Elastic Compute Service (ECS) インスタンスを使用すると、インスタンスの起動が遅い、システム負荷が高いなどのイメージ関連の問題が発生したり、カーネルのコンパイル方法などの質問がある場合があります。 このトピックでは、ECSインスタンスの使用時に発生する可能性のあるイメージに関するよくある質問 (FAQ) に対する回答を提供します。
Windowsイメージに関するFAQ
WindowsインスタンスのRed Hat virtioドライバーを更新する
Windows Serverの半期チャネルイメージとインスタンスを管理する方法?
VNCを使用してインスタンスに接続した後、UEFIイメージを実行するWindowsインスタンスの画面解像度を変更できない場合はどうすればよいですか。
インスタンスのWindows Serverオペレーティングシステムが本物ではないことを確認された場合はどうすればよいですか?
オペレーティングシステムを有効にする必要があります。 詳細については、「」をご参照ください。KMSドメイン名を使用してVPCでWindowsインスタンスをアクティブ化する方法は?
WindowsでtimeBeginPeriod呼び出しが頻繁に発生してシステム時間エラーが発生した場合はどうすればよいですか?
Windows Server 2008では、timeBeginPeriodを頻繁に呼び出すと、システム時間が不正確になることがあります。 問題を解決するには、次の操作を実行します。
説明システム時間の精度に影響を与える可能性のあるシステム機能については、「待機機能」をご参照ください。
インスタンスに接続します。
詳細については、「パスワードまたはキーを使用したWindowsインスタンスへの接続」をご参照ください。
CheckTimeBeginPeriod.zipをダウンロードします。
CheckTimeBeginPeriod.zipを解凍します。
解凍bin.zip、に行くビンをダブルクリックし、. exeファイルを作成します。
64ビットオペレーティングシステムの場合は、[InjectDllx64.exe] をダブルクリックします。
32ビットオペレーティングシステムの場合は、[InjectDllx86.exe] をダブルクリックします。
timeBeginPeriod関数を呼び出すプロセスが表示されます。
ビジネス要件に基づいてtimeBeginPeriod関数を呼び出すプロセスを停止または更新します。
問題が解決しない場合は、 チケットを起票
し、Alibaba Cloudテクニカルサポートにお問い合わせください。
「以下のWebサイトのコンテンツがInternet Explorerのセキュリティ強化構成によってブロックされている」というエラーメッセージが表示された場合はどうすればよいですか?
Windows ECSインスタンスまたはWindowsシンプルアプリケーションサーバーのInternet ExplorerでWebサイトを開こうとすると、次のエラーメッセージが表示されます。 問題の解決方法については、「」をご参照ください。「以下のWebサイトのコンテンツがInternet Explorerのセキュリティ強化構成によってブロックされています」というエラーメッセージが表示された場合はどうすればよいですか?
Windows ECSインスタンスのシステムディスクを交換するか、システムディスクを再初期化すると、ユーザーデータが自動的に実行されないのはなぜですか。
原因
Windows ECSインスタンスの起動後、
C:\ProgramData\aliyun\vminit \instance_<インスタンスID>\METASERVERディレクトリにキャッシュファイルが作成されます。 キャッシュファイルは、インスタンスが初期化されるかどうかをマークするために使用されます。 インスタンスからカスタムイメージを作成し、そのカスタムイメージを使用してインスタンスのシステムディスクを再初期化または置換すると、インスタンスのIDと同じIDのキャッシュファイルがC:\ProgramData\aliyun\vminit \instance_<instance ID>\METASERVERディレクトリに保存されます。 Vminitコンポーネントは、キャッシュファイルの存在に基づいて、ECSインスタンスが初めて起動されるかどうかを判断します。 インスタンスのIDと同じIDのキャッシュファイルが存在する場合、Vminitコンポーネントは、ECSインスタンスが初めて起動されたときではないと判断し、ユーザーデータ内のスクリプトは自動的に実行されません。説明Vminitコンポーネントは、Windowsインスタンスを作成すると自動的にインストールされます。 Linux cloud-initサービスと同様に、Vminitコンポーネントはブートフェーズ中にWindowsインスタンスの構成を初期化します。 Vminitコンポーネントの詳細については、「Vminitコンポーネント」をご参照ください。
解決策
ECSインスタンスからカスタムイメージを作成する前に、
C:\ProgramData\aliyun\vminit \instance_<インスタンスID>\METASERVERディレクトリにあるキャッシュファイルを確認して削除することを推奨します。
よくある質問CentOSとRed Hatの画像
CentOS DNS解決タイムアウトの問題を解決するにはどうすればよいですか?
