本トピックでは、Dataflow クラスターに関するよくある質問とその回答をまとめています。
クラスターの操作および運用・保守
ジョブに関する問題
エラー
NoSuchFieldError / NoSuchMethodError / ClassNotFoundException(JAR 衝突)
UnsupportedOperationException: Hadoop 上の回復可能ライターは HDFS のみをサポートしています
java.util.concurrent.TimeoutException: TaskManager のハートビートがタイムアウトしました
外部クライアントから Flink ジョブを送信するにはどうすればよいですか? {#submit-from-external-client}
外部クライアントが Dataflow クラスターのネットワークに到達できることを確認します。
クライアント側で Hadoop YARN 環境を設定します。Dataflow クラスターから以下のディレクトリをクライアントにコピーし、クライアント側で環境変数を設定します。
/opt/apps/YARN/yarn-current— Hadoop YARN のインストールディレクトリ/etc/taihao-apps/hadoop-conf/— Hadoop 構成ファイル
重要yarn-site.xmlなどの Hadoop 構成ファイルでは、サービスアドレスとして完全修飾ドメイン名 (FQDN) が使用されます(例:master-1-1.c-xxxxxxxxxx.cn-hangzhou.emr.aliyuncs.com)。これらの FQDN がクライアントから解決可能であることを確認するか、IP アドレスに置き換えます。詳細については、「外部クライアントからホスト名を解決するにはどうすればよいですか?」をご参照ください。export HADOOP_HOME=/path/to/yarn-current && \ export PATH=${HADOOP_HOME}/bin/:$PATH && \ export HADOOP_CLASSPATH=$(hadoop classpath) && \ export HADOOP_CONF_DIR=/path/to/hadoop-confFlink ジョブを送信します。例:
flink run -d -t yarn-per-job -ynm flink-test $FLINK_HOME/examples/streaming/TopSpeedWindowing.jar送信後、Dataflow クラスターの YARN Web UI でジョブを確認できます。
外部クライアントからホスト名を解決するにはどうすればよいですか? {#resolve-hostnames}
以下のいずれかの方法を使用します。
/etc/hosts の編集:クラスターのホスト名とその IP アドレスのマッピングを追加します。
[Alibaba Cloud DNS PrivateZone](https://www.alibabacloud.com/help/ja/document_detail/64611.html#topic-2036614) の使用:クラスターのドメインに対して非公開 DNS 解決を構成します。
カスタム DNS サービスの使用:Flink 構成に次の JVM パラメーターを追加します。
env.java.opts.client: "-Dsun.net.spi.nameservice.nameservers=xxx -Dsun.net.spi.nameservice.provider.1=dns,sun -Dsun.net.spi.nameservice.domain=yyy"
Flink ジョブのステータスを確認するにはどうすればよいですか? {#view-job-status}
以下の 3 つの方法があります。
EMR コンソール:E-MapReduce (EMR) は Apache Knox をサポートしており、インターネット経由で YARN および Flink Web UI にアクセスできます。YARN Web UI から Apache Flink ダッシュボードに移動します。詳細については、「Web UI を使用して Flink (VVR) のジョブステータスを確認する」をご参照ください。
SSH トンネル:詳細については、「オープンソースコンポーネントの Web UI にアクセスするための SSH トンネルを作成する」をご参照ください。
YARN RESTful API:
セキュリティグループでポート 8443 および 8088 を開放するか、クライアントと Dataflow クラスターを同一の仮想プライベートクラウド (VPC) 内に配置する必要があります。
curl --compressed -v -H "Accept: application/json" -X GET \ "http://master-1-1:8088/ws/v1/cluster/apps?states=RUNNING&queue=default&user.name=***"
