大規模言語モデル (LLM) の採用が増えるにつれて、推論タスク中のデータセキュリティに関する企業の懸念が高まっています。このトピックでは、Alibaba Cloud のヘテロジニアス機密コンピューティングインスタンスと Confidential AI (CAI) ソリューションを使用して、安全な LLM 推論環境を構築する方法について説明します。
背景
Alibaba Cloud gn8v-tee ヘテロジニアス機密コンピューティングインスタンスは、CPU Trust Domain Extension (TDX) に基づく信頼できる実行環境 (TEE) に GPU を統合します。これにより、CPU と GPU 間のデータ転送中および GPU 内の計算中のデータが保護されます。Alibaba Cloud Key Management Service (KMS) をキーストレージバックエンドとして使用し、Container Service for Kubernetes (ACK) クラスターに Trustee リモートアテステーションサービスをデプロイできます。簡単な構成を行うだけで、推論サービスは変更を必要とせずに、機密コンピューティングを通じて安全な推論保護をシームレスに実装できます。このソリューションは、Alibaba Cloud 上に安全な LLM 推論環境を構築し、ビジネスをサポートするのに役立ちます。
ソリューションアーキテクチャ
次の図は、ソリューションの全体的なアーキテクチャを示しています。

手順
ステップ 1: 暗号化されたモデルデータを準備する
このステップには、モデルのダウンロード、暗号化、アップロードが含まれます。モデルファイルが大きいため、プロセス全体に時間がかかります。
このソリューションを試すには、私たちが準備した暗号化されたモデルファイルを使用できます。私たちの暗号化されたモデルファイルを使用する場合、このステップをスキップしてステップ 2: Trustee リモートアテステーションサービスをセットアップするに進むことができます。次のリンクをクリックして、暗号化されたモデルファイル情報を取得してください。
1. モデルをダウンロードする
モデルをクラウドにデプロイする前に、モデルを暗号化してクラウドストレージにアップロードする必要があります。モデルの復号鍵は、リモートアテステーションサービスによって制御される KMS によって管理されます。モデルの暗号化は、ローカルまたは信頼できる環境で実行する必要があります。次の例では、Qwen2.5-3B-Instruct 大規模モデルをデプロイする方法を示します。
すでにモデルをお持ちの場合は、このセクションをスキップして2. モデルを暗号化するに進んでください。
この例では、modelscope ツールを使用して Qwen2.5-3B-Instruct モデルをダウンロードします。これには Python 3.9 以降が必要です。ターミナルで次のコマンドを実行して、モデルをダウンロードできます。
pip3 install modelscope importlib-metadata
modelscope download --model Qwen/Qwen2.5-3B-Instructコマンドが正常に実行されると、モデルは ~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/ ディレクトリにダウンロードされます。
2. モデルを暗号化する
次の 2 つの暗号化方式がサポートされています。このトピックでは、Gocryptfs を例として使用します。
Gocryptfs: オープンソースの Gocryptfs 標準に準拠した AES-256-GCM ベースの暗号化パターンです。
Sam: Alibaba Cloud の信頼できる AI モデル暗号化フォーマットです。モデルの機密性を保護し、ライセンスコンテンツが改ざんされたり、不正に使用されたりするのを防ぎます。
Gocryptfs を使用して暗号化する
モデルの暗号化に使用するツールである Gocryptfs をインストールします。現在、デフォルトパラメーターの Gocryptfs v2.4.0 のみがサポートされています。次のいずれかの方法でインストールできます。
方法 1: (推奨) yum ソースからインストールする
Alinux 3 または AnolisOS 23 オペレーティングシステムを使用している場合は、yum ソースから gocryptfs を直接インストールできます。
Alinux 3
sudo yum install gocryptfs -yAnolisOS 23
sudo yum install anolis-epao-release -y sudo yum install gocryptfs -y方法 2: プリコンパイル済みバイナリを直接ダウンロードする
# プリコンパイル済みの Gocryptfs パッケージをダウンロードします wget https://github.jobcher.com/gh/https://github.com/rfjakob/gocryptfs/releases/download/v2.4.0/gocryptfs_v2.4.0_linux-static_amd64.tar.gz # 解凍してインストールします tar xf gocryptfs_v2.4.0_linux-static_amd64.tar.gz sudo install -m 0755 ./gocryptfs /usr/local/binモデルの暗号鍵として使用する Gocryptfs キーファイルを作成します。後のステップで、このキーをリモートアテステーションサービス (Trustee) にアップロードして管理する必要があります。
このソリューションでは、
0Bn4Q1wwY9fN3Pがモデルの暗号化キーとして使用されます。キーの内容はcachefs-passwordファイルに保存されます。カスタムキーを使用することもできます。実際には、ランダムに生成された強力なキーを使用することをお勧めします。cat << EOF > ~/cachefs-password 0Bn4Q1wwY9fN3P EOF作成したキーを使用してモデルを暗号化します。
プレーンテキストモデルのパスを設定します。
説明ダウンロードしたプレーンテキストモデルが配置されているパスを設定します。他のモデルがある場合は、パスをターゲットモデルの実際のパスに置き換えてください。
PLAINTEXT_MODEL_PATH=~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/Gocryptfs を使用してモデルディレクトリツリーを暗号化します。
