Enterprise Distributed Application Service (EDAS) でマイクロサービスを実行する場合、ツールを切り替えることなくアノマリーを検出できるように、リクエスト数、レイテンシー、GC負荷、インフラストラクチャ利用率を表示する単一のページが必要です。EDASコンソールのアプリケーション概要ページは、これらのメトリックを前週比および前日比の比較とともに統合し、リグレッションを特定し、アプリケーションレベルの症状とシステムレベルの原因を関連付けるのに役立ちます。
アプリケーション概要ページへの移動
EDAS コンソールにログインします。
左側のナビゲーションウィンドウで、[アプリケーション管理] > [アプリケーション] を選択します。
[アプリケーション] ページで、トップナビゲーションバーからリージョンを選択します。[マイクロサービス名前空間] のドロップダウンリストから、マイクロサービス名前空間を選択します。[クラスタータイプ] のドロップダウンリストから、[ECS クラスター] を選択します。管理するアプリケーションの名前をクリックします。
左側のナビゲーションウィンドウで、[アプリケーションモニタリング] > [アプリケーション概要] を選択します。
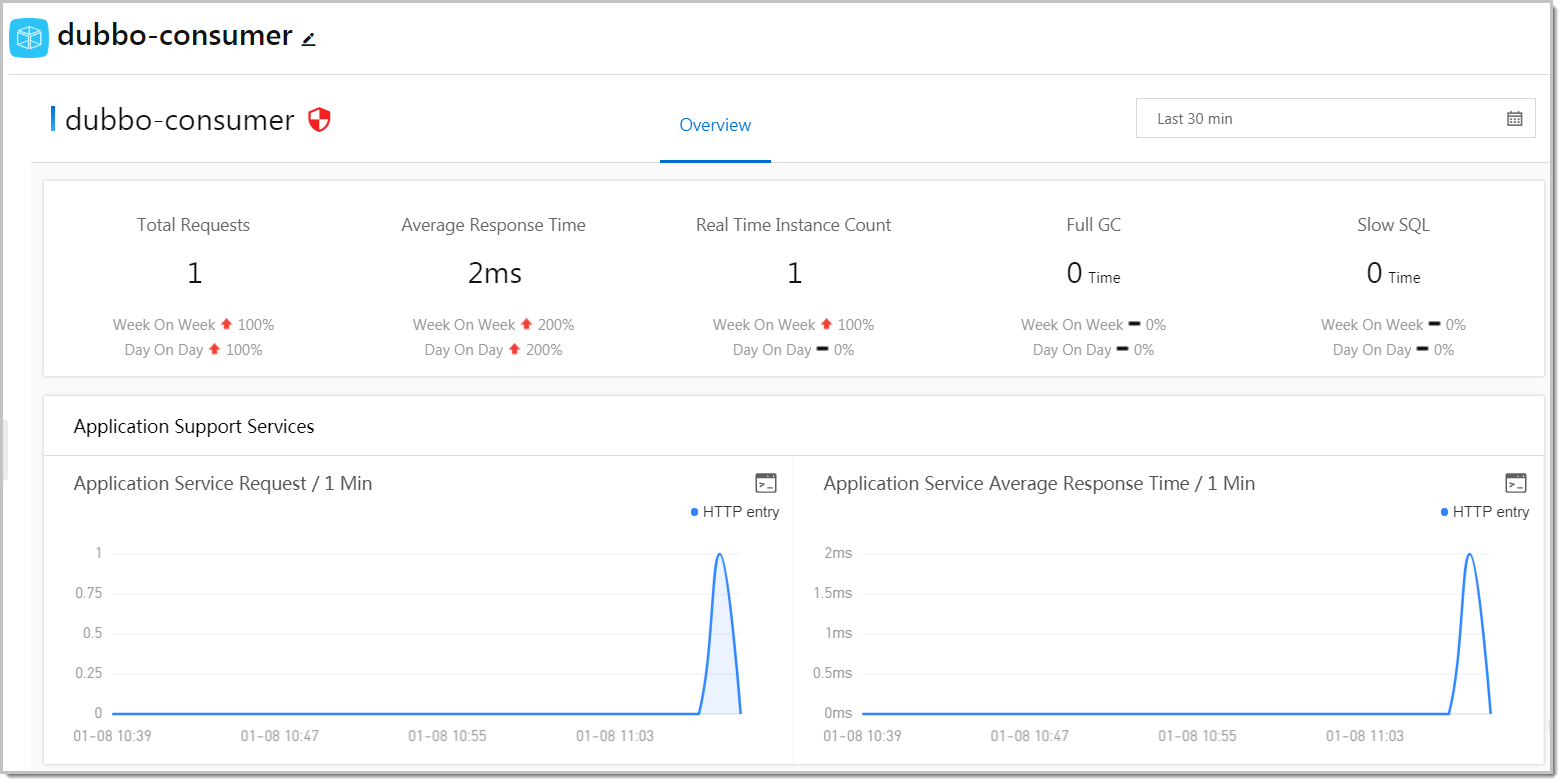
サマリーメトリック
5つのインジケーターが、[概要] タブの上部に表示されます。各インジケーターには、週次および日次での変化率が含まれており、予期されるトラフィックパターンと予期しない異常を区別できます。
| メトリック | 説明 | 調査すべき点 |
|---|---|---|
| 総リクエスト数 | 選択した時間範囲におけるインバウンドリクエストの総数。 | 急増はトラフィックの急増を示している可能性があります。急減はアップストリームの障害またはルーティングの問題を示している可能性があります。 |
| 平均応答時間 | すべてのリクエストにわたる平均レイテンシー。 | レイテンシーの上昇は、リソース競合または遅いダウンストリーム呼び出しを示唆していることがよくあります。CPU使用率および依存サービスの応答時間と比較してください。 |
| リアルタイムインスタンス | 実行中のアプリケーションインスタンス数。 | 予想されるキャパシティと比較してください。予想よりも少ない数は、応答時間の増加を説明する可能性があります。 |
| フルGC | フルGCの回数。 | 頻繁なフルGCはメモリ負荷を示し、レイテンシーの急増を引き起こす可能性があります。[System Info] のメモリ使用量と関連付けてください。 |
| スローSQLクエリ | スロークエリのしきい値を超過するデータベースクエリの数。 | 高い数はデータベースレベルのボトルネックを示唆しています。クエリプランとインデックスを確認してください。 |
繰り返されるパターン (週ごとのトラフィックピークなど) を新しい問題から区別するために、前週比および前日比の変化率を比較します。週ごとに安定しているが前日比で劣化しているメトリックは、最近のデプロイメントを示している可能性があります。
サービスレベルメトリックの調査
「[概要]」タブでは、アプリケーションが提供するサービスおよび依存するサービスの両方について、時系列グラフが表示されます。これらのグラフを使用して、パフォーマンスの問題がアプリケーションから発生しているのか、それとも下流依存関係から発生しているのかを絞り込むことができます。
アプリケーションサポートサービス
アプリケーションがアップストリームの呼び出し元に公開するサービスの時系列曲線:
| チャート | 説明 | 使用するタイミング |
|---|---|---|
