このトピックでは、増分データのリアルタイムコンピューティングを実装するために、StarRocks ベースのデータウェアハウスを構築する方法について説明します。
前提条件
Flink サービスと Kafka サービスを含む Dataflow クラスタまたはカスタムクラスタが作成されていること。詳細については、「クラスタの作成」をご参照ください。
StarRocks クラスタが作成されていること。詳細については、「StarRocks クラスタの作成」をご参照ください。
ApsaraDB for RDS for MySQL インスタンスが作成されます。詳細については、「ApsaraDB for RDS for MySQL インスタンスの作成」をご参照ください。
説明この例では、Dataflow クラスタは EMR V3.40.0、StarRocks クラスタは EMR V5.6.0、ApsaraDB RDS for MySQL インスタンスの MySQL バージョンは 5.7 です。
制限事項
Dataflow クラスタ、StarRocks クラスタ、および ApsaraDB RDS for MySQL インスタンスは、同じ仮想プライベートクラウド (VPC) 内の同じゾーンにデプロイする必要があります。
Dataflow クラスタと StarRocks クラスタは、インターネット経由でアクセスできる必要があります。
ApsaraDB RDS for MySQL インスタンスの MySQL バージョンは 5.7 以降である必要があります。
概要
レイテンシの影響を受けやすいビジネスシナリオでは、データは生成された直後に処理する必要があります。増分データのリアルタイムコンピューティングは、レイテンシを削減するのに役立ちます。 Flink を使用して、データウェアハウス詳細 (DWD) 層やデータウェアハウスサマリー (DWS) 層などの層からデータを事前に集計し、集計結果を永続化してさらに使用することができます。
アーキテクチャ
次の図は、このソリューションのアーキテクチャを示しています。
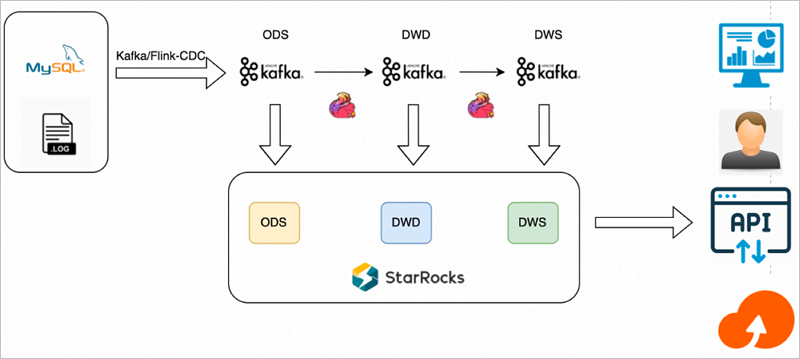
このソリューションは、次の手順で構成されています。
Flink を使用してリアルタイムデータウェアハウスを構築し、データをクレンジング、処理、変換、集計してから、集計結果を Kafka トピックに書き込みます。
StarRocks クラスタを使用して、Kafka トピックからデータの層をサブスクライブし、後続のクエリと分析のためにデータを永続化します。
機能
このソリューションは、次の機能を提供します。
増分データは、Flink によってクレンジング、処理、変換、集計され、サブスクリプションを通じて StarRocks クラスタに永続化されます。
集計結果は、二重書き込みまたは単一書き込みが可能です。二重書き込みモードを選択した場合、各層の結果は次の層の Kafka トピックに書き込まれ、同じ層の StarRocks クラスタにシンクされます。単一書き込みモードを選択した場合、結果は Kafka トピックのみに書き込まれ、StarRocks クラスタは Kafka トピックからデータの層をサブスクライブすることで結果をリアルタイムで永続化します。単一書き込みモードでは、データの状態をクエリし、必要に応じてデータを更新できます。
StarRocks クラスタは、上位層アプリケーションがリアルタイムクエリを実行するためのテーブルを提供します。
利点
データコンピューティングはリアルタイムで実行されます。これは、レイテンシの影響を受けやすいビジネスシナリオの要件を満たします。
メトリックは簡単に変更できます。従来の増分データコンピューティングソリューションとは異なり、このソリューションは中間状態を StarRocks クラスタに永続化します。これは、後続の分析操作の柔軟性を向上させるのに役立ちます。中間データの品質がビジネス要件を満たしていない場合は、テーブルを変更してデータを更新できます。
欠点
増分データのリアルタイムコンピューティングを実装するには、Flink で必要なスキルを習得する必要があります。
このソリューションは、データが頻繁に更新され、計算で累積できないシナリオには適していません。
このソリューションは、マルチストリーム JOIN などのリソースを消費する複雑な操作が実行されるシナリオには適していません。
シナリオ
このソリューションは、少量のデータに対してリアルタイムで単純な計算操作を実行する場合に適しています。最も一般的なシナリオは、イベントトラッキングデータの処理です。
手順
手順 1: ソース MySQL テーブルを作成する
テストデータベースとテストアカウントを作成します。詳細については、「アカウントとデータベースの作成」をご参照ください。
テストデータベースとテストアカウントを作成した後、アカウントに読み取りおよび書き込み権限を付与します。
説明この例では、flink_cdc という名前のデータベースと emr_test という名前のアカウントが作成されます。
テストアカウントを使用して、ApsaraDB RDS for MySQL インスタンスにログオンします。詳細については、「DMS を使用して ApsaraDB RDS for MySQL インスタンスにログオンする」をご参照ください。
次のステートメントを実行して、orders テーブルと customers テーブルを作成します。
orders という名前のテーブルを作成します。
CREATE TABLE flink_cdc.orders ( order_id INT NOT NULL AUTO_INCREMENT, order_revenue FLOAT NOT NULL, order_region VARCHAR(40) NOT NULL, customer_id INT NOT NULL, PRIMARY KEY ( order_id ) );customers という名前のテーブルを作成します。
CREATE TABLE flink_cdc.customers ( customer_id INT NOT NULL, customer_age INT NOT NULL, customer_name VARCHAR(40) NOT NULL, PRIMARY KEY ( customer_id ) );
手順 2: Kafka トピックを作成する
SSH モードで Dataflow クラスタにログオンします。詳細については、「クラスタへのログオン」をご参照ください。
Kafka の [/bin] ディレクトリに移動するには、次のコマンドを実行します。
cd /opt/apps/FLINK/flink-current/binKafka トピックを作成するには、次のコマンドを実行します。