原因
CentOS 6 および CentOS 7 の DNS 解決メカニズムが変更されました。 DNS解決タイムアウトエラーは、2017年2月22日より前に作成された、または2017年2月22日より前に作成されたカスタムイメージを使用するCentOS 6またはCentOS 7インスタンスで発生する可能性があります。
解決策
問題を解決するには、次の手順を実行します。
fix_dns.sh スクリプトをダウンロードします。
ダウンロードしたスクリプトをCentOSオペレーティングシステムの /tmpディレクトリに配置します。
bash /tmp/fix_dns.sh コマンドを実行してから、スクリプトを実行します。
スクリプトに関する次の事項に注意してください。
スクリプトは、インスタンスのオペレーティングシステムがCentOSであるかどうかを判断します。
オペレーティングシステムがUbuntuまたはDebianの場合など、オペレーティングシステムがCentOSでない場合、スクリプトは実行を停止します。
オペレーティングシステムがCentOSの場合、スクリプトは引き続き実行されます。
スクリプトは、/etc/resolv.confファイルの
options設定をチェックします。options設定が使用できない場合、スクリプトは次の操作を実行します。Alibaba Cloud
options設定を使用します (options timeout:2試行: 3 rotate single-request-reopen) 。
options設定が使用可能な場合、スクリプトはsingle-request-reopenオプションが存在するかどうかを確認します。single-request-reopenオプションが存在しない場合、スクリプトはこのオプションをoptions設定に追加します。single-request-reopenオプションが存在する場合、スクリプトの実行は停止し、DNSネームサーバーの構成は変更されません。
インスタンスを再起動せずにCentOS 7またはWindowsインスタンスを長期間使用すると、インスタンスがネットワークから切断されたり、ネットワークが利用できなくなったり、インスタンスのパブリックIPアドレスまたはプライベートIPアドレスをpingできなくなったりします。 どうすればよいですか。
この問題の原因と解決策については、「CentOS 7」をご参照ください。
CentOS 7.9 for Armオペレーティングシステムがダンプファイルの生成に失敗した場合はどうすればよいですか?
問題の内容
CentOS 7.9 for Armオペレーティングシステムがダウンしていて、
ls /var/crashコマンドを実行してダンプファイルを照会すると、vmcoreファイルは生成されません。
原因
CentOS 7.9 for Armオペレーティングシステムには、
CONFIG_ARM64_USER_VA_BITS_52オプションがyに設定されているカーネルがあり、ユーザースペースの52ビット仮想アドレス指定を有効にします。 オペレーティングシステムに付属のmakedumpfileソフトウェアのバージョンがカーネルバージョンと一致していません。 そのため, ダンプファイルを生成できません。解決策
重要このソリューションは、kdumpサービスが有効になっているオペレーティングシステムにのみ適用されます。 このトピックの説明に従って、kdumpサービスが無効になっていて、上記の問題を解決した場合は、
proc/cmdlineファイルでcrashkernelパラメーターを設定します。次のコマンドを実行して、kexec-toolsパッケージをダウンロードします。
wget http://mirrors.aliyun.com/centos-vault/7.9.2009/os/Source/SPackages/kexec-tools-2.0.15-51.el7.src.rpm次のコマンドを実行して、RPM Package Manager (RPM) パッケージをインストールします。
rpm -ivh kexec-tools-2.0.15-51.el7.src.rpm次のコマンドを実行してパッチファイルをダウンロードします。
cd /root/rpmbuild/SOURCES wget https://ecs-image-tools.oss-cn-hangzhou.aliyuncs.com/patch/rhelonly-kexec-tools-2.0.20-makedumpfile-arm64-Add-support-for-ARMv8.2-LVA-52-bi.patchkexec-tools.specファイルを変更します。
次のコマンドを実行して、kexec-tools.specファイルを開きます。
