスします。クロスサービスアクセスに対応しています。これがデフォルトの方法です。jfs://<your_namespace>/<path_of_file>— キャッシングを有効にして JindoFS 名前空間を介してデータにアクセスします。クロスサービスアクセスには対応していません。
このモードは、スループットが重要であり、ホットデータアクセスパターンが予測可能な大規模データ分析や AI トレーニングの高速化に適しています。
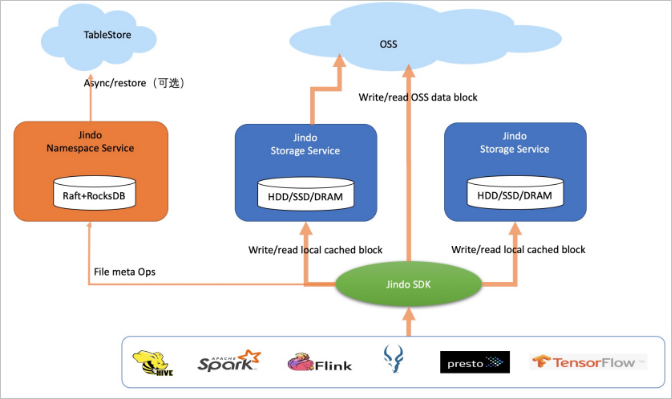
ブロックストレージモード
ブロックストレージモードは、ファイルをオブジェクトとしてではなく、OSS にブロックとして保存します。JindoFS は、名前空間サービスとストレージサービスを介してディレクトリとファイルメタデータを独立して管理し、Apache Hadoop HDFS に近い動作を実現します。データはローカルにキャッシュされ、ウォームデータとホットデータを合わせて総データ量の約60%を占めます。
ブロックストレージモードは、アトミックな名前変更、トランケート、追加、フラッシュ、同期、スナップショット操作などの高レベルストレージインターフェイスをサポートしています。これらのインターフェイスにより、Apache Flink、Apache HBase、Apache Kafka、Apache Kudu などのビッグデータエンジンは、ネイティブファイルシステムと同様に OSS に直接書き込むことができます。コールドデータに対しては、ストレージコストを削減するために透明な圧縮もサポートされています。
アクセス形式: jfs://<your_namespace>/<path_of_file> (クロスサービスアクセスには対応していません)。
このモードは、完全な POSIX セマンティクス、高いメタデータクエリパフォーマンス、またはストリーム処理エンジンとの直接統合を必要とするワークロードに適しています。
モードの選択
モード間の核となる違いは、OSS でファイルがどのように保存され、メタデータがどのように管理されるかにあります。
クライアント専用モードとキャッシュモードは、ファイルを OSS にオブジェクトとして保存します。メタデータ管理は HDFS の動作をシミュレートします。
ブロックストレージモードは、ファイルを OSS にブロックとして保存し、メタデータを独立して管理するため、HDFS に近いセマンティクスを提供します。
次の表は、3つのモードを主要なディメンションで比較したものです。
| ディメンション | クライアント専用モード (SDK) | キャッシュモード | ブロックストレージモード |
|---|---|---|---|
| 最適な用途 | バッチ分析、データレイクストレージ、最大限のスケーラビリティと最小限の運用を必要とするワークロード | 大規模分析、AI トレーニングの高速化、予測可能なホットデータパターンを持つスループットに敏感なワークロード | 完全な POSIX セマンティクス、ストリーム処理 (Flink、HBase、Kafka、Kudu)、または OSS から独立したメタデータ管理を必要とするワークロード |
| ストレージコスト | 完全なデータは OSS にあります。アーカイブストレージクラスをサポートしています。 | 完全なデータは OSS にあります。ホットデータはキャッシュされます (合計の約20%)。アーカイブストレージクラスをサポートしています。 | 完全なデータは OSS にあります。ウォームデータとホットデータはキャッシュされます (合計の約60%)。アーカイブストレージクラスをサポートしています。透明な圧縮をサポートしています。 |
| スケーラビリティ | 高い | 比較的高い | 中程度 |
