このトピックでは、Amazon Web Services (AWS) Glue データカタログから Alibaba Cloud Data Lake Formation (DLF) にメタデータをシームレスに移行する方法について説明します。メタデータには、データベース、テーブル、パーティションに関する情報などが含まれます。 DLF が提供する一元化されたメタデータ管理、権限とセキュリティ管理、およびレイク管理機能をフルに活用して、Alibaba Cloud で安全で統一されたクラウドネイティブのデータレイク環境を迅速に構築および維持できます。
背景情報
この移行は増分更新をサポートしています。データの重複なしに、移行操作を繰り返し実行できます。ジョブが実行されるたびに、システムはソース (AWS Glue) と宛先 (DLF) のメタデータを自動的に比較します。ソースのメタデータが宛先に存在しない場合、または宛先のメタデータがソースのメタデータと異なる場合にのみ、システムは宛先にメタデータを追加または更新します。ソースにメタデータが存在しない場合、システムは宛先のメタデータを自動的にクリアします。これにより、メタデータの整合性が確保されます。移行計画は複数の企業で正常に適用されています。次の図は、移行プロセスを示しています。

移行プロセス:
AWS Glue からメタデータを抽出する: Spark を使用して AWS Glue API に接続し、AWS Glue からメタデータを読み取ります。メタデータには、データベース、テーブル、パーティション、および関数に関する情報が含まれます。
メタデータを変換および処理する: 移行ロジックに基づいて抽出されたメタデータを変換および処理し、Alibaba Cloud DLF のデータ形式またはデータ構造に関する要件を満たします。移行ロジックは、増分更新または完全同期にすることができます。
DLF にメタデータをロードする: DLF API を使用して、処理されたメタデータを Alibaba Cloud DLF にアップロードします。
注意事項
約 5,000,000 個のパーティションを含むデータセットからメタデータを移行するために Spark ジョブを初めて実行する場合、以前の顧客の経験に基づいて、メタデータの移行に約 2 ~ 3 時間かかる場合があります。その後、定期的にジョブを実行する場合、移行操作は 20 分以内に完了できます。
手順
ステップ 1: JAR パッケージをダウンロードする
方法 1: をクリックしてパッケージをダウンロードします。
方法 2: CLI で次のコマンドを実行して JAR パッケージをダウンロードします:
wget http://dlf-lib.oss-cn-hangzhou.aliyuncs.com/jars/glue-1.0-SNAPSHOT-jar-with-dependencies.jar
ステップ 2: 構成ファイルを準備する
オンプレミスのマシンに
application.propertiesという名前の構成ファイルを作成します。構成ファイルが既に存在する場合は、構成ファイルを変更します。構成ファイルには、AWS および Alibaba Cloud E-MapReduce (EMR) にアクセスするために必要な認証情報、およびその他の必要な構成情報が含まれています。
構成ファイルを指定の位置にアップロードします。たとえば、構成ファイルをオンプレミスの Hadoop Distributed File System (HDFS)、Alibaba Cloud Object Storage Service (OSS)、または Amazon S3 にアップロードできます。
この例では、構成ファイルを Alibaba Cloud OSS にアップロードします。例: oss://<bucket>/path/application.properties。
## AWS へのアクセスに使用される AccessKey ID と AccessKey シークレット。 AWS EMR クラスタでジョブを実行する場合は、AccessKey ペアを空のままにすることができます。それ以外の場合は、AccessKey ペアを指定する必要があります。
aws.accessKeyId=xxxxx
aws.secretAccessKey=xxxxxx
## AWS リージョン。
aws.region=eu-central-1
## (必須) AWS Glue データカタログの ID。デフォルト値は AWS アカウントの ID です。
aws.catalogId=xxxx
## (オプション) メタデータを移行するデータベースの名前。このパラメータは、データベースをフィルタリングするために使用されます。このパラメータが構成されていない場合は、すべてのデータベースのメタデータが移行されます。
aws.databases=db1,db2
## (オプション) メタデータを移行するテーブルの名前のプレフィックス。このパラメータは、テーブルをフィルタリングするために使用されます。複数のテーブル名プレフィックスを指定し、コンマ (,) で区切ることができます。プレフィックス間にスペースを入れることはできません。
aws.table.filter.prefix=ods_,adm_