kafka-topics.sh --create --topic ods_order --replication-factor 1 --partitions 1 --bootstrap-server core-1-1:9092 kafka-topics.sh --create --topic ods_customers --replication-factor 1 --partitions 1 --bootstrap-server core-1-1:9092 kafka-topics.sh --create --topic dwd_order_customer_valid --replication-factor 1 --partitions 1 --bootstrap-server core-1-1:9092 kafka-topics.sh --create --topic dws_agg_by_region --replication-factor 1 --partitions 1 --bootstrap-server core-1-1:9092
手順 3: StarRocks クラスタにテーブルとデータインポートジョブを作成する
SSH モードで StarRocks クラスタにログオンします。詳細については、「クラスタへのログオン」をご参照ください。
次のコマンドを実行して、StarRocks クラスターに接続します。
mysql -h127.0.0.1 -P 9030 -urootデータベースを作成するには、次のステートメントを実行します。
CREATE DATABASE IF NOT EXISTS `flink_cdc`;customers テーブルと orders テーブルを作成するには、次のステートメントを実行します。
customers という名前のテーブルを作成します。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`customers` ( `customer_id` INT NOT NULL COMMENT "", `customer_age` FLOAT NOT NULL COMMENT "", `customer_name` STRING NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`customer_id`) COMMENT "" DISTRIBUTED BY HASH(`customer_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" );orders という名前のテーブルを作成します。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`orders` ( `order_id` INT NOT NULL COMMENT "", `order_revenue` FLOAT NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`order_id`) COMMENT "" DISTRIBUTED BY HASH(`order_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" );
次のステートメントを実行して、DWD レイヤーにテーブルを作成します。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`dwd_order_customer_valid`( `order_id` INT NOT NULL COMMENT "", `order_revenue` FLOAT NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "", `customer_age` FLOAT NOT NULL COMMENT "", `customer_name` STRING NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`order_id`) COMMENT "" DISTRIBUTED BY HASH(`order_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" );次のステートメントを実行して、DWS レイヤーにテーブルを作成します。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`dws_agg_by_region` ( `order_region` STRING NOT NULL COMMENT "", `order_cnt` INT NOT NULL COMMENT "", `order_total_revenue` INT NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`order_region`) COMMENT "" DISTRIBUTED BY HASH(`order_region`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" );次のステートメントを実行して、ルーチンロードモードでデータインポートジョブを作成し、Kafka トピックのデータをサブスクライブします。
CREATE ROUTINE LOAD flink_cdc.routine_load_orders ON orders COLUMNS (order_id, order_revenue, order_region, customer_id) PROPERTIES ( "format" = "json", "jsonpaths" = "[\"$.order_id\",\"$.order_revenue\",\"$.order_region\",\"$.customer_id\"]" ) FROM KAFKA ( "kafka_broker_list" = "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "ods_order" ); CREATE ROUTINE LOAD flink_cdc.routine_load_customers ON customers COLUMNS (customer_id, customer_age, customer_name) PROPERTIES ( "format" = "json", "jsonpaths" = "[\"$.customer_id\",\"$.customer_age\",\"$.customer_name\"]" ) FROM