EMR 上の StarRocks におけるデータインポート方法、パフォーマンスチューニング、エラー解決に関するよくある質問です。
一般的な問題
インポート方法の選択方法
利用可能なすべてのインポート方法の比較については、「概要」をご参照ください。
インポートパフォーマンスに影響を与える要因
主な要因は以下のとおりです。
サーバーメモリ:タブレット数が多いほどメモリを多く消費します。「タブレット数の決定方法」に従って、タブレットサイズを推定してください。
ディスク I/O およびネットワーク帯域幅:適切なネットワーク帯域幅の範囲は 50~100 Mbit/s です。
バッチサイズおよび頻度:
Stream Load の場合、バッチサイズを 10~100 MB に設定します。
Broker Load の場合、バッチサイズの制限はありません。大規模なバッチにはこちらを使用します。
インポート頻度は低く保ちます。シリアル ATA (Serial Advanced Technology Attachment) HDD の場合、1 秒あたり 1 回を超えるインポートジョブを実行しないでください。
「close index channel failed」または「too many tablet versions」
原因:インポート頻度が高すぎてコンパクションが追いつかず、マージされていないデータバージョン数がデフォルトの上限値 1,000 を超えています。
対処方法:以下のいずれか、または両方のアプローチを採用します。
インポート頻度を下げる:単位時間あたりのインポートジョブ数を減らすために、バッチサイズを大きくします。
コンパクションを高速化する:各バックエンド (BE) ノードの be.conf ファイルで以下のパラメーターを設定します。
cumulative_compaction_num_threads_per_disk = 4
base_compaction_num_threads_per_disk = 2
cumulative_compaction_check_interval_seconds = 2「Label Already Exists」
説明:同じラベルを持つインポートジョブがすでに同一データベース内で実行中、または完了しています。
原因:最も一般的な原因は HTTP クライアントのリトライ動作です。Stream Load は HTTP 経由でデータをインポートします。StarRocks が十分に速く結果を返さない場合、一部の HTTP クライアントは自動的に同じリクエストを再試行します。その結果、StarRocks は最初のリクエストがまだ進行中のため、2 回目のリクエストを拒否します。
対処方法:重複ラベルの発生元を調査します。
ラベルでプライマリフロントエンド (FE) ノードのログを検索します。ラベルが 2 回表示される場合は、クライアントが 2 回リクエストを送信しています。
SHOW LOAD WHERE LABEL = "xxx"を実行して、このラベルがすでに FINISHED ジョブによって使用されているかどうかを確認します。
ラベルは特定のインポート方法にスコープされません。異なる方法(例:Stream Load と Broker Load)を使用する 2 つのジョブが、同じラベルで競合する可能性があります。
リトライを防ぐには、データサイズに基づいてインポート所要時間を推定し、HTTP クライアントのタイムアウトをその所要時間より長く設定します。
「ETL_QUALITY_UNSATISFIED; msg:quality not good enough to cancel」
SHOW LOAD を実行し、出力内の URL を見つけて開き、具体的なエラーを確認します。一般的なエラーは以下のとおりです。
| エラー | 意味 |
|---|---|
convert csv string to INT failed | 列の値をターゲットデータの型に変換できません(例:abc を数値列に変換しようとした場合)。 |