暗号化後、モデルは
./cipherディレクトリに暗号文として保存されます。mkdir -p ~/mount cd ~/mount mkdir -p cipher plain # Gocryptfs ランタイムの依存関係をインストールします sudo yum install -y fuse # gocryptfs を初期化します cat ~/cachefs-password | gocryptfs -init cipher # plain にマウントします cat ~/cachefs-password | gocryptfs cipher plain # AI モデルを ~/mount/plain に移動します cp -r ${PLAINTEXT_MODEL_PATH}/. ~/mount/plain
Sam を使用して暗号化する
クリックして Sam 暗号化モジュールパッケージ RAI_SAM_SDK_2.1.0-20240731.tgz をダウンロードします。次に、次のコマンドを実行してパッケージを解凍できます。
# Sam 暗号化モジュールを解凍します tar xvf RAI_SAM_SDK_2.1.0-20240731.tgzSam 暗号化モジュールを使用してモデルを暗号化します。
# Sam 暗号化モジュールの暗号化ディレクトリに移動します cd RAI_SAM_SDK_2.1.0-20240731/tools # モデルを暗号化します ./do_content_packager.sh <model_directory> <plaintext_key> <key_id>ここで、
<model_directory>: 暗号化するモデルが配置されているディレクトリです。
~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/のような相対パスまたは絶対パスを使用できます。<plaintext_key>: カスタム暗号化キーです。有効な長さは 4〜128 バイトです。例は
0Bn4Q1wwY9fN3Pです。プレーンテキストキーは、リモートアテステーションサービス (Trustee) にアップロードする必要があるモデルの復号鍵です。<key_id>: カスタムキー識別子です。有効な長さは 8〜48 バイトです。例は
LD_Demo_0001です。
暗号化後、モデルは現在のパスの
<key_id>ディレクトリに暗号文として保存されます。
3. モデルをアップロードする
ヘテロジニアスインスタンスをデプロイするのと同じリージョンに OSS バケットを準備します。暗号化されたモデルを Alibaba Cloud OSS にアップロードします。これにより、後でヘテロジニアスインスタンスからモデルをプルしてデプロイできます。
OSS を例にとると、バケットと qwen-encrypted という名前のディレクトリを作成できます。たとえば、oss://examplebucket/qwen-encrypted/ です。詳細については、「コンソールのクイックスタート」をご参照ください。モデルファイルは大きいため、ossbrowser を使用して暗号化されたモデルをこのディレクトリにアップロードすることをお勧めします。
ステップ 2: Trustee リモートアテステーションサービスをセットアップする
リモートアテステーションサービスは、モデルと推論サービスのランタイム環境の検証を担当するユーザー管理の検証サービスです。モデルの復号鍵は、サービスがヘテロジニアスモデルのデプロイ環境が信頼でき、期待される条件を満たしていることを確認した後にのみ、モデルを復号してマウントするために注入されます。
Alibaba Cloud ACK Serverless を使用して、モデルのデプロイと推論環境を検証するリモートアテステーションサービスをデプロイできます。また、Alibaba Cloud KMS を使用して、モデルの復号鍵にプロフェッショナルグレードのセキュリティを提供することもできます。手順は次のとおりです。
ACK クラスターは、ヘテロジニアスデプロイサービスのターゲットリージョンと同じリージョンにある必要はありません。
Alibaba Cloud KMS インスタンスは、Alibaba Cloud Trustee リモートアテステーションサービスがデプロイされる ACK クラスターと同じリージョンにある必要があります。
KMS インスタンスと ACK クラスターを作成する前に、VPC (仮想プライベートクラウド) と 2 つの vSwitch を作成します。詳細については、「VPC の作成と管理」をご参照ください。
1. キーストレージバックエンドとして Alibaba Cloud KMS インスタンスを作成する
Key Management Service コンソールに移動します。左側のナビゲーションウィンドウで、 を選択します。[ソフトウェアキー管理] タブで、インスタンスを作成して有効にします。インスタンスを有効にするときは、ACK クラスターと同じ VPC を選択します。詳細については、「KMS インスタンスの購入と有効化」をご参照ください。
インスタンスが起動するまで約 10 分待ちます。
インスタンスが起動したら、左側のナビゲーションウィンドウで を選択します。[キー管理] ページで、インスタンスのカスタマーマスターキーを作成します。詳細については、「ステップ 1: ソフトウェアで保護されたキーを作成する」をご参照ください。
左側のナビゲーションウィンドウで、 を選択します。[アクセスポイント] ページで、インスタンスのアプリケーションアクセスポイントを作成します。[スコープ] を作成した KMS インスタンスに設定します。その他の設定については、「方法 1: クイック作成」をご参照ください。
アプリケーションアクセスポイントが作成されると、ブラウザは自動的に ClientKey***.zip ファイルをダウンロードします。zip ファイルを解凍すると、次のものが含まれます。
アプリケーション ID 資格情報コンテンツ (ClientKeyContent): ファイル名はデフォルトで
clientKey_****.jsonです。資格情報セキュリティトークン (ClientKeyPassword): ファイル名はデフォルトで
clientKey_****_Password.txtです。
ページで、KMS インスタンス名をクリックします。[基本情報] エリアで、[インスタンス CA 証明書] の横にある [ダウンロード] をクリックして、KMS インスタンスの公開鍵証明書ファイル
PrivateKmsCA_***.pemをエクスポートします。
