このトピックでは、Spark を使用する場合の一般的な問題についてまとめています。
Spark Core
Spark SQL
PySpark
Spark Streaming
spark-submit
Spark の履歴ジョブはどこで確認できますか?
EMR コンソールの対象クラスタの [アクセスリンクとポート] タブにある Spark UI リンクをクリックすると、Spark の履歴ジョブの実行情報を確認できます。UI へのアクセスの詳細については、「コンソールからオープンソースコンポーネントの Web インターフェースにアクセスする」をご参照ください。
スタンドアロンモードは Spark ジョブの送信でサポートされていますか?
いいえ。E-MapReduce は、YARN 上の Spark と Kubernetes 上の Spark モードを使用したジョブの送信をサポートしていますが、スタンドアロンモードまたは Mesos モードはサポートしていません。
Spark2 コマンドラインツールのログ出力を削減するにはどうすればよいですか?
EMR DataLake クラスタで Spark2 サービスを選択すると、spark-sql や spark-shell などのコマンドラインツールはデフォルトで INFO レベルでログを出力します。ログ出力を削減する場合は、log4j 構成でログレベルを変更できます。具体的な手順は次のとおりです。
コマンドラインツールが実行されるノード (たとえば、マスターノード) に新しい log4j.properties 構成ファイルを作成します。デフォルトの構成ファイルからコピーすることもできます。コピーコマンドは次のとおりです。
cp /etc/emr/spark-conf/log4j.properties /new/path/to/log4j.properties新しい構成ファイルでログレベルを変更します。
log4j.rootCategory=WARN, consoleSpark サービスの spark-defaults.conf 構成ファイルで、設定項目 spark.driver.extraJavaOptions を変更します。パラメーター値 -Dlog4j.configuration=file:/etc/emr/spark-conf/log4j.properties を -Dlog4j.configuration=file:/new/path/to/log4j.properties に置き換えます。
重要パスにはプレフィックス file: を付ける必要があります。
Spark3 のスモールファイルマージ機能を使用するにはどうすればよいですか?
パラメーター spark.sql.adaptive.merge.output.small.files.enabled を true に設定することで、小さなファイルを自動的にマージできます。マージされたファイルは圧縮されるため、マージされたファイルが小さすぎる場合は、パラメーター spark.sql.adaptive.advisoryOutputFileSizeInBytes の値を適切に増やすことができます。デフォルト値は 256 MB です。
SparkSQL でデータスキューを処理するにはどうすればよいですか?
Spark2 の場合、処理方法は次のとおりです。
テーブルを読み取るときに、null などの無関係なデータをフィルタリングします。
小さなテーブルをブロードキャストします。
select /*+ BROADCAST (table1) */ * from table1 join table2 on table1.id = table2.idスキューキーに基づいてスキューデータを分離します。
select * from table1_1 join table2 on table1_1.id = table2.id union all select /*+ BROADCAST (table1_2) */ * from table1_2 join table2 on table1_2.id = table2.idスキューキーがわかっている場合は、データを分散させます。
select id, value, concat(id, (rand() * 10000) % 3) as new_id from A select id, value, concat(id, suffix) as new_id from ( select id, value, suffix from B Lateral View explode(array(0, 1, 2)) tmp as suffix)スキューキーがわからない場合は、データを分散させます。
select t1.id, t1.id_rand, t2.name from ( select id , case when id = null then concat(‘SkewData_’, cast(rand() as string)) else id end as id_rand from test1 where statis_date = ‘20221130’) t1 left join test2 t2 on t1.id_rand = t2.id
Spark3 の場合、EMR コンソールの Spark3 サービスの [構成] タブで、Spark.sql.adaptive.enabled と spark.sql.adaptive.skewJoin.enabled のパラメーター値を true に変更できます。
PySpark に Python 3 バージョンを指定するにはどうすればよいですか?
以下の内容は、Spark2 をオプションサービスとして、DataLake クラスタの EMR-5.7.0 バージョンを例として、PySpark に Python 3 バージョンを指定する方法を紹介します。
次の 2 つの方法で Python バージョンを変更できます。
一時的な効果の方法
SSH 経由でクラスタにログオンします。詳細については、「クラスタにログオンする」をご参照ください。
次のコマンドを実行して、Python バージョンを変更します。
export PYSPARK_PYTHON=/usr/bin/python3次のコマンドを実行して、Python バージョンを確認します。
pyspark返された情報に次の情報が含まれている場合、Python バージョンが Python 3 に変更されたことを示します。
Using Python version 3.6.8
永続的な効果の方法
SSH 経由でクラスタにログオンします。詳細については、「クラスタにログオンする」をご参照ください。
構成ファイルを変更します。
次のコマンドを実行して、profile ファイルを開きます。
vi /etc/profileiキーを押して、編集モードに入ります。profile ファイルの最後に次の情報を追加して、Python バージョンを変更します。
export PYSPARK_PYTHON=/usr/bin/python3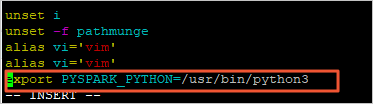
Escキーを押して、編集モードを終了します。:wqと入力して、ファイルを保存して閉じます。
次のコマンドを実行して、変更された構成ファイルを再実行し、すぐに有効にします。
source /etc/profile次のコマンドを実行して、Python バージョンを確認します。
pyspark返された情報に次の情報が含まれている場合、Python バージョンが Python 3 に変更されたことを示します。
Using Python version 3.6.8
Spark Streaming ジョブがしばらく実行された後に予期せず終了するのはなぜですか?