the length of input is too long than schema | 文字列が列で定義された長さを超えているか、INT 値が 4 バイトを超えています。 |
actual column number is less than schema column number | デリミタで分割した後、期待される列数よりも少ない列が生成されました。通常はデリミタの不一致が原因です。 |
actual column number is more than schema column number | 分割後に、スキーマで定義された列数よりも多くの列が生成されました。 |
the frac part length longer than schema scale | DECIMAL 列の値の小数部が、定義されたスケールを超えています。 |
the int part length longer than schema precision | DECIMAL 列の値の整数部が、定義された精度を超えています。 |
there is no corresponding partition for this key | パーティションキーの値が、定義されたすべてのパーティション範囲外にあります。 |
データインポート中の RPC タイムアウト
be.conf 内の write_buffer_size パラメーターを確認します。このパラメーターは BE ノードの最大メモリブロックサイズを設定します(デフォルト:100 MB)。値が大きすぎると、リモートプロシージャコール (RPC) タイムアウトが発生する可能性があります。write_buffer_size を tablet_writer_rpc_timeout_sec パラメーターに応じて調整します。詳細については、「パラメーター設定」をご参照ください。
「Value count does not match column count」
原因:インポートコマンドで指定されたデリミタが、ソースデータのデリミタと一致していません。例:
Error: Value count does not match column count. Expect 3, but got 1. Row: 2023-01-01T18:29:00Z,cpu0,80.99この場合、ソースデータはカンマ (,) をデリミタとして使用していますが、インポートコマンドではタブ (\t) が指定されています。そのため、StarRocks はカンマで区切られた 3 つのフィールドすべてを 1 つの列として読み取ります。
対処方法:インポートコマンドのデリミタをソースデータに合わせて変更し、再試行します。
「ERROR 1064 (HY000): Failed to find enough host in all backends. need: 3」
テーブル作成時に、テーブルプロパティに "replication_num" = "1" を追加します。
BE ログ内の「Too many open files」
システムのファイルハンドル上限を増やします。
base_compaction_num_threads_per_diskおよびcumulative_compaction_num_threads_per_disk(デフォルト:それぞれ 1)を減らします。「設定項目の変更」をご参照ください。問題が継続する場合は、クラスターをスケールアウトするか、インポート頻度を下げます。
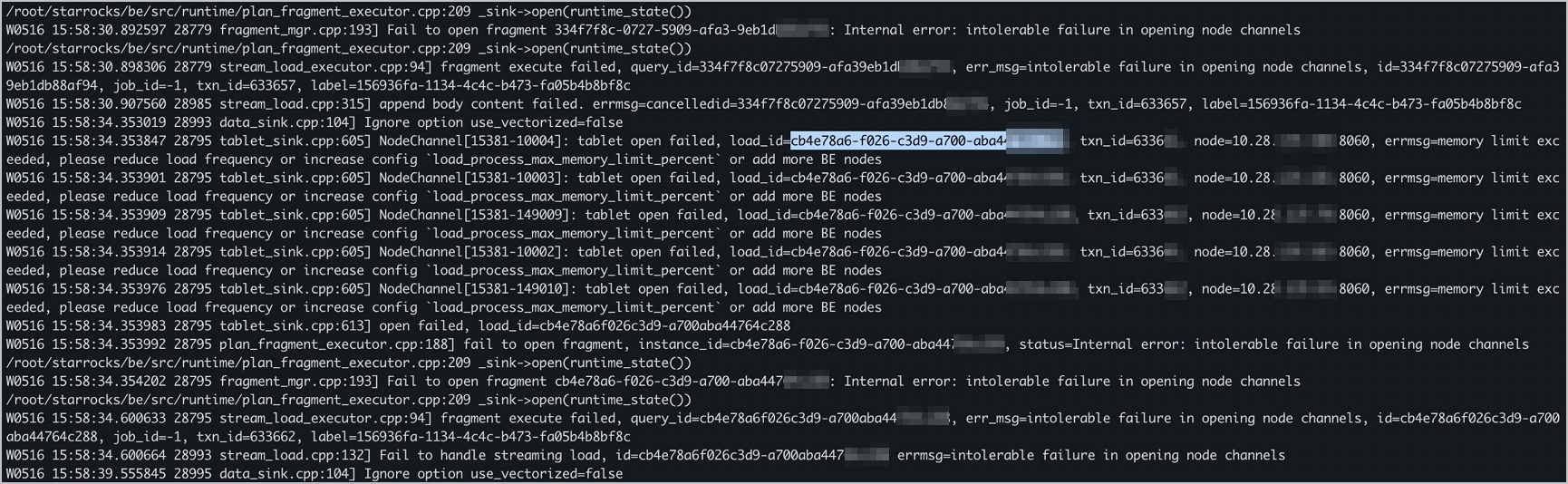
「設定の load_process_max_memory_limit_percent を増加させる」
load_process_max_memory_limit_bytes および load_process_max_memory_limit_percent を確認して増やします。「設定項目の変更」をご参照ください。
Stream Load
Stream Load は先頭行の列名を識別できますか?