KAFKA ( "kafka_broker_list" = "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "ods_customers" ); CREATE ROUTINE LOAD flink_cdc.routine_load_dwd_order_customer_valid ON dwd_order_customer_valid COLUMNS (order_id, order_revenue, order_region, customer_id, customer_age, customer_name) PROPERTIES ( "format" = "json", "jsonpaths" = "[\"$.order_id\",\"$.order_revenue\",\"$.order_region\",\"$.customer_id\",\"$.customer_age\",\"$.customer_name\"]" ) FROM KAFKA ( "kafka_broker_list" = "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "dwd_order_customer_valid" ); CREATE ROUTINE LOAD flink_cdc.routine_load_dws_agg_by_region ON dws_agg_by_region COLUMNS (order_region, order_cnt, order_total_revenue) PROPERTIES ( "format" = "json", "jsonpaths" = "[\"$.order_region\",\"$.order_cnt\",\"$.order_total_revenue\"]" ) FROM KAFKA ( "kafka_broker_list" = "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "dws_agg_by_region" );
手順 4: Flink ジョブを実行してデータストリームを開始する
Flink Change Data Capture (CDC) と Flink StarRocks コネクタ のパッケージをダウンロードし、Dataflow クラスタの /opt/apps/FLINK/flink-current/lib ディレクトリにアップロードします。
Dataflow クラスタの /opt/apps/FLINK/flink-current/opt/connectors/kafka ディレクトリにある JAR パッケージを /opt/apps/FLINK/flink-current/lib ディレクトリにコピーします。
SSH モードで Dataflow クラスタにログオンします。詳細については、「クラスタへのログオン」をご参照ください。
次のコマンドを実行して、クラスターを起動します。
重要このトピックの例はテスト目的のみです。実稼働環境で Flink ジョブを実行するには、YARN または Kubernetes を使用してジョブを送信します。詳細については、「Apache Hadoop YARN」および「Native Kubernetes」をご参照ください。
/opt/apps/FLINK/flink-current/bin/start-cluster.shFlink SQL ジョブのコードを記述し、demo.sql ファイルとして保存します。
次のコマンドを実行して、demo.sql ファイルを開きます。ビジネス要件に基づいてファイルを編集します。
vim demo.sqlファイル内のコードの例を次に示します。
CREATE DATABASE IF NOT EXISTS `default_catalog`.`flink_cdc`; -- 注文ソーステーブルを作成します。 CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`orders_src`( `order_id` INT NOT NULL, `order_revenue` FLOAT NOT NULL, `order_region` STRING NOT NULL, `customer_id` INT NOT NULL, PRIMARY KEY(`order_id`) NOT ENFORCED ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'emr_test', 'password' = 'Yz12****', 'database-name' = 'flink_cdc', 'table-name' = 'orders' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`customers_src` ( `customer_id` INT NOT NULL, `customer_age` FLOAT NOT NULL, `customer_name` STRING NOT NULL, PRIMARY KEY(`customer_id`) NOT ENFORCED ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'emr_test', 'password' = 'Yz12****', 'database-name' = 'flink_cdc', 'table-name' = 'customers' ); -- ods dwd および dws テーブルを作成します CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`ods_order_table` ( `order_id` INT, `order_revenue` FLOAT, `order_region` VARCHAR(40), `customer_id` INT, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'ods_order', 'properties.bootstrap.servers' = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', 'key.format' = 'json', 'value.format' = 