Apache Hadoop Distributed File System (HDFS) 向けの JindoFSx の透過的キャッシュ機能を使用すると、コンピューティングクラスターのアイドル状態のストレージリソースを使用して、リモート HDFS クラスターのデータをキャッシュできます。これにより、コンピューティングクラスターが過剰な帯域幅を占有するのを防ぎ、コアクラスターに十分な帯域幅を確保できます。 HDFS クラスターがコンピューティングクラスターから分離されており、HDFS クラスターのアクセス パフォーマンスが要件を満たしていない場合は、コンピューティングクラスター内またはその近くにデータをキャッシュしてアクセスを高速化できます。
前提条件
EMR V3.42.0 以降のマイナー バージョンのクラスター、または EMR V5.6.0 以降のマイナー バージョンのクラスターが EMR コンソールで作成され、クラスターの作成時にオプション サービスから JindoData サービスが選択されています。詳細については、「クラスターの作成」をご参照ください。
手順
手順 1:サーバーの構成
JindoData サービスの [共通] タブに移動します。
上部のナビゲーション バーで、クラスターが存在するリージョンを選択し、ビジネス要件に基づいてリソース グループを選択します。
[ECS 上の EMR] ページで、管理するクラスターを見つけ、[アクション] 列の [サービス] をクリックします。
JindoData セクションで [構成] をクリックします。
[共通] タブをクリックします。
構成項目を追加します。
[構成項目の追加] をクリックします。
[構成項目の追加] ダイアログ ボックスで、次の表に示すパラメーターを追加します。
構成項目を追加する方法の詳細については、「構成項目の追加」をご参照ください。
クラスタータイプ
パラメーター
説明
共通クラスター
jindofsx.hdfs.user
HDFS へのアクセスに使用するユーザー名。例:hadoop。
高可用性 (HA) クラスター
jindofsx.hdfs.XXX.dfs.ha.namenodes
hdfs-site.xml ファイルの
dfs.ha.namenodes.XXXパラメーターの値。例:nn1、nn2、nn3。jindofsx.hdfs.XXX.dfs.namenode.rpc-address.nn1
hdfs-site.xml ファイルの
dfs.namenode.rpc-address.XXX.nn1パラメーターの値。例:master-1-1:8020。jindofsx.hdfs.XXX.dfs.namenode.rpc-address.nn2
hdfs-site.xml ファイルの
dfs.namenode.rpc-address.XXX.nn2パラメーターの値。例:master-1-2:8020。jindofsx.hdfs.XXX.dfs.namenode.rpc-address.nn3
hdfs-site.xml ファイルの
dfs.namenode.rpc-address.XXX.nn3パラメーターの値。例:master-1-3:8020。説明クラスターのタイプに基づいて構成項目を追加できます。
XXXは、hdfs-site.xml ファイルで構成したdfs.nameservicesパラメーターの値を示します。例:hdfs-cluster。[OK] をクリックします。
表示されるダイアログ ボックスで、[実行理由] パラメーターを構成し、[保存] をクリックします。
JindoData サービスを再起動します。
JindoData サービスの [サービス] タブで、 を選択します。
[JINDODATA サービスの再起動] ダイアログ ボックスで、実行理由を指定し、[OK] をクリックします。
[確認] メッセージで、[OK] をクリックします。
手順 2:JindoSDK の構成
この手順では、クライアントを構成します。この手順を完了した後、JindoData サービスを再起動する必要はありません。
[構成] タブに移動します。
上部のナビゲーション バーで、クラスターが存在するリージョンを選択し、ビジネス要件に基づいてリソース グループを選択します。
[ECS 上の EMR] ページで、管理するクラスターを見つけ、サービス[アクション] 列の をクリックします。
[サービス] タブで、HADOOP-COMMON セクションの [構成] をクリックします。
[core-site.xml] タブをクリックします。
次の表に示す構成項目を追加および変更します。
構成項目を追加する方法の詳細については、「構成項目の追加」をご参照ください。構成項目を変更する方法の詳細については、「構成項目の変更」をご参照ください。
項目
必須
パラメーター
説明
統合名前空間の実装クラスの構成
はい
fs.hdfs.impl
値を
com.aliyun.jindodata.hdfs.JindoHdfsFileSystemに設定します。はい
fs.AbstractFileSystem.hdfs.impl
値を
com.aliyun.jindodata.hdfs.HDFSに設定します。xengine タイプの構成
はい
fs.xengine
値を
jindofsxに設定します。JindoFSx 名前空間サービスのエンドポイントの構成
はい
fs.jindofsx.namespace.rpc.address
${headerhost}:8101 の形式で値を設定します。例:master-1-1:8101。
説明高可用性モードでの名前空間サービスの構成と使用方法の詳細については、「高可用性モードでの JindoFSx 名前空間サービスの構成と使用方法」をご参照ください。
アクセス高速化のためのデータ キャッシュの有効化