いいえ。Stream Load は先頭行を通常のデータとして扱い、列ヘッダーを識別またはスキップすることはできません。
ソースファイルの先頭行に列名がある場合は、以下のいずれかの方法を採用します。
エクスポートツールを修正して、列ヘッダーなしでエクスポートします。
インポート前に先頭行を削除します:
sed -i '1d' filenameStream Load 文に
-H "where: column_name != 'Column Name'"を追加してヘッダー行をフィルターします。StarRocks はヘッダー文字列をターゲットデータの型に変換し、フィルターで除外します。変換に失敗した場合はnullが返されるため、対象列にNOT NULL制約がないことを確認してください。-H "max_filter_ratio:0.01"を追加して1 行のエラーを許容します。これにより、先頭行の失敗がジョブの中止を引き起こさなくなります。応答内のErrorURLには依然としてエラーが記録されますが、インポートは成功します。実際のデータエラーを隠さないように、この値は低く保ってください。
Stream Load 実行時にパーティションキー列のデータ型を変換する必要がありますか?
はい。ただし、StarRocks が変換を処理します。テーブルスキーマでターゲット列の型を定義し、Stream Load 文で列式を使用します。
たとえば、CSV ファイルに 202106.00 形式の値を持つ DATE 列があり、テーブルが DATE 型を期待している場合、次のようにマッピングします。
-H "columns: NO,DATE_1, VERSION, PRICE, DATE=LEFT(DATE_1,6)"DATE_1 は生の値用の一時的なプレースホルダーです。LEFT(DATE_1,6) は先頭 6 文字を抽出し、その結果を DATE に割り当てます。変換関数を呼び出す前に、すべてのソース列を一時的な名前でリストアップします。変換関数はスカラー関数(集計関数およびウィンドウ関数以外)である必要があります。
「body exceed max size: 10737418240, limit: 10737418240」
原因:ソースファイルが Stream Load の 10 GB 制限を超えています。
対処方法:
ファイルをより小さな部分に分割します:
seq -w 0 nまたは、
streaming_load_max_mbを更新して制限を引き上げます。curl -XPOST http://<be_host>:<http_port>/api/update_config?streaming_load_max_mb=<file_size>その他の BE パラメーターについては、「パラメーター設定」をご参照ください。
Routine Load
Routine Load インポートパフォーマンスを向上させる方法
方法 1:タスク並列度を増やす
これにより CPU 使用量が増加し、データバージョン数が多くなる可能性があります。
タスク並列度の上限は次のとおりです。
min(alive_be_number, partition_number, desired_concurrent_number, max_routine_load_task_concurrent_num)| パラメーター | 説明 | デフォルト |
|---|---|---|
alive_be_number | 稼働中の BE ノード数 | — |
partition_number | 消費する Kafka パーティション数 | — |
desired_concurrent_number | Routine Load ジョブごとの期待並列度 | 3 |
max_routine_load_task_concurrent_num | Routine Load ジョブごとの最大並列度(FE 動的パラメーター) | 5 |
alive_be_number および partition_number の両方が desired_concurrent_number および max_routine_load_task_concurrent_num を超える場合、後者の両方を増やすことで並列度を上げます。
例:7 パーティション、5 台の稼働中 BE ノード、max_routine_load_task_concurrent_num = 5 の場合、desired_concurrent_number を 3 から 5 に変更します。有効な並列度:min(5, 7, 5, 5) = 5。
新規ジョブの場合:
CREATE ROUTINE LOAD内でdesired_concurrent_numberを設定します。既存ジョブの場合:
ALTER ROUTINE LOADで更新します。
max_routine_load_task_concurrent_num については、「パラメーター設定」をご参照ください。
方法 2:タスクごとの消費データ量を増やす
これによりインポート遅延が増加します。
各 Routine Load タスクは、max_routine_load_batch_size(バイト)または routine_load_task_consume_second(秒)で設定された制限に達するまでデータを消費します。どの制限が適用されているかを診断するには、be/log/be.INFO を確認します。
I0325 20:27:50.410579 15259 data_consumer_group.cpp:131] consumer group done: 41448fb1a0ca59ad-30e34dabfa7e47a0. consume time(ms)=3261, received rows=179190, received bytes=9855450, eos: 1, left_time: -261, left_bytes: 514432550, blocking get time(us): 3065086, blocking put time(us): 24855left_bytes >= 0の場合:時間制限(routine_load_task_consume_second)が適用されています。routine_load_task_consume_secondを増やします。left_bytes < 0の場合:バイト制限(max_routine_load_batch_size)が適用されています。max_routine_load_batch_sizeを増やします。
詳細については、「パラメーター設定」をご参照ください。
SHOW ROUTINE LOAD 実行後、ジョブステータスが PAUSED または CANCELLED になります。どうすればよいですか?