'json' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`ods_customers_table` ( `customer_id` INT, `customer_age` FLOAT, `customer_name` STRING, PRIMARY KEY (customer_id) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'ods_customers', 'properties.bootstrap.servers' = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', 'key.format' = 'json', 'value.format' = 'json' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`dwd_order_customer_valid` ( `order_id` INT, `order_revenue` FLOAT, `order_region` STRING, `customer_id` INT, `customer_age` FLOAT, `customer_name` STRING, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'dwd_order_customer_valid', 'properties.bootstrap.servers' = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', 'key.format' = 'json', 'value.format' = 'json' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`dws_agg_by_region` ( `order_region` VARCHAR(40), `order_cnt` BIGINT, `order_total_revenue` FLOAT, PRIMARY KEY (order_region) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'dws_agg_by_region', 'properties.bootstrap.servers' = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', 'key.format' = 'json', 'value.format' = 'json' ); USE flink_cdc; BEGIN STATEMENT SET; INSERT INTO ods_order_table SELECT * FROM orders_src; INSERT INTO ods_customers_table SELECT * FROM customers_src; INSERT INTO dwd_order_customer_valid SELECT o.order_id, o.order_revenue, o.order_region, c.customer_id, c.customer_age, c.customer_name FROM customers_src c JOIN orders_src o ON c.customer_id=o.customer_id WHERE c.customer_id <> -1; INSERT INTO dws_agg_by_region SELECT order_region, count(*) as order_cnt, sum(order_revenue) as order_total_revenue FROM dwd_order_customer_valid GROUP BY order_region; END;次の表は、コードに含まれるパラメーターについて説明しています。
orders_src テーブルと customers_src テーブルの作成に使用されるパラメーター
パラメーター
説明
connector
値を mysql-cdc に設定します。
hostname
ApsaraDB RDS for MySQL インスタンスの内部エンドポイントです。
ApsaraDB RDSコンソールの ApsaraDB RDS for MySQL インスタンスの [データベース接続] ページで内部エンドポイントをコピーできます。例: rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com。
port
値を 3306 に設定します。
username
手順 1:ソース MySQL テーブルを作成する で作成されたアカウントの名前です。この例では、emr_test が使用されています。
password
手順 1:ソース MySQL テーブルを作成する で作成されたアカウントのパスワードです。この例では、Yz12**** が使用されています。
database-name
手順 1:ソース MySQL テーブルを作成する で作成されたデータベースの名前です。この例では、flink_cdc が使用されています。
table-name
手順 1:ソース MySQL テーブルを作成する で作成されたテーブルの名前です。
orders_src:この例では、orders が使用されています。
customers_src:この例では、customers が使用されています。
ods_order_table、ods_customers_table、dwd_order_customer_valid、および dws_agg_by_region テーブルを作成するためのパラメーター
パラメーター
説明
connector
値を upsert-kafka に設定します。
topic
手順 2:Kafka トピックを作成する で作成したトピックの名前です。
ods_order_table:この例では、ods_order が使用されています。
ods_customers_table:この例では、ods_customers が使用されています。
dwd_order_customer_valid:この例では、dwd_order_customer_valid が使用されています。
dws_agg_by_region:この例では、dws_agg_by_region が使用されています。
properties.bootstrap.servers
値は
192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092形式です。
次のコマンドを実行して、Flink ジョブを開始します。
/opt/apps/FLINK/flink-current/bin/sql-client.sh -f demo.sql