2. ACK サービスクラスターを作成し、csi-provisioner コンポーネントをインストールする
クラスターの作成ページに移動して、ACK Serverless クラスターを作成します。主要なパラメーター設定を以下に示します。その他の設定については、「クラスターの作成」をご参照ください。
クラスター設定: 次のパラメーターを設定し、[次へ: コンポーネント設定] をクリックします。
主要な設定
説明
VPC
[既存の VPC を使用] を選択し、[VPC の SNAT を設定] を選択します。そうしないと、Trustee イメージをプルできません。
VSwitch
既存の VPC に少なくとも 2 つの vSwitch が作成されていることを確認してください。そうしないと、パブリック ALB を公開できません。
コンポーネント設定: 次のパラメーターを設定し、[次へ: 注文の確認] をクリックします。
主要な設定
説明
サービスディスカバリ
[CoreDNS] を選択します。
Ingress
[ALB Ingress] を選択します。ALB クラウドネイティブゲートウェイインスタンスのソースについては、[作成] を選択し、2 つの vSwitch を選択します。
注文の確認: 設定情報と利用規約を確認し、[クラスターの作成] をクリックします。
クラスターが作成されたら、csi-provisioner (マネージド) コンポーネントをインストールします。詳細については、「コンポーネントの管理」をご参照ください。
3. ACK クラスターに Trustee リモートアテステーションサービスをデプロイする
まず、インターネットまたは内部ネットワーク経由でクラスターに接続します。詳細については、「クラスターへの接続」をご参照ください。
ダウンロードしたアプリケーション ID 資格情報 (
clientKey_****.json)、資格情報セキュリティトークン (clientKey_****_Password.txt)、および KMS インスタンスの CA 証明書 (PrivateKmsCA_***.pem) を ACK Serverless クラスターに接続されている環境にアップロードします。次に、次のコマンドを実行して Trustee リモートアテステーションサービスをデプロイし、Alibaba Cloud KMS をキーストレージバックエンドとして使用します。# プラグインをインストールします helm plugin install https://github.com/AliyunContainerService/helm-acr helm repo add trustee acr://trustee-chart.cn-hangzhou.cr.aliyuncs.com/trustee/trustee helm repo update export DEPLOY_RELEASE_NAME=trustee export DEPLOY_NAMESPACE=default export TRUSTEE_CHART_VERSION=1.0.0 # ACK クラスターのリージョン情報を設定します。例: cn-hangzhou export REGION_ID=cn-hangzhou # エクスポートされた KMS インスタンスに関する情報 # KMS インスタンス ID に置き換えます export KMS_INSTANCE_ID=kst-hzz66a0*******e16pckc # KMS インスタンスアプリケーション ID 資格情報へのパスに置き換えます export KMS_CLIENT_KEY_FILE=/path/to/clientKey_KAAP.***.json # KMS インスタンス資格情報セキュリティトークンへのパスに置き換えます export KMS_PASSWORD_FILE=/path/to/clientKey_KAAP.***_Password.txt # KMS インスタンス CA 証明書へのパスに置き換えます export KMS_CERT_FILE=/path/to/PrivateKmsCA_kst-***.pem helm install ${DEPLOY_RELEASE_NAME} trustee/trustee \ --version ${TRUSTEE_CHART_VERSION} \ --set regionId=${REGION_ID} \ --set kbs.aliyunKms.enabled=true \ --set kbs.aliyunKms.kmsIntanceId=${KMS_INSTANCE_ID} \ --set-file kbs.aliyunKms.clientKey=${KMS_CLIENT_KEY_FILE} \ --set-file kbs.aliyunKms.password=${KMS_PASSWORD_FILE} \ --set-file kbs.aliyunKms.certPem=${KMS_CERT_FILE} \ --namespace ${DEPLOY_NAMESPACE}説明プラグインをインストールする最初のコマンド (
helm plugin install...) は時間がかかる場合があります。インストールに失敗した場合は、helm plugin uninstall cm-pushコマンドを実行してプラグインをアンインストールし、再度インストールコマンドを実行してください。返される結果の例を次に示します。
NAME: trustee LAST DEPLOYED: Tue Feb 25 18:55:33 2025 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: NoneACK Serverless クラスターに接続されている環境で次のコマンドを実行して、Trustee のエンドポイントを取得します。
export TRUSTEE_URL=http://$(kubectl get AlbConfig alb -o jsonpath='{.status.loadBalancer.dnsname}')/${DEPLOY_RELEASE_NAME} echo ${TRUSTEE_URL}返される結果の例は
http://alb-ppams74szbwg2f****.cn-shanghai.alb.aliyuncsslb.com/trusteeです。ACK Serverless クラスターに接続されている環境で次のコマンドを実行して、Trustee サービスの接続性をテストします。