Flink ジョブのログを表示するにはどうすればよいですか? {#view-job-logs}
実行中のジョブ:ジョブの Web UI でログを表示します。
完了済みのジョブ:Flink HistoryServer で統計情報を確認するか、以下のコマンドを実行します。
yarn logs -applicationId application_xxxx_yyyyデフォルトでは、完了済みのジョブのログは、Hadoop 分散ファイルシステム (HDFS) 上の
hdfs:///tmp/logs/$USERNAME/logs/に保存されます。
Flink HistoryServer にアクセスするにはどうすればよいですか? {#access-historyserver}
Flink HistoryServer は、master-1-1 ノード(マスターサーバーグループ内の最初のノード)のポート 18082 で実行されます。完了済みの Flink ジョブの統計情報を収集しますが、ジョブログは保存しません。
アクセス手順は以下のとおりです。
master-1-1ノードのセキュリティグループルールでポート 18082 を開放します。http://<master-1-1-ip>:18082にアクセスします。
完了済みのジョブのログを表示するには、代わりに YARN API を呼び出すか、YARN Web UI を使用してください。
商用コネクタを使用するにはどうすればよいですか? {#use-commercial-connectors}
この機能は Dataflow クラスターでのみ利用可能です。利用可能なコネクタには、Hologres、Log Service、MaxCompute、DataHub、Elasticsearch、ClickHouse があります。以下に Hologres コネクタの使用例を示します。
ステップ 1:ローカルマシンへのコネクタのインストール
コネクタの JAR パッケージは、Dataflow クラスター上の /opt/apps/FLINK/flink-current/opt/connectors/ に格納されています。JAR をローカルの Maven リポジトリにインストールします。
mvn install:install-file \
-Dfile=/path/to/ververica-connector-hologres-1.13-vvr-4.0.7.jar \
-DgroupId=com.alibaba.ververica \
-DartifactId=ververica-connector-hologres \
-Dversion=1.13-vvr-4.0.7 \
-Dpackaging=jarpom.xml に依存関係を追加し、scope を provided に設定します。
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>ververica-connector-hologres</artifactId>
<version>1.13-vvr-4.0.7</version>
<scope>provided</scope>
</dependency>ステップ 2:ランタイムでコネクタを有効化する
以下のいずれかの方法を選択します。
方法 1 — HDFS を使用:コネクタ JAR を HDFS にコピーし、送信時に参照します。
hdfs mkdir hdfs:///flink-current/opt/connectors/hologres/ hdfs cp hdfs:///flink-current/opt/connectors/ververica-connector-hologres-1.13-vvr-4.0.7.jar \ hdfs:///flink-current/opt/connectors/hologres/ververica-connector-hologres-1.13-vvr-4.0.7.jar送信コマンドに以下のパラメーターを追加します。
-D yarn.provided.lib.dirs=hdfs:///flink-current/opt/connectors/hologres/方法 2 — ローカルクライアントを使用:JAR を、クラスター内と同じパスにクライアントにコピーします。
/opt/apps/FLINK/flink-current/opt/connectors/ververica-connector-hologres-1.13-vvr-4.0.7.jar送信コマンドに以下のパラメーターを追加します。
-C file:///opt/apps/FLINK/flink-current/opt/connectors/ververica-connector-hologres-1.13-vvr-4.0.7.jar方法 3 — ジョブ JAR へのバンドル:コネクタ JAR をジョブ JAR に直接パッケージ化します。
