自動スケーリングは、定義したルールに基づいてタスクノードを自動的に追加または削除し、コンピューティングリソースを実際のワークロードに合わせて維持します。このトピックでは、EMR コンソールで EMR Hadoop クラスターの自動スケーリングを設定する方法について説明します。
前提条件
開始する前に、以下を確認してください。
EMR Hadoop クラスターが作成済みであること。詳細については、「クラスターの作成」をご参照ください。
注意事項
スケーリングノードのハードウェア仕様は、自動スケーリングが無効な場合にのみ変更可能です。仕様を変更するには、自動スケーリングを無効にしてから変更を行い、再度有効化してください。
システムは、入力した vCPU およびメモリ仕様に一致するインスタンスタイプを自動的に検索し、結果を [インスタンスタイプ] セクションに一覧表示します。リストから少なくとも 1 つのインスタンスタイプを選択してください — 選択したタイプを使用してクラスターがスケールします。
ECS リソースの不足によるスケーリングの失敗リスクを軽減するために、最大 3 つのインスタンスタイプを選択してください。
データディスクの最小サイズは、ディスクタイプ (Ultra ディスクまたは標準 SSD) にかかわらず 40 GiB です。
負荷ベースのスケーリングは CloudMonitor を利用します。負荷ベースのスケーリングルールを保存すると、CloudMonitor は対応するアラートルールを自動的に作成します。これらのアラートルールを変更、削除、または無効にすると、自動スケーリングが正常に機能しなくなる可能性があるため、操作しないでください。
スケーリングトリガーモードの選択
ルールを設定する前に、どのトリガーモードがワークロードに適しているかを決定します。
| ワークロードが... | 使用方法... |
|---|---|
| 夜間のバッチジョブや日次レポートなど、予測可能なスケジュールに従う場合 | 時間ベースのスケーリング |
| 実際のクラスター負荷に基づいて、日中に予測不能に変動する場合 | 負荷ベースのスケーリング |
自動スケーリングを無効にすると、すべてのルールがクリアされます。自動スケーリングを再度有効にするには、ルールを再設定する必要があります。トリガーモードを切り替えると、以前のモードのルールは無効になりますが、すでに追加されていたノードは保持されます。
自動スケーリングの設定
ステップ 1:[Auto Scaling] タブを開く
EMR コンソールにログインします。左側のナビゲーションウィンドウで、[EMR on ECS] をクリックします。
上部のナビゲーションバーで、クラスターが存在するリージョンを選択し、リソースグループを選択します。
[EMR on ECS] ページで、[クラスター ID/名前] 列にあるクラスター名をクリックします。
[Auto Scaling] タブをクリックします。
ステップ 2:自動スケーリンググループの作成
[スケーリングの設定] タブで、[自動スケーリンググループの作成] をクリックします。
自動スケーリンググループは [Auto Scaling] タブでのみ設定および管理できます。
[自動スケーリンググループの追加] ダイアログボックスで、[ノードグループ名] フィールドに名前を入力し、[OK] をクリックします。
ステップ 3:スケーリングルールの設定を開く
[スケーリングの設定] タブで、作成した自動スケーリンググループを見つけ、[操作] 列の [ルールの設定] をクリックします。
ステップ 4:基本設定の構成
[基本情報] セクションで、以下のパラメーターを設定します。
| パラメーター | 説明 |
|---|---|