cat << EOF | curl -k -X POST ${TRUSTEE_URL}/kbs/v0/auth -H 'Content-Type: application/json' -d @- { "version":"0.1.0", "tee": "tdx", "extra-params": "foo" } EOFTrustee サービスが正常に実行されている場合、期待される出力は次のとおりです。
{"nonce":"PIDUjUxQdBMIXz***********IEysXFfUKgSwk=","extra-params":""}
4. モデルの復号鍵を保存するためのシークレットを作成する
Trustee によって管理されるモデルの復号鍵は KMS に保存されます。キーには、リモートアテステーションサービスがターゲット環境を検証した後にのみアクセスできます。
Key Management Service コンソールに移動します。左側のナビゲーションウィンドウで、 を選択します。[汎用シークレット] タブで、[汎用シークレットの作成] をクリックします。次の主要な設定に注意してください。
シークレット名: シークレットのカスタム名を入力します。この名前はキーのインデックスとして使用されます。たとえば、
model-decryption-keyです。シークレット値の設定: モデルの暗号化に使用したキーを入力します。たとえば、
0Bn4Q1wwY9fN3Pです。実際のキーを使用してください。暗号化 CMK: 前のステップで作成したマスターキーを選択します。
ステップ 3: ヘテロジニアス機密コンピューティングインスタンスを作成する
コンソールでヘテロジニアス機密コンピューティング機能を備えたインスタンスを作成する手順は、通常のインスタンスを作成する手順と似ていますが、いくつかの特定のオプションに注意する必要があります。次の手順では、ヘテロジニアス機密コンピューティング環境と CAI 環境を含む Alibaba Cloud Marketplace のイメージを使用して、ヘテロジニアス機密コンピューティングインスタンスを作成する方法について説明します。ヘテロジニアス機密コンピューティング環境の詳細については、「ヘテロジニアス機密コンピューティング環境の構築」をご参照ください。
インスタンス購入ページに移動します。
[カスタム起動] タブを選択します。
課金方法、リージョン、インスタンスタイプ、イメージ、およびその他の設定を選択します。
次の表に設定項目を示します。
設定項目
説明
インスタンスファミリー
gn8v-tee インスタンスファミリーから次の 2 つのインスタンスタイプのいずれかを選択する必要があります。
ecs.gn8v-tee.4xlarge
ecs.gn8v-tee.6xlarge
イメージ
[Marketplace イメージ] タブをクリックし、
Confidential AIと入力して検索し、Alibaba Cloud Linux 3.2104 LTS 64 ビットシングルカード Confidential AIイメージを選択します。説明このイメージの詳細については、「Alibaba Cloud Linux 3.2104 LTS 64 ビットシングルカード Confidential AI イメージ」をご参照ください。イメージ製品ページでヘテロジニアス機密コンピューティングインスタンスを作成できます。
システムディスク
システムディスク容量は 1 TiB 以上を推奨します。具体的なサイズは、実行する必要のあるモデルファイルのサイズに基づいて合理的に見積もる必要があります。一般的に、モデルサイズの 2 倍以上の容量を推奨します。必要に応じて容量を設定してください。
インスタンスを作成する前に、ページ右側の全体的な設定を確認してください。使用期間などのオプションを設定して、要件を満たしていることを確認してください。
チェックボックスを読んで選択し、ECS 利用規約およびその他のサービス契約に同意します。すでに同意している場合は、この手順を再度実行する必要はありません。ページのプロンプトに従ってください。次に、[注文の作成] をクリックします。
インスタンスが作成されるのを待ちます。コンソールのインスタンスリストページに移動して、インスタンスのステータスを表示できます。インスタンスのステータスが [実行中] に変わると、インスタンスが作成されます。
ステップ 4: ヘテロジニアスインスタンスの OSS および Trustee へのアクセス権限を設定する
1. OSS へのアクセス権限を設定する
デプロイ中、インスタンスはモデルの暗号文を保存する OSS バケットにアクセスし、Trustee にアクセスしてモデルの復号鍵を取得する必要があります。したがって、インスタンスの OSS および Trustee サービスへのアクセス権限を設定する必要があります。
OSS コンソールにログオンします。
[バケット] をクリックし、ターゲットバケット名をクリックします。
左側のナビゲーションウィンドウで、 を選択します。
[バケットポリシー] タブで、[承認] をクリックします。表示されるパネルで、ヘテロジニアス機密コンピューティングインスタンスのパブリック IP アドレスに
Bucket権限を付与します。[OK] をクリックします。
2. Trustee へのアクセス権限を設定する
Application Load Balancer (ALB) コンソールに移動し、左側の [アクセス制御] を選択します。次に [ACL の作成] をクリックし、Trustee にアクセスする必要がある IP アドレスまたは CIDR ブロックを IP エントリとして追加します。詳細については、「アクセス制御」をご参照ください。
次のアドレスまたはアドレス範囲を追加する必要があります。
ヘテロジニアスサービスデプロイ中にバインドされた VPC のパブリック IP アドレス。
推論クライアントの出口 IP アドレス。
次のコマンドを実行して、クラスター上の Trustee インスタンスが使用する ALB インスタンスの ID を取得します。
kubectl get ing --namespace ${DEPLOY_NAMESPACE} kbs-ingress -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | cut -d'.' -f1 | sed 's/[^a-zA-Z0-9-]//g'期待される出力は次のとおりです。
alb-llcdzbw0qivhk0****ALB コンソールの左側のナビゲーションウィンドウで、 を選択します。クラスターが配置されているリージョンで、前のステップで取得した ALB インスタンスを検索し、インスタンス ID をクリックしてインスタンスの詳細ページに移動します。ページの下部にある [インスタンス情報] エリアで、[設定読み取り専用モードを無効にする] をクリックします。