GeminiStateBackend を使用するにはどうすればよいですか? {#use-gemini-state-backend}
GeminiStateBackend は Dataflow クラスターでのみ利用可能です。これはエンタープライズ版の状態バックエンドであり、オープンソースの状態バックエンドと比較して 3~5 倍のパフォーマンスを発揮します。Dataflow クラスターの構成ファイルではデフォルトで有効化されています。
高度な構成オプションについては、「GeminiStateBackend の構成」をご参照ください。
オープンソースの状態バックエンドに切り替えるにはどうすればよいですか? {#use-open-source-state-backend}
Dataflow クラスターでは、デフォルトで GeminiStateBackend が使用されます。特定のジョブについて RocksDB などのオープンソースの状態バックエンドに切り替えるには、送信時に -D パラメーターを指定します。
flink run-application -t yarn-application \
-D state.backend=rocksdb \
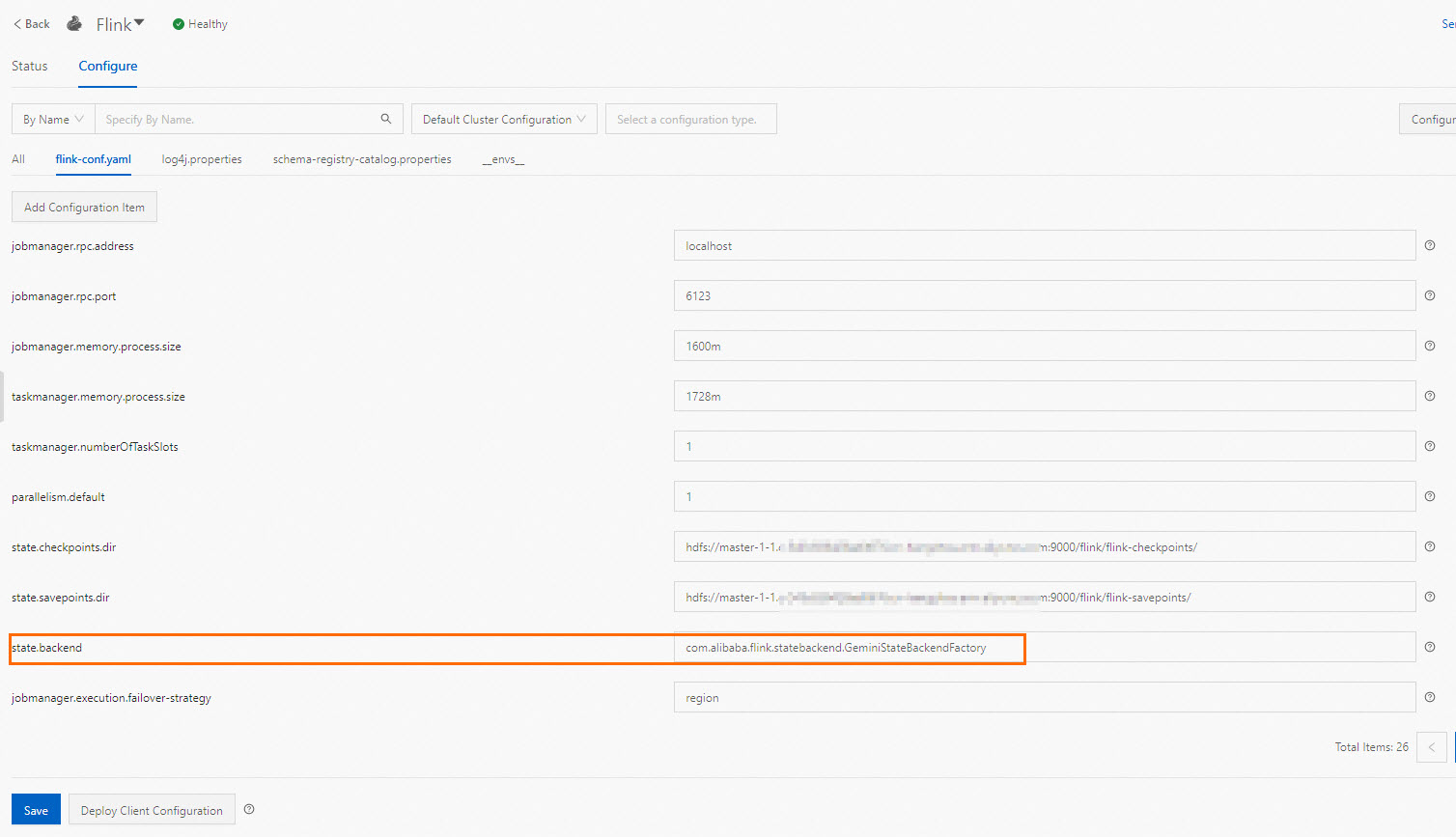
/opt/apps/FLINK/flink-current/examples/streaming/TopSpeedWindowing.jar以降のすべてのジョブにこの変更を適用するには、EMR コンソールで state.backend パラメーターを更新します。Flink サービスページの 構成 タブに移動し、flink-conf.yaml をクリックして値を設定し、保存 をクリックした後、クライアント構成のデプロイ をクリックします。
JobManager の高可用性 (HA) を有効化するにはどうすればよいですか? {#enable-jobmanager-ha}
Dataflow クラスターでは、Flink が YARN 上で実行されます。ZooKeeper を使用した高可用性 (HA) 構成を設定することで、JobManager の高可用性を有効化できます。詳細については、「Apache Flink の高可用性構成」をご参照ください。
flink-conf.yaml に以下の設定を追加します。
high-availability: zookeeper
high-availability.zookeeper.quorum: 192.168.**.**:2181,192.168.**.**:2181,192.168.**.**:2181
high-availability.zookeeper.path.root: /flink
high-availability.storageDir: hdfs:///flink/recoveryデフォルトでは、高可用性 (HA) を有効化した後、JobManager は障害発生時に 1 回のみ再起動されます。より多くの再起動を許可するには、YARN の yarn.resourcemanager.am.max-attempts パラメーターと、Flink の yarn.application-attempts パラメーターを設定します。
JobManager の過剰な再起動を防ぐために、yarn.application-attempt-failures-validity-interval をデフォルトの 10000(10 秒)から 300000(5 分)に増加させます。
Flink ジョブのメトリクスを確認するにはどうすればよいですか? {#view-job-metrics}
EMR コンソールにログインし、クラスターの 監視 タブに移動して、メトリクス監視 をクリックします。
FLINK を ダッシュボード のドロップダウンリストから選択します。
アプリケーション ID およびジョブ ID を選択して、該当ジョブのメトリクスを確認します。
アプリケーション ID およびジョブ ID は、Flink ジョブが実行中の場合にのみ表示されます。
ソースとシンクの両方が構成されていないとデータを報告しないメトリクス(例:sourceIdleTime)もあります。上流および下流のストレージに関する問題をトラブルシューティングするにはどうすればよいですか? {#troubleshoot-storage}
「上流および下流のストレージ」をご参照ください。
クライアントログはどこに保存されていますか? {#client-logs}
FLINK_LOG_DIR 環境変数でクライアントログのディレクトリを指定します。デフォルトは /var/log/taihao-apps/flink です。EMR バージョン V3.43.0 より前の場合は、デフォルトが /mnt/disk1/log/flink になります。
flink run パラメーターが反映されないのはなぜですか? {#parameters-not-taking-effect}
ジョブパラメーターは、コマンド内で JAR ファイルパスの後に配置する必要があります。例:
