Flink StarRocks コネクタは、Stream Load を使用してデータをバッチ単位で StarRocks にロードします。これは、Apache Flink 標準の Java Database Connectivity (JDBC) コネクタ (flink-connector-jdbc) よりも大幅に高いスループットを実現します。Alibaba Cloud では、Flink StarRocks コネクタを提供しており、データをキャッシュしたうえで、Stream Load モードで一度に StarRocks へインポートする作業を支援します。本トピックでは、コネクタのセットアップ方法および StarRocks へのデータ書き込み手順について説明し、MySQL データのリアルタイム同期を実現する完全な例を示します。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
-
Apache Flink 1.11 以降(推奨:1.13)
-
フロントエンドの HTTP ポートにアクセス可能な StarRocks クラスター
プロジェクトへのコネクタの追加
GitHub の starrocks-connector-for-apache-flink リポジトリからコネクタのソースコードをダウンロードします。
プロジェクトの pom.xml に以下の依存関係を追加します。
<dependency>
<groupId>com.starrocks</groupId>
<artifactId>flink-connector-starrocks</artifactId>
<!-- for Flink 1.11 and 1.12 -->
<version>x.x.x_flink-1.11</version>
<!-- for Flink 1.13 -->
<version>x.x.x_flink-1.13</version>
</dependency>x.x.x を最新バージョンに置き換えてください。現在のリリース情報については、「バージョン情報」ページをご参照ください。Flink コネクタを使用したデータ書き込み
このコネクタでは、StarRocks へのデータ書き込みに 2 つのアプローチが提供されています。生の JSON ストリームには「方法 1」を、SQL によるテーブル作成および構造化データには「方法 2」をご利用ください。
方法 1:DataStream API
// -------- 生の JSON 文字列ストリームを使用した sink --------
fromElements(new String[]{
"{\"score\": \"99\", \"name\": \"stephen\"}",
"{\"score\": \"100\", \"name\": \"lebron\"}"
}).addSink(
StarRocksSink.sink(
// sink オプション
StarRocksSinkOptions.builder()
.withProperty("jdbc-url", "jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx")
.withProperty("load-url", "fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port")
.withProperty("username", "xxx")
.withProperty("password", "xxx")
.withProperty("table-name", "xxx")
.withProperty("database-name", "xxx")
.withProperty("sink.properties.format", "json")
.withProperty("sink.properties.strip_outer_array", "true")
.build()
)
);
// -------- ストリーム変換を使用した sink --------
class RowData {
public int score;
public String name;
public RowData(int score, String name) {
......
}
}
fromElements(
new RowData[]{
new RowData(99, "stephen"),
new RowData(100, "lebron")
}
).addSink(
StarRocksSink.sink(
// テーブル構造
TableSchema.builder()
.field("score", DataTypes.INT())
.field("name", DataTypes.VARCHAR(20))
.build(),
// sink オプション
StarRocksSinkOptions.builder()
.withProperty("jdbc-url", "jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx")
.withProperty("load-url", "fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port")
.withProperty("username", "xxx")
.withProperty("password", "xxx")
.withProperty("table-name", "xxx")
.withProperty("database-name", "xxx")
.withProperty("sink.properties.column_separator", "\\x01")
.withProperty("sink.properties.row_delimiter", "\\x02")
.build(),
// streamRowData でスロットを設定
(slots, streamRowData) -> {
slots[0] = streamRowData.score;
slots[1] = streamRowData.name;
}
)
);方法 2:SQL テーブル作成
この方法を実行する前に、com.starrocks.connector.flink.table.StarRocksDynamicTableSinkFactory を src/main/resources/META-INF/services/org.apache.flink.table.factories.Factory に追加します。
// `structure` および `properties` を指定してテーブルを作成
tEnv.executeSql(
"CREATE TABLE USER_RESULT(" +
"name VARCHAR," +
"score BIGINT" +
") WITH ( " +
"'connector' = 'starrocks'," +
"'jdbc-url'='jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx'," +
"'load-url'='fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port'," +
"'database-name' = 'xxx'," +
"'table-name' = 'xxx'," +
"'username' = 'xxx'," +
"'password' = 'xxx'," +
"'sink.buffer-flush.max-rows' = '1000000'," +
"'sink.buffer-flush.max-bytes' = '300000000'," +
"'sink.buffer-flush.interval-ms' = '5000'," +
"'sink.properties.column_separator' = '\\x01'," +
"'sink.properties.row_delimiter' = '\\x02'," +