## (オプション) メタデータを移行するパーティション。このパラメータは、パーティションをフィルタリングするために使用されます。複数のパーティションフィルタ条件を構成できます。このパラメータが構成されていない場合は、特定のテーブルのすべてのパーティションのメタデータが移行されます。
aws.partition.filter.<データベース名>.<テーブル名>=dt>=20220101
## (必須) 固定値を使用します。
mode=increment
comparePartition=true
## (必須) Alibaba Cloud アカウントの AccessKey ID と AccessKey シークレット。 Alibaba Cloud アカウントには、DLF にアクセスするために必要な権限が必要です。
aliyun.accessKeyId=xxxx
aliyun.secretAccessKey=xxxxxxx
aliyun.region=eu-central-1
aliyun.endpoint=dlf.eu-central-1.aliyuncs.com
aliyun.catalogId=xxxx (デフォルトでは、DLF カタログ ID は UID です。)
## (必須) ソースのテーブルの場所を宛先のテーブルの場所に置き換えるためのルール。複数のキーと値のペアを指定できます。
location.convertMap={"s3://xxx-eu-central-1/glue-migrate/":"oss://xxx-eu-central-1/glue-migrate/"}
## (オプション) 出力結果のストレージパス。移行ジョブの詳細な操作ログは、パスに保存されます。
result.output.path=oss://<bucket>/path1/ステップ 3: Spark ジョブを送信する
Spark 環境が構成されているシステムで Spark ジョブを送信する必要があります。 AWS または Alibaba Cloud EMR で Spark ジョブを送信できます。インターネット経由で Spark 環境にアクセスできることを確認してください。 Spark 2 で Spark ジョブを送信することをお勧めします。
この例では、Alibaba Cloud EMR クラスタのマスターノードで Spark ジョブを送信します。 Alibaba Cloud EMR クラスタを作成およびログオンする方法については、[クラスタの作成] および [クラスタへのログオン] を参照してください。次のサンプルコードは、Spark ジョブを送信する方法の例を示しています:
spark-submit --name migrate --class com.aliyun.dlf.migrator.glue.GlueToDLFApplication --deploy-mode cluster --conf spark.executor.instances=10 glue-1.0-SNAPSHOT-jar-with-dependencies.jar oss://<bucket>/path/application.properties パラメータ:
name: ジョブの名前。カスタム名を指定できます。class: 値を com.aliyun.dlf.migrator.glue.GlueToDLFApplication に設定します。deploy-mode: 値を cluster または client に設定します。spark.executor.instances: ビジネス要件に基づいてこのパラメータを構成します。インスタンス数を増やすと、ジョブの実行が高速化されます。glue-1.0-SNAPSHOT-jar-with-dependencies.jar: ステップ 1 でダウンロードした JAR パッケージ。oss://<bucket>/path/application.properties: ステップ 2 で構成ファイルがアップロードされたパス。ビジネス要件に基づいてパスを置き換えます。
ステップ 4: 結果を表示する
YARN の Web UI でジョブのドライバの stdout ログを表示します。 YARN の Web UI にアクセスする方法については、[オープンソースコンポーネントの Web UI にアクセスする] を参照してください。

ログには次の情報が含まれています。
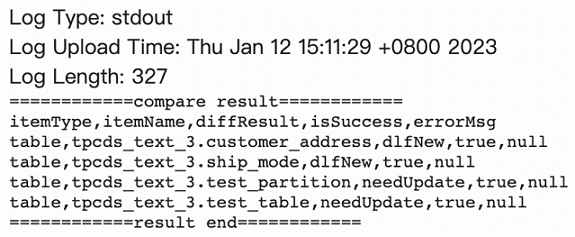
itemType: メトリックタイプ。有効な値:database、table、function、およびpartition。itemName: データベース名、テーブル名、またはパーティション名。diffResult: 差分タイプ。有効な値:dlfNew: メタデータは Alibaba Cloud DLF に存在しますが、AWS Glue には存在しません。この場合は、Alibaba Cloud DLF で削除操作を呼び出す必要があります。glueNew: メタデータは AWS Glue に存在しますが、Alibaba Cloud DLF には存在しません。この場合は、Alibaba Cloud DLF で作成操作を呼び出す必要があります。needUpdate: メタデータは AWS Glue と Alibaba Cloud DLF の両方に存在しますが、メタデータの内容が同じではありません。この場合は、更新操作を呼び出してメタデータを同期する必要があります。
isSuccess: 補正操作が成功したかどうかを示します。errorMsg: 補正操作が失敗した場合、エラーの詳細が表示されます。