Celeborn は中間データを処理するサービスです。 Celeborn は、ビッグデータ コンピューティング エンジンの安定性、柔軟性、およびパフォーマンスを向上させることができます。このトピックでは、Celeborn サービスの使用方法について説明します。
背景情報
現在のシャッフル ソリューションには、次の欠点があります。
シャッフル書き込みタスクに大量のデータが存在する場合、データ オーバーフローが発生します。これにより、書き込みの増幅が発生します。
シャッフル読み取りタスクには、多数の小さなネットワーク パケットが存在します。これにより、接続がリセットされます。
シャッフル読み取りタスクには、多数の小さな I/O 要求とランダム読み取りが存在します。これにより、ディスクと CPU の負荷が高くなります。
何千ものマッパー(M)とレデューサー(N)が使用されている場合、多数の接続が生成され、ジョブの実行が困難になります。接続数は、次の式を使用して計算されます。M × N。
Spark シャッフル サービスは NodeManager で実行されます。シャッフリングに関係するデータ量が非常に大きい場合、NodeManager が再起動されます。これは、YARN ベースのタスク スケジューリングの安定性に影響します。
Celeborn サービスは、シャッフル ソリューションを最適化できます。 Celeborn サービスには、次の利点があります。
プル型シャッフルではなくプッシュ型シャッフルを使用することにより、マッパーによって引き起こされるメモリ負荷を軽減します。
I/O 集約をサポートし、シャッフル読み取りタスクの接続数を M × N から N に減らし、ランダム読み取りをシーケンシャル読み取りに変換します。
2 レプリカ メカニズムを使用して、フェッチ失敗の確率を減らします。
コンピューティングとストレージの分離をサポートします。シャッフル サービスは、分離されたハードウェア環境にデプロイできます。
Kubernetes 上の Spark を使用する場合、ローカル ディスクへの依存を排除します。
次の図は、Celeborn のアーキテクチャを示しています。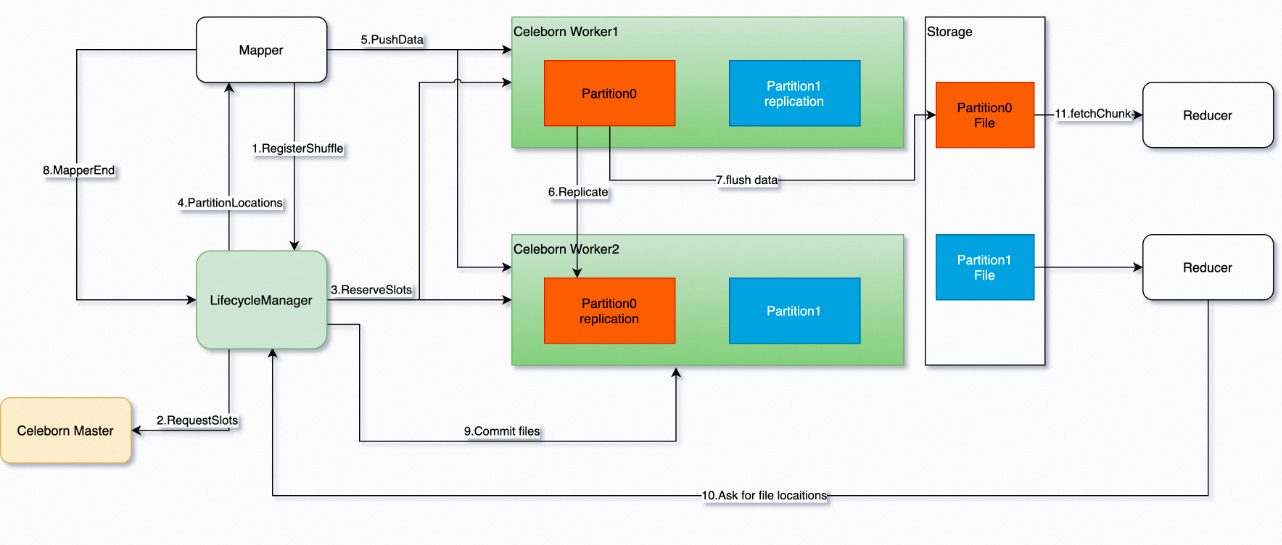
前提条件
E-MapReduce(EMR)Data Lake クラスタまたはカスタム クラスタが作成され、クラスタに対して Celeborn サービスが選択されています。クラスタの作成方法の詳細については、クラスタの作成をご参照ください。
制限事項
このトピックは、次の表に示すクラスタにのみ適用されます。
クラスタ | バージョン |
Data Lake クラスタ | EMR V3.45.0 以後のマイナー バージョン、および EMR V5.11.0 以後のマイナー バージョン |
カスタム クラスタ | EMR V3.45.0 以後のマイナー バージョン、および EMR V5.11.0 以後のマイナー バージョン |
手順
Spark パラメータ
パラメータ | 説明 |
spark.shuffle.manager |
|
spark.serializer | 値を org.apache.spark.serializer.KryoSerializer に設定します。 |
spark.celeborn.push.replicate.enabled | 2 レプリカ機能を有効にするかどうかを指定します。有効な値:
|
spark.shuffle.service.enabled | このパラメータの値を false に変更します。 Celeborn を使用するには、外部シャッフル サービスを無効にする必要があります。 Celeborn は、Spark の動的割り当て機能の使用には影響しません。 説明
|
spark.celeborn.shuffle.writer | Celeborn の書き込みモード。
|
spark.celeborn.master.endpoints | このパラメータの値を <celeborn-master-ip>:<celeborn-master-port> 形式で指定します。 パラメータ:
高可用性クラスタを作成する場合は、すべてのマスター ノードの IP アドレスを設定することをお勧めします。 |
spark.sql.adaptive.enabled | Celeborn サービスの適応実行を有効にできます。ローカル シャッフル リーダーを無効にして、高いシャッフル パフォーマンスを確保できます。 spark.sql.adaptive.enabled パラメータを true に、spark.sql.adaptive.localShuffleReader.enabled パラメータを false に、spark.sql.adaptive.skewJoin.enabled パラメータを true に設定する必要があります。 |