| インスタンスの最大数 | 自動スケーリンググループ内のタスクノードの最大数。スケーリングルールがトリガーされても、グループがこの上限に達している場合、ノードは追加されません。最大値:1,000。 |
| インスタンスの最小数 | 自動スケーリンググループ内のタスクノードの最小数。スケールアウトルールがこの最小数より少ないノードを追加する場合、システムは最初のトリガーで最小数までスケーリングします。例えば、最小数が 3 で、ルールが毎日 00:00 に 1 ノードを追加する場合、システムは初日に最小数を満たすために 3 ノードを追加し、その後のトリガーではルールに従います。 |
| グレースフルシャットダウン | YARN ジョブを実行しているタスクノードがデコミッションされるまでのタイムアウト期間。ジョブがこのタイムアウト期間より長く実行される場合、またはノードで YARN ジョブが実行されていない場合、システムはそのノードをデコミッションします。最大値:3,600 秒。この設定を有効にする前に、以下のグレースフルシャットダウンの注意事項セクションをご参照ください。 |
グレースフルシャットダウンの注意事項
グレースフルシャットダウンを有効にする前に:
YARN サービスページで、
yarn.resourcemanager.nodes.exclude-pathパラメーターを/etc/ecm/hadoop-conf/yarn-exclude.xmlに設定します。[タイムアウト期間] を変更した後、オフピーク時に YARN ResourceManager を再起動して変更を有効にします。
ステップ 5:インスタンスタイプと課金方法の設定
[自動スケーリングの設定] パネルの中間セクションで、[インスタンスタイプ選択モード]、[課金方法]、および [インスタンスタイプ] を設定します。
単一の課金方法
システムは、入力された vCPU とメモリの仕様に一致するインスタンスタイプを検索し、[インスタンスタイプ] セクションに一覧表示します。インスタンスタイプを選択した順序で、その優先度が設定されます。以下のいずれかの課金方法を選択します。
従量課金:各ディスク仕様の下に表示される時間単価は、EMR サービス料金と ECS インスタンス料金の合計です。
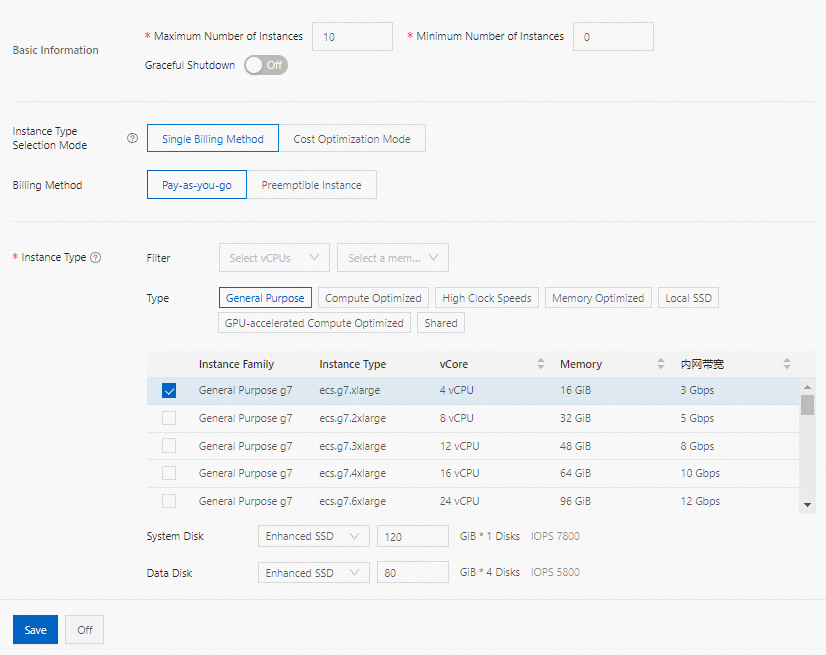
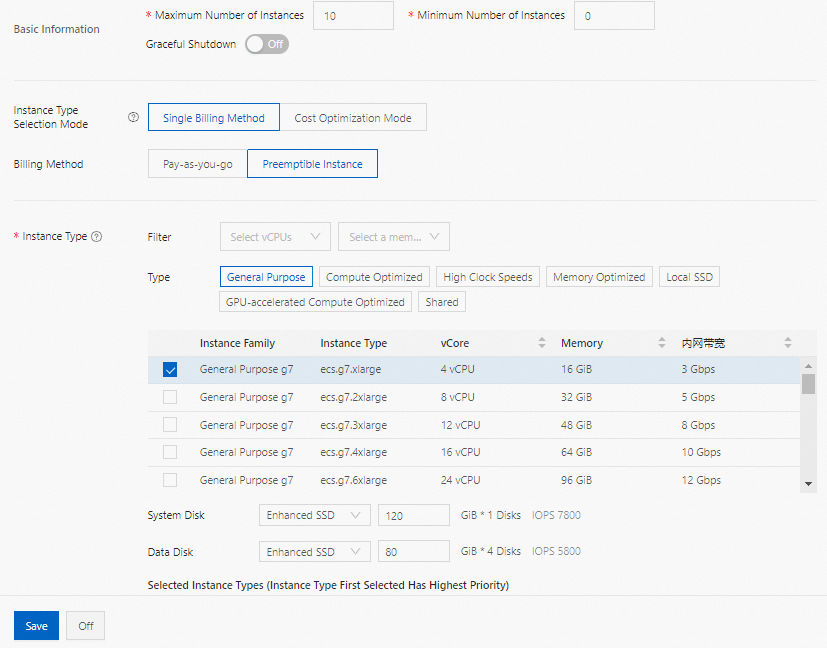
プリエンプティブルインスタンス:従量課金と同じ優先順位を使用します。従量課金の価格は参考として表示され、時間単価の上限を設定できます。インスタンスタイプの価格が設定した上限以下の場合にのみ、リストに表示されます。詳細については、「プリエンプティブルインスタンスとは」をご参照ください。
重要プリエンプティブルインスタンスは、入札が失敗した場合やリソースが利用できなくなった場合に解放されることがあります。ジョブに厳しい SLA 要件がある場合は、プリエンプティブルインスタンスを使用しないでください。
コスト最適化モード
コスト最適化モードでは、従量課金インスタンスとプリエンプティブルインスタンスの混合フリートを定義して、コストと安定性のバランスを取ることができます。
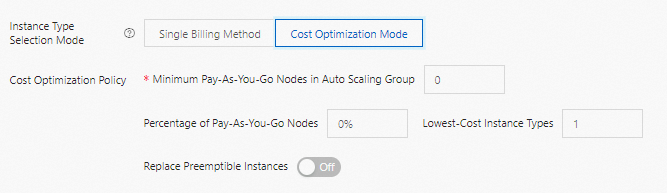
| パラメーター | 説明 |
|---|---|
| 自動スケーリンググループ内の最小従量課金ノード数 | グループが維持しなければならない従量課金インスタンスの最小数。現在の数がこの値を下回ると、システムはまず従量課金インスタンスを作成します。 |
| 従量課金ノードの割合 | 最小数が満たされた後、この割合がグループ全体のサイズに対する新しい従量課金インスタンスの比率を決定します。 |