まず、Spark のバージョンが 1.6 より前かどうかを確認します。そうである場合は、Spark のバージョンを更新してください。
Spark 1.6 より前のバージョンにはメモリリークの問題があり、コンテナが中止される可能性があります。
コードがメモリ使用量に関して最適化されているかどうかを確認します。
Spark Streaming ジョブが終了したにもかかわらず、E-MapReduce コンソールにジョブステータスが「実行中」と表示されるのはなぜですか?
ジョブの送信方法が Yarn クライアントモードかどうかを確認します。E-MapReduce には Yarn クライアントモードでの Spark Streaming ジョブのステータスの監視に問題があるため、Yarn クラスタモードに変更してください。
Kerberos 認証が有効になっているクラスタで YARN クラスタモードで spark-submit を実行すると、エラー java.lang.ClassNotFoundException が発生するのはなぜですか?
具体的なエラーメッセージは以下に示されています。
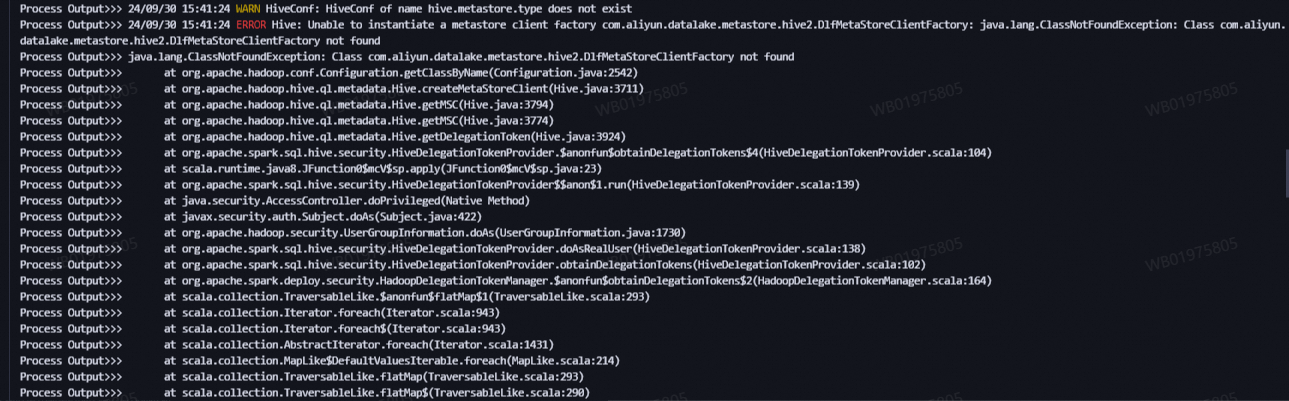
原因分析: EMR クラスタで Kerberos が有効になっていると、YARN クラスタモードのドライバのクラスパスは指定されたディレクトリにある JAR ファイルを自動的に含むように拡張されないため、Spark タスクの実行時にエラーが発生します。
解決策: EMR クラスタで Kerberos が有効になっている場合、YARN クラスタモードで spark-submit を使用してタスクを送信するときは、--jars パラメーターを追加する必要があります。ユーザープログラム自体が依存している JAR パッケージに加えて、/opt/apps/METASTORE/metastore-current/hive2 ディレクトリにあるすべての JAR パッケージを追加する必要もあります。
YARN クラスタモードでは、--jars パラメーターのすべての依存関係はコンマで区切る必要があり、ディレクトリ形式はサポートされていません。
たとえば、アプリケーション JAR パッケージが /opt/apps/SPARK3/spark3-current/examples/jars/spark-examples_2.12-3.5.3-emr.jar の場合、spark-submit コマンドは次のとおりです。
spark-submit --deploy-mode cluster --class org.apache.spark.examples.SparkPi --master yarn \
--jars $(ls /opt/apps/METASTORE/metastore-current/hive2/*.jar | tr '\n' ',') \
/opt/apps/SPARK3/spark3-current/examples/jars/spark-examples_2.12-3.5.3-emr.jar