"'sink.max-retries' = '3'" +
"'sink.properties.*' = 'xxx'" + // Stream Load プロパティ(例:`'sink.properties.columns' = 'k1, v1'`)
")"
);Sink パラメーター
以下の表では、Flink sink コネクタのすべてのパラメーターについて説明します。
| パラメーター | 必須 | デフォルト値 | 型 | 説明 |
|---|---|---|---|---|
connector |
はい | — | String | コネクタの種類です。starrocks を指定します。 |
jdbc-url |
はい | — | String | StarRocks への接続およびクエリ実行に使用する JDBC URL です。 |
load-url |
はい | — | String | フロントエンドの HTTP アドレスを、fe_ip:http_port;fe_ip:http_port の形式で指定します。複数のフロントエンドを指定する場合は、セミコロン (;) で区切ります。 |
database-name |
はい | — | String | StarRocks のデータベース名です。 |
table-name |
はい | — | String | StarRocks のテーブル名です。 |
username |
はい | — | String | StarRocks データベースへの接続に使用するユーザー名です。 |
password |
はい | — | String | StarRocks データベースへの接続に使用するパスワードです。 |
sink.semantic |
いいえ | at-least-once |
String | 配信セマンティクスです。有効な値は at-least-once および exactly-once です。 |
sink.buffer-flush.max-bytes |
いいえ | 94371840(90 MB) |
String | フラッシュをトリガーする際の最大バッファーサイズです。有効範囲:64 MB ~ 10 GB。 |
sink.buffer-flush.max-rows |
いいえ | 500000 |
String | フラッシュをトリガーする際のバッファー内の最大行数です。有効範囲:64000 ~ 5000000。 |
sink.buffer-flush.interval-ms |
いいえ | 300000 |
String | バッファーフラッシュ間隔(ミリ秒単位)です。有効範囲:1000 ~ 3600000。 |
sink.max-retries |
いいえ | 1 |
String | 失敗時の最大リトライ回数です。有効範囲:0 ~ 10。 |
sink.connect.timeout-ms |
いいえ | 1000 |
String | load-url で指定されたフロントエンドの HTTP アドレスに対する接続タイムアウト(ミリ秒単位)です。有効範囲:100 ~ 60000。 |
sink.properties.* |
いいえ | — | String | StarRocks に直接渡される Stream Load プロパティです。 |
注意事項
デフォルトのフォーマットおよびデリミタ
データはデフォルトで CSV フォーマットでインポートされます。カスタムデリミタを使用する場合は、以下を設定します。
-
sink.properties.row_delimiter— 行区切り文字(例:\\x02)。StarRocks 1.15.0 以降でサポートされます。 -
sink.properties.column_separator— 列区切り文字(例:\\x01)。
データに適した CSV デリミタが見つからない場合は、sink.properties.format=json および sink.properties.strip_outer_array=true を設定して JSON フォーマットに切り替えてください。ただし、JSON インポートのパフォーマンスは CSV と比較して低下する場合があります。
SQL クライアントでテーブルを作成およびデータを同期する際は、バックスラッシュ (\) をエスケープする必要があります。
'sink.properties.column_separator' = '\\x01'
'sink.properties.row_delimiter' = '\\x02'Exactly-once セマンティクス
sink.semantic=exactly-once を使用するには、外部システムが二相コミットプロトコルをサポートしている必要があります。StarRocks はこのプロトコルをネイティブでサポートしていないため、exactly-once 配信は Flink のチェックポイント機能に依存します。処理の流れは以下のとおりです。1. Flink がチェックポイントを生成すると、データのバッチおよびそのラベルが状態としてキャッシュされます。2. キャッシュされたデータが StarRocks に書き込まれるまで、システムはブロックされます。3. 書き込みが完了すると、Flink は次のチェックポイントを開始します。StarRocks が利用不可になった場合、接続障害により Flink sink ストリーム演算子が長時間ブロックされ、アラートが発生して Flink インポートジョブが強制終了する可能性があります。
接続性のトラブルシューティング
データのクエリは成功するが書き込みが失敗する場合、ご利用のマシンから StarRocks バックエンドの HTTP ポートに到達可能であることを確認してください。インポートジョブを送信すると、フロントエンドは書き込み操作をバックエンドの内部 IP アドレスおよび HTTP ポートに転送します。
たとえば、ご利用のマシンがパブリック IP アドレスを持ち、クラスタのフロントエンドおよびバックエンドがパブリック IP アドレス経由でアクセス可能であっても、バックエンド間のクラスタ内通信には内部 IP アドレスが使用されている場合、load-url にパブリックフロントエンドアドレスを指定すると、フロントエンドはバックエンドの内部 IP アドレスに書き込みを転送します。ご利用のマシンがこれらの内部 IP アドレスに到達できない場合、書き込みは失敗します。
インポートジョブが予期せず停止した場合は、ジョブのメモリ容量を増加させてください。
CDC を使用した MySQL データから StarRocks への同期
Flink の変更データキャプチャ(CDC)コネクタおよび StarRocks 移行ツールを活用することで、MySQL データベースを StarRocks クラスターにニアリアルタイムで同期できます。StarRocks 移行ツールは、MySQL のスキーマおよび StarRocks クラスターの構成に基づいて、自動的に CREATE TABLE ステートメントを生成します。
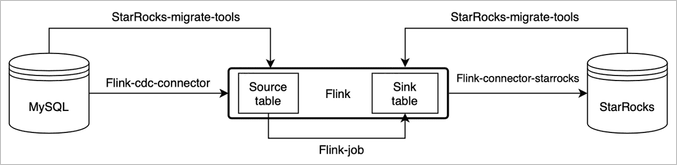
このセクションの図および一部の情報は、オープンソースの StarRocks ドキュメント内のMySQL からのリアルタイム同期を出典としています。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
-
Apache Flink 1.13(推奨)または 1.11 / 1.12
-
MySQL データベースおよび StarRocks クラスターへのアクセス権限
環境のセットアップ
-
Apache Flink をダウンロードします。推奨バージョンは Apache Flink 1.13 です。対応する最小バージョンは 1.11 です。
-
MySQL 向けの Flink CDC コネクタ をダウンロードします。ご使用の Flink バージョンに対応するパッケージを選択してください。
-
Flink StarRocks コネクタ をダウンロードします。
重要Flink StarRocks コネクタは Apache Flink 1.13、1.11、1.12 それぞれに対応した異なるバージョンが存在します。正しいバージョンをダウンロードしてください。