ステータス:PAUSED — 「Broker: Offset out of range」
原因:コンシューマオフセットが Kafka パーティション内に存在しなくなっています。
対処方法:SHOW ROUTINE LOAD を実行し、Progress フィールドで最新のオフセットを確認します。そのオフセットのメッセージが消失している場合は、以下のいずれかが原因です。
ジョブ作成時に将来のオフセットが設定されました。
Kafka がメッセージを消費前にクリーンアップしました。インポート速度に基づいて
log.retention.hoursおよびlog.retention.bytesを調整します。
ステータス:PAUSED — エラー行数が上限を超えました
原因:エラー行数が max_error_number を超えました。
対処方法:ReasonOfStateChanged および ErrorLogUrls を確認します。
データ形式が修正可能な場合は、修正後に
RESUME ROUTINE LOADを実行します。StarRocks でデータ形式を解析できない場合は、
max_error_numberを増やします。SHOW ROUTINE LOADを実行して現在の値を確認します。ALTER ROUTINE LOADを実行して値を増やします。RESUME ROUTINE LOADを実行します。
ステータス:CANCELLED
原因:回復不能な例外が発生しました(例:ターゲットテーブルが削除されました)。
対処方法:ReasonOfStateChanged および ErrorLogUrls を確認します。CANCELLED ステータスのジョブは再開できません。新しいジョブを作成してください。
Kafka からのインポート時に Routine Load は 1 回限りのセマンティクスを保証できますか?
はい。各インポートタスクは個別のトランザクションとして実行されます。トランザクションが失敗した場合、FE ノードはパーティションのコンシューマオフセットを更新しません。FE ノードがタスクを再スケジュールする際、最後に保存されたオフセットから開始するため、1 回限りの配信が保証されます。
「Broker: Offset out of range」
SHOW ROUTINE LOAD を実行して最新のオフセットを取得し、そのオフセットのメッセージが Kafka に存在することを確認します。一般的な原因は以下のとおりです。
ジョブ作成時に将来のオフセットが指定されました。
Kafka がインポートジョブによる消費前にメッセージを削除しました。インポート速度に合わせて
log.retention.hoursおよびlog.retention.bytesを調整します。
Broker Load
FINISHED ステータスの Broker Load ジョブを再実行できますか?