| スループット | OSS 帯域幅に依存します。シーケンシャルバッチ読み取りに最適です。 | OSS 帯域幅とホットデータキャッシュ帯域幅に依存します。ホットデータセットへの繰り返しアクセスに最適です。 | OSS 帯域幅とウォームデータおよびホットデータキャッシュ帯域幅に依存します。高いローカルキャッシュヒット率を持つ混合シーケンシャルおよびランダム IO に最適です。 |
| メタデータ | HDFS メタデータ管理をシミュレートします。ディレクトリベースのストレージやファイルセマンティクスはありません。エクサバイト規模のデータをサポートします。 | ファイルデータキャッシングによる HDFS メタデータ管理をシミュレートします。エクサバイト規模のデータをサポートします。 | 最高のメタデータパフォーマンス。HDFS 互換性に近く、10億以上のファイルをサポートします。 |
| メンテナンス | 低い | 中程度 — キャッシュシステムの O&M が必要です。 | 比較的高 — 名前空間サービスとストレージサービスの O&M が必要です。 |
| セキュリティ | AccessKey ペア認証、RAM 認証、OSS アクセスログ、OSS データ暗号化 | AccessKey ペア認証、RAM 認証、OSS アクセスログ、OSS データ暗号化 | AccessKey ペア認証、UNIX コマンドまたは Apache Ranger による権限管理、AuditLog、データ暗号化 |
| アクセス形式 | oss://<oss_bucket>/<oss_dir>/ — クロスサービスアクセスに対応しています。 | oss://<oss_bucket>/<oss_dir>/ (クロスサービスアクセスに対応しています) または jfs://<your_namespace>/<path_of_file> (クロスサービスアクセスには対応していません) | jfs://<your_namespace>/<path_of_file> — クロスサービスアクセスには対応していません。 |
よくある質問
一般的なデータレイクにはどのモードを使用すべきですか?
クライアント専用モード (SDK) またはキャッシュモードです。どちらも OSS オブジェクトストレージセマンティクスと完全に互換性があり、完全なコンピューティングとストレージの分離をサポートし、柔軟にスケーリングできます。キャッシュモードはホットデータにローカルキャッシングを追加し、アクセス集約型分析や AI トレーニングのスループットを向上させます。
ブロックストレージモードが HDFS よりも多くのファイルをサポートする理由は何ですか?
ブロックストレージモードは、HDFS の最大約4億ファイルと比較して、10億以上のファイルを処理できます。オンヒープメモリの制限がなく (HDFS は JVM ヒープサイズによって制約されます)、高負荷時でもパフォーマンスがより安定します。また、ブロックストレージモードは軽量な O&M を必要とします。すべてのデータは OSS に1つのバックアップがあるため、破損したディスクやノード障害によってデータ損失が発生することはなく、ノードを自由に追加または削除できます。
ブロックストレージモードの独自の利点は何ですか?
ブロックストレージモードは、ファイルメタデータとファイルデータの両方を OSS から独立して管理するため、オブジェクトストレージがネイティブに提供できない高レベルストレージインターフェイス (アトミックな名前変更トランザクション、高パフォーマンスのローカル書き込み、トランケート、追加、フラッシュ、同期、スナップショット) をサポートできます。これらのインターフェイスは、Apache Flink、Apache HBase、Apache Kafka、Apache Kudu などのビッグデータエンジンを OSS に直接接続するために必要です。
ブロックストレージモードにはコスト上の利点もあります。データの60%をローカルでキャッシングする (ウォームデータとホットデータ) ことは、読み取りの大部分が OSS ではなくローカルクラスターから提供されることを意味し、エグレスコストを削減し、頻繁にアクセスされるデータのレイテンシーを改善します。