はい
fs.jindofsx.data.cache.enable
データ キャッシュを有効にするかどうかを指定します。有効な値:
false:データ キャッシュを無効にします。これはデフォルト値です。
true:データ キャッシュを有効にします。
HA ネームノードの構成
説明HA クラスターの場合は、これらのパラメーターを構成する必要があります。
いいえ
fs.jindofsx.hdfs.XXX.dfs.ha.namenodes
hdfs-site.xml ファイルの
dfs.ha.namenodes.XXXパラメーターの値。例:nn1、nn2、nn3。いいえ
fs.jindofsx.hdfs.XXX.dfs.namenode.rpc-address.nn1
hdfs-site.xml ファイルの
dfs.namenode.rpc-address.XXX.nn1パラメーターの値。例:master-1-1:8020。いいえ
fs.jindofsx.hdfs.XXX.dfs.namenode.rpc-address.nn2
hdfs-site.xml ファイルの
dfs.namenode.rpc-address.XXX.nn2パラメーターの値。例:master-1-2:8020。いいえ
fs.jindofsx.hdfs.XXX.dfs.namenode.rpc-address.nn3
hdfs-site.xml ファイルの
dfs.namenode.rpc-address.XXX.nn3パラメーターの値。例:master-1-3:8020。メタデータ キャッシュの有効化
いいえ
fs.jindofsx.meta.cache.enable
メタデータ キャッシュを有効にするかどうかを指定します。有効な値:
false:メタデータ キャッシュを無効にします。これはデフォルト値です。
true:メタデータ キャッシュを有効にします。
小規模ファイル キャッシュの有効化
いいえ
fs.jindofsx.slice.cache.enable
小規模ファイルのキャッシュを有効にするかどうかを指定します。有効な値:
false:小規模ファイルのキャッシュを無効にします。これはデフォルト値です。
true:小規模ファイルのキャッシュを有効にします。
ショートサーキット読み取りの有効化
いいえ
fs.jindofsx.short.circuit.enable
ショートサーキット読み取りを有効にするかどうかを指定します。有効な値:
true:ショートサーキット読み取りを有効にします。これはデフォルト値です。
false:ショートサーキット読み取りを無効にします。
構成を保存します。
保存[構成] タブの をクリックします。
表示されるダイアログ ボックスで、[実行理由] パラメーターを構成し、[構成を自動的に更新] をオンにして、[保存] をクリックします。
手順 3:ディスク容量の使用量の制御
キャッシュ機能を有効にすると、JindoFSx はキャッシュされたデータを管理します。 JindoFSx は、キャッシュされたデータに対して構成したディスク容量の使用量に基づいて、キャッシュされたデータをクリアします。ビジネス要件に基づいて、キャッシュされたデータのディスク容量の使用量を構成します。 JindoFSx は、データ ストレージ バックエンドとして HDFS を使用します。 HDFS には大量のデータを格納できます。ただし、ローカル ディスクの容量は限られています。 JindoFSx は、ローカル ディスクのコールド データを削除します。 storage.watermark.high.ratio パラメーターと storage.watermark.low.ratio パラメーターを構成して、ローカル ディスクの容量の使用量を調整できます。各パラメーターを 0 ~ 1 の範囲の値に設定できます。
ディスク使用量の構成を変更します。
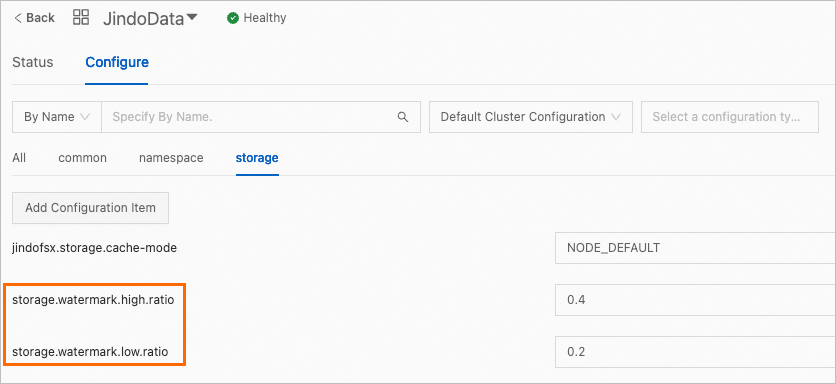
JindoData サービス ページの [構成] タブで、[ストレージ] タブで次のパラメーターを変更します。
パラメーター
説明
storage.watermark.low.ratio
ディスク使用量の下限。自動データ削除がトリガーされると、JindoFSx は、キャッシュされたデータのディスク使用量がこの制限まで減少するまで、データの削除を開始します。デフォルト値:0.2。
storage.watermark.high.ratio
ディスク使用量の上限。キャッシュされたデータのディスク使用量がこの制限に達すると、自動データ削除がトリガーされます。デフォルト値:0.4。より高いディスク使用量が必要な場合は、このパラメーターをより大きな値に設定できます。
説明パラメーターを構成するときは、上限が下限よりも大きいことを確認してください。
構成を保存します。
[保存] をクリックします。
表示されるダイアログ ボックスで、[実行理由] パラメーターを構成し、[保存] をクリックします。
JindoData サービスを再起動します。
JindoData サービス ページで、右上隅にある を選択します。
[JINDODATA サービスの再起動] ダイアログ ボックスで、[実行理由] パラメーターを構成し、その他のパラメーターにはデフォルト値を保持して、[OK] をクリックします。
[確認] メッセージで、[OK] をクリックします。
手順 4:HDFS へのアクセス
hdfs:// プレフィックスを使用して OSS-HDFS からデータを読み取ると、データ キャッシュが有効になっている場合、データは自動的に JindoFSx にキャッシュされます。このようにして、hdfs:// プレフィックスを使用して同じデータを再度読み取ると、キャッシュされたデータが読み取られます。