いいえ。完了したジョブのラベルは再利用できません。これは重複インポートを防止するためです。同じデータを再インポートするには、SHOW LOAD を実行して元のジョブの構成を確認し、新しいラベルで新しいジョブを作成します。
HDFS データをインポート後、日付フィールドが予想より 8 時間遅れます
原因:テーブルまたはインポートジョブが UTC + 08:00 のタイムゾーンで作成されましたが、サーバーは UTC + 0 で動作しています。StarRocks は保存された値に 8 時間を加算します。
対処方法:StarRocks テーブル作成時に timezone パラメーターを削除します。
「ErrorMsg: type:ETL_RUN_FAIL; msg:Cannot cast '\<slot 6\>' from VARCHAR to ARRAY\<VARCHAR(30)\>」
原因:ORC ファイルの列名が StarRocks テーブルの列名と一致していません。名前が異なる場合、StarRocks は SET 文を呼び出し、型推論のために cast() を呼び出しますが、これが失敗することがあります。
対処方法:ORC ファイルの列名がターゲットテーブルの列名と完全に一致するようにします。これにより、StarRocks は SET 文および cast 関数をスキップできます。
Broker Load ジョブ作成時にエラーは発生しませんが、データが表示されません
Broker Load は非同期です。CREATE LOAD 文の成功は、ジョブが送信されたことを意味するだけで、完了したわけではありません。SHOW LOAD を実行してジョブステータスおよびエラーメッセージを確認し、必要に応じてパラメーターを調整して再送信します。
「failed to send batch」または「TabletWriter add batch with unknown id」
原因:データ書き込みタイムアウトが発生しました。
対処方法:query_timeout システム変数および streaming_load_rpc_max_alive_time_sec BE パラメーターを増やします。「パラメーター設定」をご参照ください。
「LOAD-RUN-FAIL; msg:OrcScannerAdapter::init_include_columns. col name = xxx not found」
Parquet または ORC ファイルをインポートする際、ファイルヘッダーの列名が StarRocks テーブルの列名と一致している必要があります。一致しない場合は、SET 句で列マッピングを使用します。
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
)古いバージョンの Hive で生成された (_col0, _col1, _col2, ...) ヘッダーを持つ ORC ファイルの場合は、SET を介して列マッピングを明示的に設定します。
インポートジョブが停止し、完了しません
FE ノードの fe.log でジョブラベルを使用してインポートジョブ ID を検索します。その後、そのジョブ ID を BE ノードの be.INFO ログで検索し、何がブロッキングしているかを特定します。
高可用性 HDFS クラスターへのアクセス方法
自動 NameNode フェールオーバーを有効にするには、以下のパラメーターを設定します。
| パラメーター | 説明 |
|---|---|
dfs.nameservices | HDFS サービス名。カスタム名を設定します(例:my_ha)。 |
dfs.ha.namenodes.xxx | NameNode 名のカンマ区切りリスト。xxx は dfs.nameservices の値に置き換えます。例:my_nn。 |
dfs.namenode.rpc-address.xxx.nn | 各 NameNode の RPC アドレス。nn は NameNode 名に置き換えます。形式:Hostname:Port。 |
dfs.client.failover.proxy.provider | フェールオーバープロキシプロバイダー。デフォルト:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider。 |
シンプル認証を使用した設定例:
(
"username"="user",
"password"="passwd",
"dfs.nameservices" = "my-ha",
"dfs.ha.namenodes.my-ha" = "my_namenode1,my_namenode2",
"dfs.namenode.rpc-address.my-ha.my-namenode1" = "nn1-host:rpc_port",
"dfs.namenode.rpc-address.my-ha.my-namenode2" = "nn2-host:rpc_port",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)これらの設定を hdfs-site.xml に記述することもできます。ブローカープロセスを使用して HDFS にアクセスする場合は、ファイルパスおよび認証情報のみを指定します。
HDFS フェデレーションでの ViewFs の設定方法
ViewFs 構成の core-site.xml および hdfs-site.xml を broker/conf ディレクトリにコピーします。
カスタムファイルシステムが含まれる場合は、関連する .jar ファイルを broker/lib ディレクトリにコピーします。
Kerberos 対応 EMR クラスターにアクセス時に「Can't get Kerberos realm」が発生します
すべてのブローカーマシンに
/etc/krb5.confが存在することを確認します。エラーが継続する場合は、ブローカー起動スクリプトの
JAVA_OPTS変数に-Djava.security.krb5.conf:/etc/krb5.confを追加します。
INSERT INTO
INSERT INTO で 1 行挿入するのに 50~100 ms かかるのはなぜですか?