-
flink-sql-connector-mysql-cdc-xxx.jarおよびflink-connector-starrocks-xxx.jarの両方をflink-xxx/lib/ディレクトリにコピーします。 -
smt.tar.gz パッケージをダウンロードして解凍し、接続の詳細を含む構成ファイルを編集します。構成ファイルでは次のセクションを使用します: サンプル構成:
-
db— MySQL データベース接続情報 -
be_num— StarRocks クラスター内のノード数 -
[table-rule.N]— データベース名およびテーブル名の正規表現によるマッチングルール。ルールセットごとに 1 つのセクションを構成します。 -
flink.starrocks.*— StarRocks クラスターの構成
[db] host = 192.168.**.** port = 3306 user = root password = [other] # number of backends in StarRocks be_num = 3 # `decimal_v3` is supported since StarRocks-1.18.1 use_decimal_v3 = false # file to save the converted DDL SQL output_dir = ./result [table-rule.1] # pattern to match databases for setting properties database = ^console_19321.*$ # pattern to match tables for setting properties table = ^.*$ ############################################ ### flink sink configurations ### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated ############################################ flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030 flink.starrocks.load-url= 192.168.**.**:8030 flink.starrocks.username=root flink.starrocks.password= flink.starrocks.sink.properties.column_separator=\x01 flink.starrocks.sink.properties.row_delimiter=\x02 flink.starrocks.sink.buffer-flush.interval-ms=15000 -
テーブルの作成および同期の開始
-
starrocks-migrate-toolを実行してCREATE TABLEステートメントを生成します。出力は/resultディレクトリに保存されます。ls resultを実行して、生成されたファイルを確認します。flink-create.1.sql smt.tar.gz starrocks-create.all.sql flink-create.all.sql starrocks-create.1.sql -
StarRocks でデータベースおよびテーブルを作成します。
Mysql -h <フロントエンドの IP アドレス> -P 9030 -u root -p < starrocks-create.1.sql -
Flink テーブルを作成し、継続的なデータ同期を開始します。
重要Apache Flink 1.13 より前のバージョンを使用している場合、SQL スクリプトを直接実行できません。SQL ステートメントを 1 つずつ実行し、MySQL データベースのバイナリロギングを有効にしてください。
bin/sql-client.sh -f flink-create.1.sql -
実行中の Flink ジョブのステータスを確認します。
bin/flink list -runningFlink Web UI または
$FLINK_HOME/logディレクトリ内のログファイルで、ジョブの詳細およびステータスを確認できます。
複数のルールセットの構成
異なるプロパティを持つ複数のデータベースまたはテーブルを同期するには、各ルールセットごとに 1 つの [table-rule.N] セクションを追加します。flink.starrocks.sink パラメーターを各ルールセットごとに個別に構成できます(例:異なるインポート頻度)。
2 つのルールセットを含むサンプル構成:
[table-rule.1]
# pattern to match databases for setting properties
database = ^console_19321.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030
flink.starrocks.load-url= 192.168.**.**:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000
[table-rule.2]
# pattern to match databases for setting properties
database = ^database2.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030
flink.starrocks.load-url= 192.168.**.**:8030
flink.starrocks.username=root
flink.starrocks.password=
# If you cannot select appropriate CSV delimiters, switch to JSON format.
# Note that JSON import performance may deteriorate compared to CSV.
flink.starrocks.sink.properties.strip_outer_array=true
flink.starrocks.sink.properties.format=jsonシャード化テーブルの統合
水平シャーディング後、大規模なテーブルのデータは複数のテーブルまたはデータベースに分割されることがあります。単一のルールセットを構成することで、複数のソーステーブルを 1 つの StarRocks テーブルに同期できます。
たとえば、edu_db_1 および edu_db_2 の両方に、同一のスキーマを持つ course_1 および course_2 が存在する場合、以下のルールにより、4 つのテーブルすべてを単一の StarRocks テーブルに統合できます。
[table-rule.3]
# pattern to match databases for setting properties
database = ^edu_db_[0-9]*$
# pattern to match tables for setting properties
table = ^course_[0-9]*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030
flink.starrocks.load-url= 192.168.**.**:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=5000starrocks-migrate-tool を実行すると、多対一の同期関係が自動的に作成されます。生成される StarRocks テーブルのデフォルト名は course__auto_shard です。名前を変更する場合は、実行前に生成された SQL ファイルを編集してください。