cGPU は、Alibaba Cloud が提供するカーネルベースの GPU 共有テクノロジーであり、複数の隔離されたコンテナが単一の物理 GPU を共有できるようにします。cGPU は、カーネルドライバーレベルで GPU リソースを vGPU に仮想化することにより、パフォーマンスを損なうことなく、コンテナごとの GPU メモリとコンピューティング能力の隔離を強制します。これにより、ハードウェア使用率が向上し、GPU インフラストラクチャコストが削減されます。
仕組み
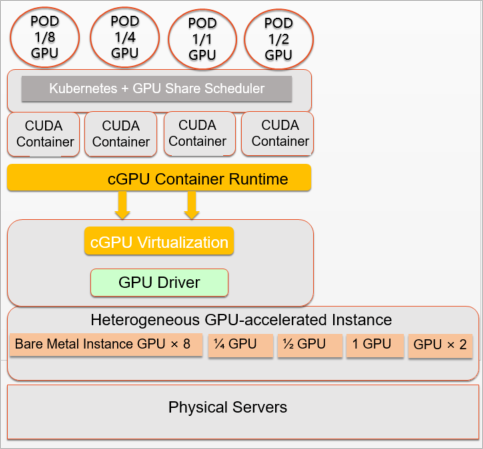
Alibaba Cloud のカーネルドライバーは、共有 GPU 上で実行されている各コンテナに対して vGPU デバイスを作成します。このドライバーは、GPU メモリとコンピューティングレイヤーで隔離を強制するため、各コンテナが互いのワークロードに干渉することはありません。これにより、単一の GPU 上で複数のトレーニングジョブや推論ジョブを同時に実行することが可能になります。
機能
隔離とリソース制御
GPU メモリの隔離: MB レベルの粒度で GPU メモリを割り当て、コンテナごとに強制します。
コンピューティング能力の隔離: コンテナごとに GPU 使用率を設定し、最小コンピューティング能力比率を 2% まで低く設定できます。
プリエンプション: 優先度の高いタスクが優先度の低いタスクに割り込むことで、サービスレベル目標 (SLO) を保証します。
互換性
AI アプリケーションを変更することなく、Docker、containerd、Kubernetes と連携して動作します。
コードの再コンパイルや Compute Unified Device Architecture (CUDA) ライブラリの置き換えは不要です。
サポートされるインスタンスタイプ
cGPU は、GPU で高速化された Elastic Compute Service (ECS) ベアメタルインスタンス、仮想化インスタンス、および GPU 仮想化インスタンスをサポートしています。仮想化
運用
ホットアップグレード: 実行中のワークロードを中断することなく、カーネルドライバーをアップグレードします。
マルチ GPU 割り当て: 単一のコンテナに複数の vGPU を割り当てます。
監視と管理: GPU のリソース使用量を追跡および管理するための高度な運用保守 (O&M) 機能を提供します。
利用シーン
オンライン/オフラインワークロードのコロケーション: 遅延の影響を受けやすいオンラインサービスとバッチオフラインジョブを同じ GPU 上で実行し、使用率を最大化します。
AI トレーニングと推論: リソース境界を保証した上で、単一の GPU 上で複数の CUDA ベースのトレーニングジョブまたは推論ジョブを隔離します。
レンダリング: マルチテナント環境において、複数のレンダリングタスク間で GPU リソースを共有します。