INSERT INTO はバッチインポート向けに設計されています。1 行挿入にかかる時間はバッチ挿入と同じです。これは、操作が常に完全なトランザクションを開くためです。オンライン分析処理 (OLAP) ワークロードでは、INSERT INTO を使用して個々の行をロードしないでください。
INSERT INTO SELECT 実行時に「index channel has intolerable failure」が発生します
原因:Stream Load RPC タイムアウト。
対処方法:be.conf 内の以下のパラメーターを更新し、クラスターを再起動します。
| パラメーター | 説明 | デフォルト |
|---|---|---|
streaming_load_rpc_max_alive_time_sec | Stream Load の RPC タイムアウト | 1200 秒 |
tablet_writer_rpc_timeout_sec | TabletWriter のタイムアウト | 600 秒 |
大規模データセットに対して INSERT INTO SELECT を実行すると「execute timeout」が発生します
原因:クエリがセッションタイムアウトを超えました。
対処方法:セッションの query_timeout を増やします(デフォルト:600 秒)。
SET query_timeout = <value>;MySQL から StarRocks へのリアルタイム同期
Flink ジョブ実行時に「Could not execute SQL statement. Reason: ValidationException: One or more required options are missing」が発生します
原因:StarRocks-migrate-tools (SMT) の config_prod.conf ファイルに複数のルール(例:[table-rule.1] および [table-rule.2])が定義されていますが、1 つ以上のルールで必須フィールドが不足しています。
対処方法:各ルールにデータベース、テーブル、Flink コネクタが設定されていることを確認します。
Flink は失敗したタスクをどのように再起動しますか?
Flink はチェックポイント機構と再起動ポリシーを組み合わせて使用します。固定遅延再起動ポリシーでチェックポイントを有効にするには、flink-conf.yaml に以下を追加します。
# ミリ秒単位のチェックポイント間隔
execution.checkpointing.interval: 300000
state.backend: filesystem
state.checkpoints.dir: file:///tmp/flink-checkpoints-directory| パラメーター | 説明 |
|---|---|
execution.checkpointing.interval | ミリ秒単位のチェックポイント間隔。チェックポイントを有効にするには 0 より大きい値を設定する必要があります。 |
state.backend | 状態を永続化する場所。「State backends」をご参照ください。 |
state.checkpoints.dir | チェックポイントを格納するディレクトリ。 |
Flink ジョブを停止して以前の状態に復元する方法
セーブポイントを使用します。セーブポイントは、ストリーミングジョブの実行状態の一貫性のあるスナップショットで、手動でトリガーされます。「Savepoints」をご参照ください。
ジョブを停止してセーブポイントを書き込みます。
bin/flink stop --type [native/canonical] --savepointPath [:targetDirectory] :jobId| パラメーター | 説明 |
|---|---|
jobId | Flink ジョブ ID。flink list -running または Flink Web UI から取得します。 |
targetDirectory | セーブポイントのディレクトリ。flink-conf.yml 内で state.savepoints.dir を設定してデフォルトを構成できます:state.savepoints.dir: [file:// or hdfs://]/home/user/savepoints_dir |
ジョブを復元するには、再送信時にセーブポイントを指定します。
./flink run -c com.starrocks.connector.flink.tools.ExecuteSQL -s savepoints_dir/savepoints-xxxxxxxx flink-connector-starrocks-xxxx.jar -f flink-create.all.sqlFlink コネクタ
1 回限りのセマンティクスを使用したインポートが失敗します
次のようなエラーが表示される場合:
{
"Status": "Fail",
"Message": "timeout by txn manager",
"WriteDataTimeMs": 120278,
...