cd /root/rpmbuild/SPECS/ vi kexec-tools.specIキーを押してInsertモードに入り、ファイル内の対応する位置に次の行を追加します。Patch999: rhelonly-kexec-tools-2.0.20-makedumpfile-arm64-Add-support-for-ARMv8.2-LVA-52-bi.patch %patch999 -p1次の図に示すように行を追加します。
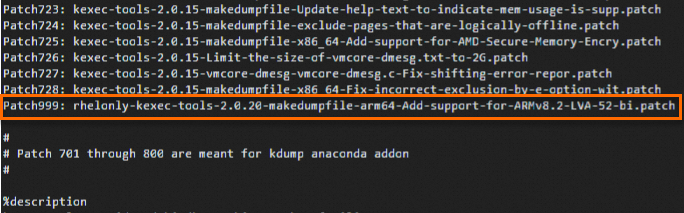
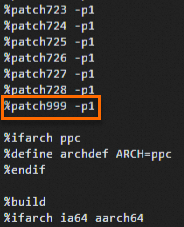
Escキーを押して挿入モードを終了し、:wqと入力してファイルを保存して閉じます。
次のコマンドを実行して、インストールの依存関係を確認します。
yum-builddep kexec-tools.spec次のコマンドを実行して、RPMパッケージをビルドします。
yum -y install rpm-build rpmbuild -ba kexec-tools.spec次のコマンドを実行して、変更されたRPMパッケージをインストールします。
cd /root/rpmbuild/RPMS/aarch64 rpm -ivh kexec-tools-2.0.15-51.el7.aarch64.rpm
ダウンタイムが再び発生した場合は、
ls -lh /var/crashコマンドを実行してダンプファイルを照会できます。vmcoreファイルが生成されていることがわかった場合は、問題が解決したことを示します。
どのようにしてCentOS 7をRHEL 7に変換しますか?
CentOS 7は、2024年6月30日に終末期 (EOL) に到達します。 Alibaba Cloudは、その日からオペレーティングシステムのサポートを提供しなくなります。 CentOS 7 EOLの影響を防ぐために、CentOS 7をRHEL 7に変換できます。 次のセクションでは、Alibaba CloudでCentOS 7をRHEL 7に変換する方法について説明します。 詳細については、「RPMベースのLinuxディストリビューションからRHELへの変換」をご参照ください。
重要誤った操作によるデータの損失や例外を防ぐため、重要なアプリケーション、データベースサービス、データストレージサービスを停止し、変換前にディスクスナップショットを作成して重要なデータをバックアップすることを推奨します。
(条件付きで必要) ECSインスタンスを使用し、インスタンスにServer Guardをインストールした場合は、まずServer Guardをアンインストールします。
詳細については、「Security Centerエージェントのアンインストール」をご参照ください。
説明Server Guardは、CentOSのデフォルトのセキュリティ強化ツールです。 RHEL 7は、Red Hatが提供するセキュリティ強化ツールを使用しています。 Server GuardはRHEL 7のツールと互換性がなく、競合する可能性があります。 変換プロセス中にServer Guardをアンインストールして、システムの安定性と互換性を確保します。
次のコマンドを実行して、システムソフトウェアパッケージを最新バージョンにアップグレードします。
sudo wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo sudo wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo次のコマンドを実行して、システムソフトウェアパッケージを更新し、システムを再起動します。
sudo yum -y update sudo reboot次のコマンドを実行して、Red Hat公式Webサイトからconvert2rhelツールをダウンロードし、ツールをインストールします。
sudo curl -o /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release https://www.redhat.com/security/data/fd431d51.txt sudo curl --create-dirs -o /etc/rhsm/ca/redhat-uep.pem https://ftp.redhat.com/redhat/convert2rhel/redhat-uep.pem sudo curl -o /etc/yum.repos.d/convert2rhel.repo https://ftp.redhat.com/redhat/convert2rhel/7/convert2rhel.repo sudo yum -y install convert2rhelAlibaba CloudでRHELサブスクリプションを購入し、RHEL 7 RPMリポジトリのアドレスを取得します。