| 最もコストが低いインスタンスタイプ | プリエンプティブルインスタンスを作成する際に考慮する最も安価なインスタンスタイプの数。システムは、これらのタイプにプリエンプティブルインスタンスを均等に分散させます。最大値:3。 |
| プリエンプティブルインスタンスの置き換え | 有効にすると、プリエンプティブルインスタンスが回収される約 5 分前に、システムは自動的にプリエンプティブルインスタンスを従量課金インスタンスに置き換えます。 |
コスト最適化モードの一般的な設定:
「従量課金ノードの最小数」、「従量課金ノードの割合」、および[コストが最も低いインスタンスタイプ]を空白のままにした場合、このグループは一般的なコスト最適化スケーリンググループとして機能します。これらのパラメーターを設定すると、マルチインスタンス対応のコスト最適化スケーリンググループが作成されます。どちらのタイプも完全に互換です。
混合インスタンス設定を使用して、通常のコスト最適化スケーリンググループの動作を再現するには:
従量課金インスタンスのみ:最小値を
0、割合を100%、最低コストのインスタンスタイプ数を1に設定します。プリエンプティブルインスタンスを優先:最小値を
0、割合を0%、最低コストのインスタンスタイプ数を1に設定します。
ステップ 6:トリガーモードとルールの設定
時間ベースのスケーリング
時間ベースのスケーリングは、スケジュールされた時刻 (毎日、毎週、または毎月) に固定数のタスクノードを追加または削除します。ワークロードが予測可能なパターンに従う場合に使用します。
自動スケーリングルールは、スケールアウトルールとスケールインルールに分かれています。それぞれを個別に設定します。次の表は、スケールアウトルールのパラメーターを説明しています (スケールインルールも同じパラメーターを使用します)。
| パラメーター | 説明 |
|---|---|
| ルール名 | クラスター内で一意のルール名。 |
| 実行ルール | 繰り返し実行: 指定された時刻に定期スケジュール(毎日、毎週、または毎月)でトリガーされます。[1 回のみ実行]: 指定された時刻に 1 回だけトリガーされます。 |
| 実行時間 | ルールが実行される時刻。 |
| ルールの有効期限 | ルールが実行を停止する日時。 |
| リトライ時間範囲 | 失敗したスケーリング操作をシステムがリトライする期間。システムはこの期間内に操作が成功するまで 30 秒ごとにリトライします。有効な値:0~21,600 秒。例えば、このルールがトリガーされたときに別のスケーリング操作が実行中またはクールダウン中の場合、システムは期間が終了するか条件が満たされるまで 30 秒ごとにリトライを続けます。 |
| 調整するインスタンス数 | ルールがトリガーされるたびに追加 (または削除) するタスクノードの数。 |
| クールダウンタイム (秒) | 2 つのスケールアウトアクティビティ間の間隔。クールダウン中はスケールアウトアクティビティは禁止されます。 |
負荷ベースのスケーリング
負荷ベースのスケーリングは、YARN クラスターのメトリックに基づいてタスクノードを追加または削除します。ワークロードの変動を事前に予測するのが難しい場合に使用します。
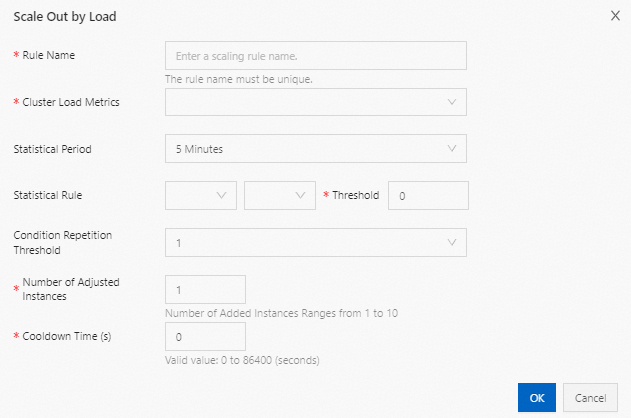
| パラメーター | 説明 |
|---|---|
| ルール名 | クラスター内で一意のルール名。 |
| クラスター負荷メトリック | このルールを駆動する YARN メトリック。メトリックは YARN から取得されます。完全なリストについては、「Hadoop 公式ドキュメント」およびこのトピックの最後にあるYARN メトリックリファレンスの表をご参照ください。 |
| 統計期間 | システムが設定された集約 (平均、最大、または最小) を使用して選択されたメトリックを評価する時間枠。 |