手順 5: データベースとテーブルの情報を表示する
SSH モードで StarRocks クラスタにログオンします。詳細については、「クラスタへのログオン」をご参照ください。
次のコマンドを実行して、StarRocks クラスターに接続します。
mysql -h127.0.0.1 -P 9030 -urootデータベース情報をクエリします。
次のコマンドを実行してデータベースを使用します。
use flink_cdc;次のコマンドを実行してテーブルに関する情報をクエリします。
show tables;次の出力が返されます。
+--------------------------+ | Tables_in_flink_cdc | +--------------------------+ | customers | | dwd_order_customer_valid | | dws_agg_by_region | | orders | +--------------------------+ 4 rows in set (0.01 sec)
手順 6: データを挿入し、挿入されたデータをクエリする
手順 1: ソース MySQL テーブルを作成する で作成したテストアカウントを使用して、ApsaraDB RDS for MySQL インスタンスにログオンします。詳細については、「DMS を使用して ApsaraDB RDS for MySQL インスタンスにログオンする」をご参照ください。
ApsaraDB for RDS MySQL データベースの [SQL コンソール] タブで、次のステートメントを実行して orders テーブルと customers テーブルにデータを挿入します。
INSERT INTO flink_cdc.orders(order_id,order_revenue,order_region,customer_id) VALUES(1,10,"beijing",1); INSERT INTO flink_cdc.orders(order_id,order_revenue,order_region,customer_id) VALUES(2,10,"beijing",1); INSERT INTO flink_cdc.customers(customer_id,customer_age,customer_name) VALUES(1, 22, "emr_test");SSH モードで StarRocks クラスタにログオンします。詳細については、「クラスタへのログオン」をご参照ください。
次のコマンドを実行して、StarRocks クラスターに接続します。
mysql -h127.0.0.1 -P 9030 -urootオペレーショナルデータストア(ODS)レイヤーでデータをクエリします。
次のコマンドを実行してデータベースを使用します。
use flink_cdc;次のステートメントを実行して、orders テーブルからデータをクエリします。
select * from orders;次の出力が返されます。
+----------+---------------+--------------+-------------+ | order_id | order_revenue | order_region | customer_id | +----------+---------------+--------------+-------------+ | 1 | 10 | beijing | 1 | | 2 | 10 | beijing | 1 | +----------+---------------+--------------+-------------+次のステートメントを実行して、customers テーブルからデータをクエリします。
select * from customers;次の出力が返されます。
+-------------+--------------+---------------+ | customer_id | customer_age | customer_name | +-------------+--------------+---------------+ | 1 | 22 | emr_test | +-------------+--------------+---------------+
DWD レイヤーのデータをクエリします。
次のコマンドを実行してデータベースを使用します。
use flink_cdc;次のステートメントを実行して、orders テーブルからデータをクエリします。
select * from dwd_order_customer_valid;次の出力が返されます。
+----------+---------------+--------------+-------------+--------------+---------------+ | order_id | order_revenue | order_region | customer_id | customer_age | customer_name | +----------+---------------+--------------+-------------+--------------+---------------+ | 1 | 10 | beijing | 1 | 22 | emr_test | | 2 | 10 | beijing | 1 | 22 | emr_test | +----------+---------------+--------------+-------------+--------------+---------------+ 2 rows in set (0.00 sec)
DWS レイヤーでデータをクエリします。
次のコマンドを実行してデータベースを使用します。
use flink_cdc;次のステートメントを実行して、orders テーブルからデータをクエリします。
select * from dws_agg_by_region;次の出力が返されます:
+--------------+-----------+---------------------+ | order_region | order_cnt | order_total_revenue | +--------------+-----------+---------------------+ | beijing | 2 | 20 | +--------------+-----------+---------------------+ 1 row in set (0.01 sec)