[リスナー] タブに切り替え、ターゲットリスナーインスタンスの [アクセス制御] 列で [有効] をクリックし、前のステップで作成したアクセス制御ポリシーグループでホワイトリストを設定します。
ステップ 5: ヘテロジニアス機密コンピューティングインスタンスに vLLM 大規模言語モデル推論サービスをデプロイする
ヘテロジニアス機密コンピューティングインスタンスに vLLM 大規模言語モデル推論サービスを docker または docker compose を使用してデプロイできます。手順は次のとおりです。
1. 設定ファイルを準備する
ヘテロジニアスインスタンスにリモート接続します。詳細については、「Workbench を使用して Linux インスタンスにログオンする」をご参照ください。
次のコマンドを実行して
~/cai.env設定ファイルを開きます。vi ~/cai.enviキーを押して挿入モードに入り、準備した設定情報をファイルに貼り付けます。# モデル復号のための設定 TRUSTEE_URL="http://alb-xxxxxxxxx.cn-beijing.alb.aliyuncsslb.com/xxxx/" # Trustee サービス の URL MODEL_KEY_ID="kbs:///default/aliyun/model-decryption-key" # Trustee で設定されたモデル復号鍵のリソース ID。たとえば、model-decryption-key という名前のシークレットの ID は kbs:///default/aliyun/model-decryption-key です # 暗号化モデル配布のための設定 MODEL_OSS_BUCKET_PATH="<bucket-name>:<model-path>" # Alibaba Cloud OSS に保存されているモデル暗号文のパス。たとえば、conf-ai:/qwen3-32b-gocryptfs/ MODEL_OSS_ENDPOINT="https://oss-cn-beijing-internal.aliyuncs.com" # モデル暗号文が保存されている OSS の URL # MODEL_OSS_ACCESS_KEY_ID="" # OSS バケットへのアクセスに使用する AccessKey ID。 # MODEL_OSS_SECRET_ACCESS_KEY="" # OSS バケットへのアクセスに使用する AccessKey シークレット。 # MODEL_OSS_SESSION_TOKEN="" # OSS バケットへのアクセスに使用するセッショントークン。これは STS 資格情報を使用して OSS にアクセスする場合にのみ必要です。 MODEL_ENCRYPTION_METHOD="gocryptfs" # 使用される暗号化方式。有効な値: "gocryptfs" および "sam"。デフォルト値: "gocryptfs"。 MODEL_MOUNT_POINT=/tmp/model # 復号されたモデルプレーンテキストのマウントポイント。モデル推論サービスはこのパスからモデルをロードできます。 # 大規模モデルサービス通信暗号化のための設定 MODEL_SERVICE_PORT=8080 # サービスが使用する TCP ポート。このポートでの通信は透過的に暗号化されます。 # P2P モデル配布高速化のための設定。デフォルトでは無視できます。 TRUSTEE_POLICY="default" # MODEL_SHARING_PEER="172.30.24.146 172.30.24.144":wqと入力し、Enterを押してファイルを保存し、エディターを終了します。
2. 推論サービスをデプロイする
docker を使用して推論サービスをデプロイする
設定ファイルを使用して CAI サービスを開始する
前のステップで設定したファイルを使用して CAI サービスを開始する必要があります。これは暗号化されたモデルを復号するために使用されます。これにより、復号されたプレーンテキストのモデルデータが、ホスト環境の
MODEL_MOUNT_POINTで指定された/tmp/modelパスにマウントされます。vLLM などの推論サービスプログラムは、このパスからモデルをロードできます。次のコマンドを実行して CAI サービスを開始します。
cd ~ docker compose -f /opt/alibaba/cai-docker/docker-compose.yml --env-file ./cai.env up -d --wait次のサンプル出力は、CAI サービスが正常に開始されたことを示しています。
[+] Running 5/5 ✔ Container cai-docker-oss-1 Healthy 44.7s ✔ Container cai-docker-attestation-agent-1 Healthy 44.7s ✔ Container cai-docker-tng-1 Healthy 44.7s ✔ Container cai-docker-confidential-data-hub-1 Healthy 44.7s ✔ Container cai-docker-cachefs-1 Healthy復号されたモデルファイルを表示する
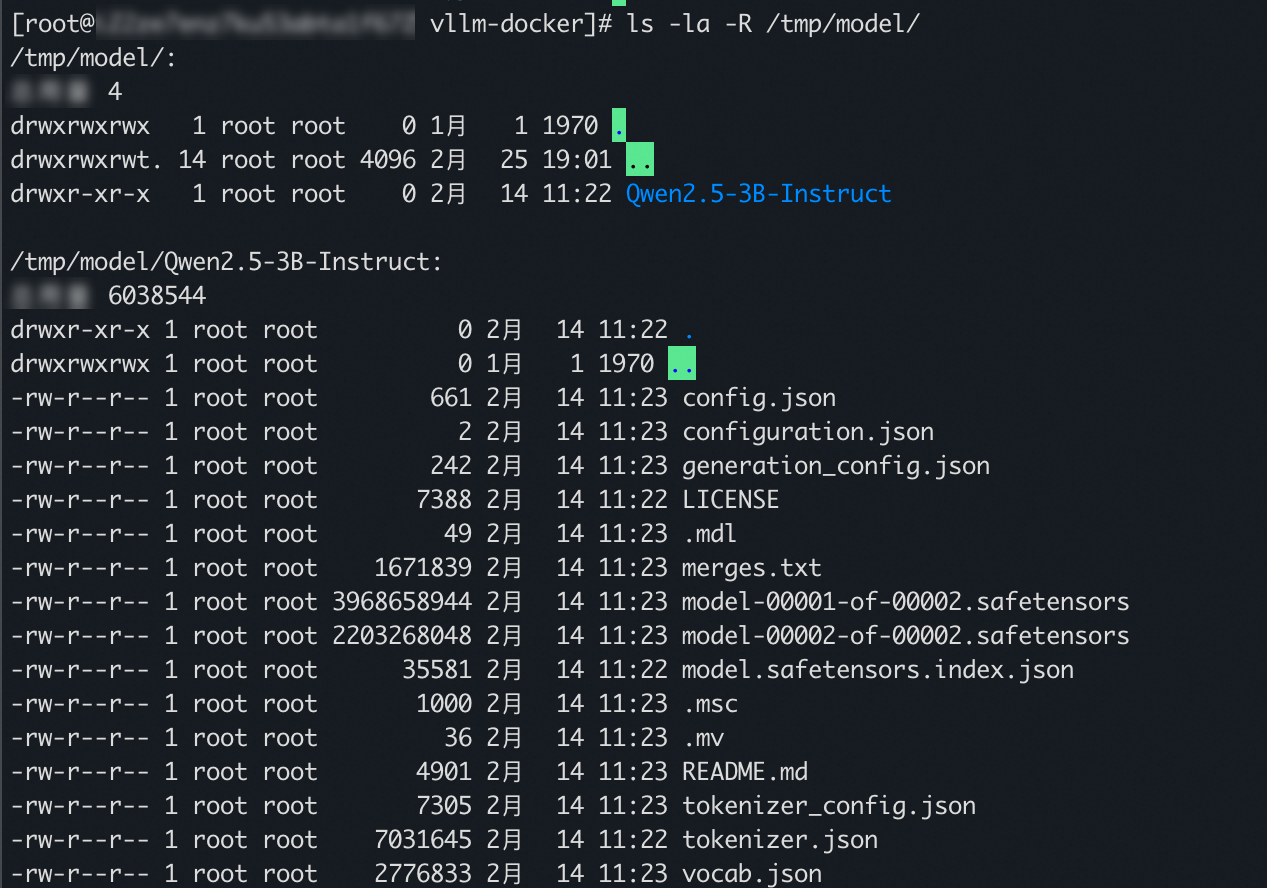
復号されたモデルファイルを表示するには、次のコマンドを実行します。
ls -la -R /tmp/model次のサンプル出力は、モデルファイルが正常に復号されたことを示しています。
次のコマンドを実行して vLLM 推論サービスを開始します。
docker run --rm \ --net host \ -v /tmp/model:/tmp/model \ --gpus all \ egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.8.5-pytorch2.6-cu124-20250429 \ python3 -m vllm.entrypoints.openai.api_server --model=/tmp/model --trust-remote-code --port 8080 --served-model-name Qwen3-32B次のサンプル出力は、推論サービスが正常に開始されたことを示しています。