spark.sql.adaptive.localShuffleReader.enabled | |
spark.sql.adaptive.skewJoin.enabled |
ワンクリックで Spark の Celeborn サービスを有効にできます。
EMR V5.11.1 以降のマイナー バージョンのクラスタ、および EMR V3.45.1 以降のマイナー バージョンのクラスタ
Spark サービス ページの [ステータス] タブの [サービス概要] セクションで、[enableceleborn] をオンにします。
EMR V5.11.0 および EMR V3.45.0 のクラスタ
Spark サービス ページの [ステータス] タブの [コンポーネント] セクションで、SparkThriftServer コンポーネントを見つけ、[アクション] 列の
 アイコンにポインタを移動し、[enableCeleborn] を選択します。 [enableceleborn] をクリックすると、前の表で説明されている Spark パラメータが自動的に変更され、SparkThriftServer コンポーネントが再起動されます。 spark-defaults.conf および spark-thriftserver.conf 構成ファイルも自動的に変更されます。
アイコンにポインタを移動し、[enableCeleborn] を選択します。 [enableceleborn] をクリックすると、前の表で説明されている Spark パラメータが自動的に変更され、SparkThriftServer コンポーネントが再起動されます。 spark-defaults.conf および spark-thriftserver.conf 構成ファイルも自動的に変更されます。[enableceleborn] をクリックすると、クラスタ内のすべての Spark ジョブで Celeborn サービスが使用されます。
[disableceleborn] をクリックすると、クラスタ内のすべての Spark ジョブで Celeborn サービスが使用されません。
Celeborn パラメータ
Celeborn サービス ページの [構成] タブで、すべての Celeborn パラメータの構成を表示または変更できます。次の表にパラメータを示します。
パラメータの値は、ノード グループによって異なります。
パラメータ | 説明 | デフォルト値 |
celeborn.worker.flusher.threads | ハード ディスク(HDD)またはソリッドステート ディスク(SSD)ディスクにデータが書き込まれるときの、スレッドの数。 |
|
CELEBORN_WORKER_OFFHEAP_MEMORY | ワーカー ノードのオフヒープ メモリのサイズ。 | デフォルト値は、クラスタ設定に基づいて計算されます。 |
celeborn.application.heartbeat.timeout | アプリケーションのハートビート タイムアウト期間。単位:秒。ハートビート タイムアウト期間が経過すると、アプリケーション関連のリソースがクリアされます。 | 120s |
celeborn.worker.flusher.buffer.size | フラッシュ バッファのサイズ。フラッシュ バッファのサイズが上限を超えると、フラッシュがトリガーされます。 | 256K |
celeborn.metrics.enabled | モニタリングを有効にするかどうかを指定します。有効な値:
| true |
CELEBORN_WORKER_MEMORY | コア ノードのヒープ メモリのサイズ。 | 1g |
CELEBORN_MASTER_MEMORY | マスター ノードのヒープ メモリのサイズ。 | 2g |
CelebornMaster コンポーネントの再起動
Celeborn サービス ページの [ステータス] タブで、CelebornMaster コンポーネントを見つけ、[アクション] 列の
アイコンにポインタを移動し、[restart_clean_meta] を選択します。説明クラスタが高可用性でないクラスタの場合、CelebornMaster コンポーネントの [アクション] 列の [再起動] をクリックできます。
表示されるダイアログ ボックスで、[ローリング実行] をオフにし、[実行理由] パラメータを構成して、[OK] をクリックします。
確認メッセージで、[OK] をクリックします。