| 統計ルール | ルールが繰り返ししきい値にカウントされるために満たす必要がある集約ディメンションとしきい値条件。 |
| 条件の繰り返ししきい値 | スケーリングがトリガーされる前に、しきい値が満たされなければならない連続した統計期間の数。 |
| 調整するインスタンス数 | ルールがトリガーされるたびに追加 (または削除) するタスクノードの数。 |
| クールダウンタイム (秒) | 2 つの連続したスケーリング操作間の最小間隔。クールダウン中は、しきい値条件が再度満たされてもスケーリングはトリガーされません。クールダウンが終了すると、条件が満たされ次第ルールがトリガーされます。 |
ステップ 7:自動スケーリングの保存と有効化
[保存] をクリックして設定を保存します。
設定を保存しても自動スケーリングは有効になりません。ルールを有効化するには、「自動スケーリングの有効化または無効化 (Hadoop クラスター)」をご参照ください。
YARN メトリックリファレンス
以下の YARN メトリックは、負荷ベースのスケーリングルールで利用できます。通常、スケールアウトはリソース需要メトリック (Pending、AllocatedContainers) がしきい値を超えたときにトリガーされ、スケールインはしきい値を下回ったときにトリガーされます。
| EMR 自動スケーリングメトリック | サービス | 説明 |
|---|---|---|
| YARN.AvailableVCores | YARN | 利用可能な vCPU 数 |
| YARN.PendingVCores | YARN | リクエストされたがまだ割り当てられていない vCPU 数 |
| YARN.AllocatedVCores | YARN | 割り当て済みの vCPU 数 |
| YARN.ReservedVCores | YARN | 予約済みの vCPU 数 |
| YARN.AvailableMemory | YARN | 利用可能なメモリ (MB) |
| YARN.PendingMemory | YARN | リクエストされたがまだ割り当てられていないメモリ (MB) |
| YARN.AllocatedMemory | YARN | 割り当て済みのメモリ (MB) |
| YARN.ReservedMemory | YARN | 予約済みのメモリ (MB) |
| YARN.AppsRunning | YARN | 実行中のアプリケーション |
| YARN.AppsPending | YARN | 保留中のアプリケーション数 |
| YARN.AppsKilled | YARN | 終了済みアプリケーション |
| YARN.AppsFailed | YARN | 失敗したアプリケーション数 |
| YARN.AppsCompleted | YARN | 完了したアプリケーション数 |
| YARN.AppsSubmitted | YARN | 送信されたアプリケーション数 |
| YARN.AllocatedContainers | YARN | 割り当て済みの YARN コンテナ数 |
| YARN.PendingContainers | YARN | リクエストされたがまだ割り当てられていないコンテナ数 |
| YARN.ReservedContainers | YARN | 予約済みの YARN コンテナ数 |
| YARN.MemoryAvailablePrecentage | YARN | 合計メモリに対する利用可能なメモリの割合:AvailableMemory / Total Memory |
| YARN.ContainerPendingRatio | YARN | 割り当て済みコンテナに対する保留中コンテナの比率:PendingContainers / AllocatedContainers |