| リクエスト数 | 時間の経過に伴うインバウンド呼び出し数。 | サービス全体でのトラフィックスパイク、急減、またはリクエストディストリビューションの変化を特定します。 |
| 平均応答時間 | アプリケーションが呼び出し元に返す応答のレイテンシー。 | ここでの劣化は、アップストリームのコンシューマーに直接影響します。応答時間が増加し、リクエスト数が横ばいの場合は、依存サービスまたはシステムリソースを確認してください。 |
アプリケーション依存サービス
アプリケーションが呼び出すサービスの時系列曲線:
| チャート | 説明 | 使用するタイミング |
|---|---|---|
| リクエスト数 | 下流サービスへのアウトバウンド呼び出し数。 | アプリケーションから最も多くのトラフィックを受信する下流サービスを特定します。 |
| 平均応答時間 | 下流呼び出しのレイテンシー。 | ここでの急増は、サマリーメトリックにおける応答時間の増加を説明することがよくあります。 |
| アプリケーション インスタンス | 時間の経過に伴うインスタンス数。 | インスタンススケーリングイベントとパフォーマンスの変化を関連付けます。下流インスタンスの減少は、レイテンシーの増加を引き起こす可能性があります。 |
| HTTPステータスコード | 依存サービスからの応答コードのディストリビューション。 | 下流障害の指標として、4xx (クライアントエラー) または 5xx (サーバーエラー) の増加に注意してください。 |
システムリソースの監視
[System Info] セクションには、インフラストラクチャレベルの時系列曲線が表示されます。これらのメトリックを上記のアプリケーションレベルのチャートと併用して、パフォーマンスの問題がコードレベルの問題またはリソース制約によって引き起こされているかどうかを判断します。
| チャート | 説明 | 調査すべき点 |
|---|---|---|
| CPU使用率 | アプリケーションホスト全体で利用中のCPUの割合。 | 持続的な高利用率は、スケールアウトまたはコンピューティング集約型操作の最適化を必要とする場合があります。CPUの急増と応答時間の増加を関連付けてください。 |
| メモリ使用量 | 消費されたメモリの割合。 | メモリ使用量の上昇と頻繁なフルGC (サマリーメトリックを参照) が組み合わさると、メモリリークを示している可能性があります。 |
| ロード | システムロードアベレージ。 | ロード値を、利用可能なCPUコア数と比較してください。コア数よりも常に高いロードは、ホストが過負荷であることを示します。 |
トラブルシューティングワークフロー
サマリーメトリックでアノマリーに気づいた場合、根本原因を特定するために、次のアプローチを使用します。
サマリーメトリックを確認します。どの指標がベースラインから逸脱しているかを特定します。例えば、平均応答時間が増加し、総リクエスト数が安定している場合、問題はトラフィックに関連していない可能性が高いです。
依存サービスを調査します。アプリケーション依存サービスチャートでレイテンシーの急増またはエラーコードの増加を確認します。下流サービスで5xx応答の増加が見られる場合、問題はそこから発生している可能性があります。
システムリソースを確認します。CPU使用率、メモリ使用量、ロードを確認します。CPUが飽和状態であるか、メモリ使用量が増加し頻繁なフルGCが発生している場合、問題はサービスレベルではなくリソースレベルである可能性があります。
レイヤー間で関連付けます。アプリケーションメトリックとシステムメトリック全体でアノマリーのタイミングを比較します。例えば、応答時間の急増がCPUの急増および最近のデプロイメントと一致する場合、そのデプロイメントがリソース集約型のコードパスを導入したことを示唆しています。