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s] Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:01<00:01, 1.07s/it] Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.21it/s] Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.16it/s] INFO 03-04 07:49:06 model_runner.py:732] Loading model weights took 5.7915 GB INFO 03-04 07:49:08 gpu_executor.py:102] # GPU blocks: 139032, # CPU blocks: 7281 INFO 03-04 07:49:08 model_runner.py:1024] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. INFO 03-04 07:49:08 model_runner.py:1028] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage. INFO 03-04 07:49:18 model_runner.py:1225] Graph capturing finished in 9 secs. WARNING 03-04 07:49:18 serving_embedding.py:171] embedding_mode is False. Embedding API will not work. INFO 03-04 07:49:18 launcher.py:14] Available routes are: INFO 03-04 07:49:18 launcher.py:22] Route: /openapi.json, Methods: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Route: /docs, Methods: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Route: /docs/oauth2-redirect, Methods: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Route: /redoc, Methods: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Route: /health, Methods: GET INFO 03-04 07:49:18 launcher.py:22] Route: /tokenize, Methods: POST INFO 03-04 07:49:18 launcher.py:22] Route: /detokenize, Methods: POST INFO 03-04 07:49:18 launcher.py:22] Route: /v1/models, Methods: GET INFO 03-04 07:49:18 launcher.py:22] Route: /version, Methods: GET INFO 03-04 07:49:18 launcher.py:22] Route: /v1/chat/completions, Methods: POST INFO 03-04 07:49:18 launcher.py:22] Route: /v1/completions, Methods: POST INFO 03-04 07:49:18 launcher.py:22] Route: /v1/embeddings, Methods: POST INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
docker compose を使用して推論サービスをデプロイする
docker-compose.yml ファイルを準備します。
次のコマンドを実行して docker-compose.yml ファイルを開きます。
vi ~/docker-compose.ymliキーを押して挿入モードに入り、次の内容を docker-compose.yml ファイルに貼り付けます。include the following: - path: /opt/alibaba/cai-docker/docker-compose.yml env_file: ./cai.env services: inference: image: egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/llm-inference:vllm0.5.4-deepgpu-llm24.7-pytorch2.4.0-cuda12.4-ubuntu22.04 volumes: - /tmp/model:/tmp/model:shared deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: [gpu] network_mode: host init: true command: "python3 -m vllm.entrypoints.openai.api_server --model=/tmp/model/ --trust-remote-code --port 8080" depends_on: cachefs: condition: service_healthy restart: true:wqを押し、次にEnterを押してファイルを保存し、エディターを終了します。重要このトピックで説明されている他のワークロードをデプロイするために docker-compose.yml ファイルを変更する場合は、次の調整を行う必要があります。
includeステートメントを使用して、イメージにプリインストールされている CAI docker-compose.yml ファイルをインポートし、env_fileを使用して CAI 設定ファイルのパスを指定します。vLLM サービスコンテナーが cachefs コンテナーの後に開始されるように、
depends_on条件を追加する必要があります。復号されたモデルディレクトリは、ホスト環境の
MODEL_MOUNT_POINTで指定されたパスにマウントされます。したがって、モデルディレクトリを推論サービスコンテナーと共有するために、vLLM サービスコンテナーに対応する volumes エントリを追加する必要があります。