flink run -d -t yarn-per-job test.jar arg1 arg2JAR の前に配置されたパラメーターは、ジョブ引数ではなく Flink フレームワークのオプションとして処理されます。
クラスターログはどこに保存されていますか? {#cluster-logs}
ログへのアクセス方法は、JobManager の実行状態によって異なります。
JobManager が停止している場合:以下のコマンドでログを取得します。
yarn logs -applicationId application_xxxx_yyまたは、YARN Web UI で完了済みのジョブのログリンクにアクセスします。
JobManager は実行中です:
Flink ジョブの Web UI でログを表示します。
JobManager のログを取得します:
bash yarn logs -applicationId application_xxxx_yy -am ALL -logFiles jobmanager.logTaskManager のログを取得します:
bash yarn logs -applicationId application_xxxx_yy -containerId container_xxxx_yy_aa_bb -logFiles taskmanager.log
NoSuchFieldError / NoSuchMethodError / ClassNotFoundException(JAR 衝突) {#jar-conflict}
これらのエラーは、ジョブの依存関係とクラスター上の Flink インストールとの間で JAR 衝突が発生していることを示します。解決手順は以下のとおりです。
競合するクラスの特定:エラーログからクラス名を確認し、
pom.xmlを含むディレクトリで以下のコマンドを実行して依存関係ツリーを確認します。mvn dependency:tree競合の解決:以下のいずれかの方法を使用します。
範囲を競合する依存関係のprovidedに変更し、pom.xmlで指定します。依存関係から特定のクラスを除外します。
Maven Shade Plugin を使用してクラスを再配置(シャード)します。
クラスがどの JAR から読み込まれているかの確認:
flink-conf.yamlに以下の JVM パラメーターを追加するか、動的に渡します。# flink-conf.yaml env.java.opts: -verbose:classまたは、動的に渡す場合:
-Denv.java.opts="-verbose:class"クラスの読み込み情報は
jobmanager.outまたはtaskmanager.outに記録されます。
クラスパスに識別子に対する複数のファクトリが見つかりました {#multiple-factories-error}
このエラーは、同じコネクタの複数の実装がクラスパス上に存在することを意味します。通常、ジョブの JAR でコネクタ依存関係が宣言されており、かつコネクタ JAR が手動で $FLINK_HOME/lib に配置されている場合に発生します。
重複する JAR を削除してください。「NoSuchFieldError / NoSuchMethodError / ClassNotFoundException(JAR 衝突)」を参照して、クラスパスの競合を特定および解決してください。
UnsupportedOperationException: Hadoop 上の回復可能ライターは HDFS のみをサポートしています {#oss-error-1}
Dataflow クラスターでは、Object Storage Service (OSS) へのパスワードなしのアクセスを実現するために組み込みの JindoSDK を使用しており、すでに StreamingFileSink などの API をサポートしています。JindoSDK の上にコミュニティの OSS プラグインを追加すると、依存関係の競合が発生します。
oss-fs-hadoop ディレクトリが $FLINK_HOME/plugins に存在するかどうかを確認します。存在する場合は削除し、ジョブを再送信します。
スキーム 'oss' のファイルシステム実装が見つかりません {#section_1b6bc757}
このエラーは、EMR バージョン V3.40 以前を実行するクラスターで発生し、master-1-1 以外のノードで Jindo 関連の JAR パッケージが欠落している可能性があります。
EMR バージョン V3.40.0 およびそれ以前
ジョブ送信に使用するノードの jindo-flink-4.0.0-full.jar(または類似のファイル)が $FLINK_HOME/lib に存在するかどうかを確認します。存在しない場合は、以下のコマンドでコピーします。
cp /opt/apps/extra-jars/flink/jindo-flink-*-full.jar $FLINK_HOME/libその後、ジョブを再送信します。