}原因:sink.properties.timeout の値が Flink チェックポイント間隔より短くなっています。
対処方法:sink.properties.timeout をチェックポイント間隔を超えるように増やします。
flink-connector-jdbc_2.11 を使用後、StarRocks のタイムスタンプが Flink より 8 時間早くなります
Flink シンクテーブルで server-time-zone を Asia/Shanghai に設定し、url パラメーターに &serverTimezone=Asia/Shanghai を追加します。
CREATE TABLE sk (
sid int,
local_dtm TIMESTAMP,
curr_dtm TIMESTAMP
)
WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.**.**:9030/sys_device?characterEncoding=utf-8&serverTimezone=Asia/Shanghai',
'table-name' = 'sink',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'sr',
'password' = 'sr123',
'server-time-zone' = 'Asia/Shanghai'
);StarRocks クラスター上の Kafka からのインポートは成功しますが、他のマシン上の Kafka では失敗します
次のような表示が見られる場合:
failed to query wartermark offset, err: Local: Bad message format原因:StarRocks が Kafka ホスト名を解決できません。
対処方法:すべての StarRocks クラスターノードの /etc/hosts に Kafka ホスト名を追加します。
BE ノードのメモリが完全に使用され、CPU が 100% ですが、クエリは実行されていません
BE ノードは定期的に統計情報を収集し、構成に基づいてメモリを管理します。デフォルトでは、StarRocks は使用メモリが tc_use_memory_min(デフォルト:10737418240 バイト、約 10 GiB)を超えた場合にのみ、オペレーティングシステム (OS) にメモリを返却します。
このしきい値を変更するには、BE 構成で tc_use_memory_min を更新します。EMR コンソールで、StarRocks サービスページの 構成 タブを開き、be.conf タブを選択します。「パラメーター設定」をご参照ください。
BE ノードが OS にメモリを返却するのが遅れるのはなぜですか?
メモリ割り当ては高コストな操作です。StarRocks が OS から大量のメモリを要求する際、将来の使用のために余剰容量を確保します。アイドル状態のメモリは、即座ではなく徐々に OS に返却されます。この動作を検証するには、テスト環境で長時間にわたりメモリ使用量を監視し、最終的にメモリが解放されることを確認してください。
システムが Flink コネクタの依存関係を解析できません
原因:/etc/maven/settings.xml ファイルが Alibaba Cloud イメージリポジトリを使用するように構成されておらず、一部の依存関係が解決できません。
対処方法:/etc/maven/settings.xml 内で Alibaba Cloud パブリックリポジトリアドレスを https://maven.aliyun.com/repository/public に設定します。
チェックポイント間隔が設定されている場合でも sink.buffer-flush.interval-ms は有効ですか?
はい。フラッシュ操作はチェックポイント間隔によって制限されません。以下のいずれかのしきい値に達すると、フラッシュがトリガーされます。
sink.buffer-flush.max-rows
sink.buffer-flush.max-bytes
sink.buffer-flush.interval-msチェックポイント間隔 は 1 回限りのセマンティクスを制御します。sink.buffer-flush.interval-ms パラメーターは少なくとも 1 回のフラッシュ動作を制御します。両者は独立して動作します。
DataX
DataX でインポートしたデータを更新できますか?
はい。最新バージョンの StarRocks では、プライマリキーモデルで作成されたテーブルのデータを DataX を使用して更新できます。JSON 構成ファイルの reader セクションに _op フィールドを追加します。
DataX キーワードによるインポートエラーを回避する方法
キーワードをバックティック (` ``) で囲みます。
Spark Load
「マスターモードが 'yarn' の場合、環境変数 HADOOP-CONF-DIR または YARN-CONF-DIR のいずれかを設定する必要があります」
Spark クライアントの spark-env.sh スクリプトで HADOOP-CONF-DIR 環境変数を設定します。
「Cannot run program 'xxx/bin/spark-submit': error=2, No such file or directory」
原因:spark_home_default_dir パラメーターが欠落しているか、誤ったディレクトリを指しています。
対処方法:正しい Spark クライアントのルートディレクトリに設定します。
「File xxx/jars/spark-2x.zip does not exist」
原因:spark-resource-path パラメーターがパッケージ化された ZIP ファイルを指していません。
対処方法:パスが実際のファイル名と一致していることを確認します。
「yarn client does not exist in path: xxx/yarn-client/hadoop/bin/yarn」
原因:yarn-client-path に実行可能ファイルが設定されていません。
対処方法:正しい YARN クライアントバイナリパスに設定します。