vLLM 推論サービスを実行する
次のコマンドを実行して vLLM 推論サービスを実行します。
docker compose up -d次のサンプル出力は、推論サービスが正常に開始されたことを示しています。
[+] Running 6/6 ✔ Container root-attestation-agent-1 Healthy 3.6s ✔ Container root-oss-1 Healthy 10.2s ✔ Container root-tng-1 Healthy 44.2s ✔ Container root-confidential-data-hub-1 Healthy 34.2s ✔ Container root-cachefs-1 Healthy 54.7s ✔ Container root-inference-1 Started
ステップ 6: ヘテロジニアス機密コンピューティングインスタンスの推論サービスにアクセスする
機密コンピューティングインスタンスの推論サービスにアクセスするには、クライアント環境を準備し、Trusted Network Gateway クライアントをインストールする必要があります。次の手順では、通常の ECS インスタンスをクライアントとして使用して、ヘテロジニアスインスタンスにデプロイされた vLLM 推論サービスにアクセスする方法について説明します。
1. クライアント環境からヘテロジニアス機密コンピューティングインスタンスおよび Trustee へのアクセス権限を設定する
このトピックでは、クライアント環境はパブリック IP アドレスを介してヘテロジニアス機密コンピューティングインスタンスにデプロイされた推論サービスにアクセスします。したがって、クライアント環境からのアクセスを許可するために、ヘテロジニアス機密コンピューティングインスタンスのセキュリティグループにルールを追加する必要があります。さらに、サーバーとのセキュアチャネルを確立するプロセス中に、ヘテロジニアス機密コンピューティングインスタンスのリモートアテステーションのために Trustee が必要です。したがって、クライアント環境のパブリック IP アドレスを Trustee のアクセス制御リストに追加する必要もあります。手順は次のとおりです。
クライアントからのアクセスを許可するために、ヘテロジニアス機密コンピューティングインスタンスのセキュリティグループにルールを追加します。詳細については、「セキュリティグループルールの管理」をご参照ください。
クライアント環境のパブリック IP アドレスを Trustee のアクセス制御に追加します。
ステップ 4: ヘテロジニアスインスタンスの OSS および Trustee へのアクセス権限を設定するで、すでにアクセス制御ポリシーグループを作成し、ホワイトリストに追加しています。したがって、新しいものを作成する必要はありません。既存のアクセス制御ポリシーグループにクライアントのパブリック IP アドレスを追加できます。
2. クライアントインスタンスに Trusted Network Gateway クライアントをデプロイする
Trusted Network Gateway (TNG) は、機密コンピューティングシナリオ向けに設計されたネットワークコンポーネントです。デーモンプロセスとして機能し、セキュアな通信チャネルの確立、および機密インスタンスとの間のネットワークトラフィックの透過的な暗号化と復号を担当し、エンドツーエンドのデータセキュリティを実現します。また、既存のアプリケーションを変更することなく、ニーズに応じてトラフィックの暗号化と復号のプロセスを柔軟に制御できます。
Trusted Network Gateway クライアントをデプロイします。
docker を使用してデプロイする
クライアントインスタンスに Docker をインストールします。詳細については、「Docker と Docker Compose のインストールと使用」をご参照ください。
次のコマンドを実行して、Docker を使用して Trusted Network Gateway クライアントをデプロイします。
重要as_addrフィールドの値を、以前にデプロイした Trustee サービスに基づいて${trsutee_url}/as/に変更する必要があります。docker run --rm \ --network=host \ confidential-ai-registry.cn-shanghai.cr.aliyuncs.com/product/tng:2.2.1 \ tng launch --config-content ' { "add_ingress": [ { "http_proxy": { "proxy_listen": { "host": "127.0.0.1", "port": 41000 } }, "verify": { "as_addr": "http://alb-xxxxxxxxxxxxxxxxxx.cn-shanghai.alb.aliyuncsslb.com/cai-test/as/", "policy_ids": [ "default" ] } } ] } '
バイナリファイルを使用してデプロイする
TNG · GitHub にアクセスして、クライアントインスタンスアーキテクチャに一致するバイナリインストールパッケージのダウンロードアドレスを取得します。
次のコマンドを実行して、Trusted Network Gateway クライアントのバイナリファイルをダウンロードします。次の例では
tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gzを使用しています。実際のファイル名に置き換えてください。wget https://github.com/inclavare-containers/TNG/releases/download/v2.2.1/tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gz次のコマンドを実行して、ダウンロードしたバイナリ圧縮ファイルを解凍し、ファイルに実行権限を付与します。
tar -zxvf tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gz chmod +x tng次のコマンドを実行して、Trusted Network Gateway クライアントを実行します。