EMR バージョン V3.40.0 より後の場合
| デプロイメントモード | 必要な操作 |
|---|---|
| YARN 上の Flink | 不要です。Jindo JAR が $FLINK_HOME/lib になくても、OSS へのアクセスは自動的に処理されます。 |
| その他のモード | $FLINK_HOME/lib に Jindo JAR が存在するかどうかを確認します。存在しない場合は、上記のコピーコマンドを実行してジョブを再送信します。 |
java.util.concurrent.TimeoutException: TaskManager のハートビートがタイムアウトしました {#taskmanager-heartbeat-timeout}
直接的な原因は TaskManager のハートビートタイムアウトです。根本的なエラーを確認するために TaskManager のログを確認してください。一般的な原因としては、ヒープメモリが不足していることや、ジョブコード内のメモリリークによるメモリ不足 (OOM) があります。
OOM が原因の場合、TaskManager のメモリ割り当てを増やすか、ジョブのメモリ使用量を分析します。「java.lang.OutOfMemoryError: GC オーバーヘッド制限を超えました」を参照して、ヒープダンプの生成および分析手順を実施してください。
java.lang.OutOfMemoryError: GC オーバーヘッド制限を超えました {#gc-overhead-limit}
ガーベジコレクション (GC) がタイムアウトしているのは、ジョブに十分なメモリが確保されていないためです。最も一般的な原因は、ユーザー定義関数 (UDF) におけるメモリリーク、またはワークロードに応じた不十分なメモリ割り当てです。
診断のために、エラー発生時にヒープダンプを生成します。再送信時に以下の JVM パラメーターを指定します。
-D env.java.opts="-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/dump.hprof"または、flink-conf.yaml に以下を追加します。
env.java.opts: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/dump.hprofエラーを再現した後、HeapDumpPath で指定されたパスにあるヒープダンプを Memory Analyzer Tool (MAT) または Java VisualVM を使用して分析します。
java.lang.NoSuchFieldError: DEPLOYMENT_MODE {#deployment-mode-error}
ジョブ JAR に含まれる flink-core の依存関係のバージョンが、クラスター上の Flink バージョンと互換性がないためです。
flink-core を pom.xml に、scope を provided として追加します。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<!-- クラスターで使用される Flink バージョンに置き換えてください -->
<version>1.16.1</version>
<scope>provided</scope>
</dependency>互換性のない依存関係が導入される背景については、「NoSuchFieldError / NoSuchMethodError / ClassNotFoundException(JAR 衝突)」をご参照ください。
オペレーターが 1 つしか表示されず、「受信したレコード数」が 0 になるのはなぜですか? {#single-operator-zero-records}
これは予期される動作です。「受信したレコード数」メトリクスは、異なるオペレーター間で交換されるデータをカウントします。Flink がジョブを単一のオペレーター(すべてのオペレーターをチェーン化)に最適化した場合、オペレーター間のデータ交換は発生しないため、この値は常に 0 になります。
フレームグラフを有効化するにはどうすればよいですか? {#enable-flame-graph}
フレームグラフは、各メソッドごとの CPU 使用率を可視化し、パフォーマンスボトルネックを特定するのに役立ちます。この機能は Flink 1.13 以降で利用可能ですが、本番ジョブへの影響を避けるためデフォルトでは無効化されています。
有効化するには、EMR コンソールの Flink サービスページで 構成 タブに移動し、flink-conf.yaml をクリックして以下の設定を追加します。
rest.flamegraph.enabled: true構成項目の追加方法については、「構成項目の管理」をご参照ください。フレームグラフの詳細については、「Apache Flink のフレームグラフ」をご参照ください。