重要as_addrフィールドの値を、以前にデプロイした Trustee サービスに基づいて${trsutee_url}/as/に変更する必要があります。./tng launch --config-content ' { "add_ingress": [ { "http_proxy": { "proxy_listen": { "host": "127.0.0.1", "port": 41000 } }, "verify": { "as_addr": "http://alb-xxxxxxxxxxxxxxxxxx.cn-shanghai.alb.aliyuncsslb.com/cai-test/as/", "policy_ids": [ "default" ] } } ] } '
3. クライアントインスタンス上のプロセスの HTTP プロキシサービスを設定する
デプロイが成功すると、Trusted Network Gateway クライアントはフォアグラウンドで実行され、127.0.0.1:41000 上に HTTP CONNECT プロトコルに基づく HTTP プロキシサービスを作成します。アプリケーションをこのプロキシに接続すると、トラフィックは Trusted Network Gateway クライアントによって暗号化され、信頼できるチャネルを介して vLLM サービスに送信されます。
クライアントインスタンス上のプロセスの HTTP プロキシサービスは、次の 2 つの方法で設定できます。
プロトコルタイプ別にプロキシを設定する
export http_proxy=http://127.0.0.1:41000
export https_proxy=http://127.0.0.1:41000
export ftp_proxy=http://127.0.0.1:41000
export rsync_proxy=http://127.0.0.1:41000すべてのプロトコルにプロキシを設定する
export all_proxy=http://127.0.0.1:410004. クライアントインスタンスから推論サービスにアクセスする
クライアント環境で curl コマンドを実行することで、ヘテロジニアス機密コンピューティングインスタンスの推論サービスにアクセスできます。
クライアントインスタンスの新しいターミナルウィンドウを開きます。
次のコマンドを実行して推論サービスにアクセスします。
説明次のコマンドの
<heterogeneous_confidential_computing_instance_public_IP>を、ステップ 3: ヘテロジニアス機密コンピューティングインスタンスを作成するで作成したヘテロジニアス機密コンピューティングインスタンスのパブリック IP アドレスに置き換える必要があります。次のコマンドは、
curlコマンドが実行される前にall_proxy='http://127.0.0.1:41000/'環境変数を設定します。これにより、curlコマンドによって送信されるリクエストが Trusted Network Gateway クライアントによって暗号化され、セキュアチャネルを介して送信されることが保証されます。
env all_proxy='http://127.0.0.1:41000/' \ curl http://<heterogeneous_confidential_computing_instance_public_IP>:8080/v1/completions \ -X POST \ -H "Content-Type: application/json" \ -d '{"model": "Qwen3-32B", "prompt": "Do you know the book Traction by Gino Wickman", "temperature": 0.0, "best_of": 1, "max_tokens": 132, "stream": false}'次のサンプル出力は、curl コマンドを使用してクライアントから送信されたリクエストが Trusted Network Gateway クライアントによって暗号化され、セキュアチャネルを介して送信されたことを示しています。ヘテロジニアスインスタンスにデプロイされた大規模言語モデルサービスに正常にアクセスできました。

よくある質問
CAI サービスの起動中に cai-docker-oss コンテナーが起動に失敗します。
症状: CAI サービスの起動時に cai-docker-oss コンテナーが起動に失敗します。

原因: この問題は通常、ヘテロジニアスインスタンスがモデルの暗号文が保存されている OSS バケットにアクセスできないために発生します。
解決策: OSS アクセス制御ポリシーが正しく設定されているかどうかを確認してください。
CAI サービスを開始すると、cai-docker-confidential-data-hub コンテナーが起動に失敗します。
症状: CAI サービスの起動時に cai-docker-confidential-data-hub コンテナーが起動に失敗します。

原因: このエラーは、モデルの復号鍵の取得に問題があることを示します。この問題は通常、ヘテロジニアスインスタンスが Trustee インスタンスにアクセスできないか、設定されたキーが存在しないために発生します。
解決策: 次の手順を実行して問題をトラブルシューティングできます。
cai.envで設定したキー ID が正しいかどうかを確認し、サービスを再デプロイします。cai.envの Trustee インスタンスの URL が正しく設定されているかどうかを確認します。Trustee インスタンスのアクセス制御ポリシーが正しく設定されているかどうかを確認します。
CAI サービスを開始すると、cai-docker-tng コンテナーが起動に失敗します。
CAI サービスの起動中に cai-docker-cachefs コンテナーが起動に失敗しました。
症状: CAI サービスの起動時に cai-docker-cachefs コンテナーが起動に失敗します。

原因: この問題は通常、モデルの復号に失敗したために発生します。
解決策: 次の手順を実行して問題をトラブルシューティングできます。
正しいパスワード資格情報が Trustee の KMS バックエンドにアップロードされているかどうかを確認します。
cai.envで設定されているMODEL_ENCRYPTION_METHODフィールドの値が、モデルの暗号化に使用された暗号化方式と一致しているかどうかを確認します。
CAI サービスが起動に失敗した後、ツールを使用してエラー情報を収集するにはどうすればよいですか?
関連ドキュメント
ヘテロジニアス機密コンピューティング環境の構築方法の詳細については、「ヘテロジニアス機密コンピューティング環境の構築」をご参照ください。