詳しくは、「API を介したメトリックデータのアクセス」をご参照ください。 チケットを起票
してください。
次のコマンドを実行して、RHEL 7 RPMリポジトリをインストールします。
sudo rpm -ivh --replacefiles <RPM repository address> sudo sed -i 's/enabled=1/enabled=0/g' /etc/yum.repos.d/rh-cloud.repo<RPM repository address>をRHEL 7の実際のRPMリポジトリアドレスに置き換えます。 RHELサブスクリプションの購入時にアドレスを取得できます。次のコマンドを実行して、CentOS 7をRHEL 7に変換します。
sudo convert2rhel -y --no-rhsm --enablerepo rhui-rhel-7-server-rhui-rpms --enablerepo rhui-rhel-7-server-rhui-extras-rpms --enablerepo rhui-rhel-7-server-rhui-optional-rpms変換プロセスには時間がかかります。 次のコマンド出力は、変換が完了したことを示します。
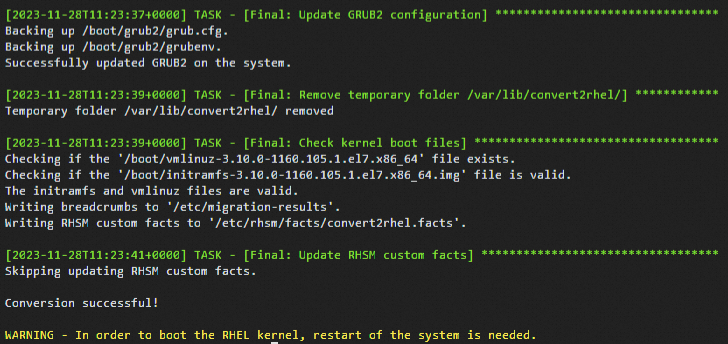
次のコマンドを実行して、システムを再起動します。
変換が完了すると、システムを再起動するように促すメッセージが表示されます。 システムを再起動して、新しいRHELカーネルを起動します。 次に、オペレーティングシステムの変換が成功したかどうかを確認します。
sudo reboot説明CentOS 7をRHEL 7に変換した後、RHEL 7をRHEL 8にアップグレードする場合は、Red Hat Enterprise Linux (RHEL) 7をRHEL 8にアップグレードするにはどうすればよいですか?
Red Hat 8.1とRed Hat 8.2イメージは、ECSベアメタルインスタンスでゆっくりと開始されます。 どうすればよいですか。
ECSベアメタルインスタンスでRed Hat 8.1またはRed Hat 8.2イメージを使用する場合、イメージの開始にはRed Hat 7イメージよりも最大2分かかります。 この問題を解決するには、Red Hat 8.1またはRed Hat 8.2イメージの
/boot/grub2/grubenvファイルで、カーネルの起動パラメーター設定をconsole=ttyS0 console=ttyS0,115200n 8からconsole=tty0 console=ttyS0,115200n 8に変更し、インスタンスを再起動して変更を有効にします。
Ubuntuイメージに関するFAQ
特定のバージョンのUbuntuオペレーティングシステムを実行するECSインスタンスでServer Guard (AliYunDun) プロセスが開始されると、インスタンスの平均負荷が増加します。 これはなぜですか。
Ubuntu 18.04などの特定のバージョンのUbuntuオペレーティングシステムを実行するECSインスタンスでServer Guardプロセスが開始されると、インスタンスの平均負荷が増加します。
FAQに関するFreeBSDイメージ
FreeBSDでパッチをインストールしてカーネルをコンパイルするにはどうすればよいですか?
Alibaba Cloud FreeBSDパブリックイメージのカーネルは、シリーズV以降のインスタンスファミリーのスタートアップ要件を満たすようにパッチが適用されています。
Generationパラメーターを指定してDescribeInstanceTypeFamilies操作を呼び出し、インスタンスファミリーを照会できます。次のシナリオでは、FreeBSDカーネルソースコードを使用してパッチをインストールし、カーネルをコンパイルして、インスタンスが起動できない問題を解決して防止できます。
Alibaba Cloudが提供していないFreeBSDイメージ、またはAlibaba Cloudが提供していないFreeBSDイメージから派生したカスタムイメージを使用して、series-V以降のインスタンスファミリーのインスタンスを作成すると、インスタンスが起動できない場合があります。
FreeBSDパブリックイメージを使用してseries-V以降のインスタンスファミリーのインスタンスを作成し、freebsd-updateを使用してカーネルを新しいパッチで更新すると、インスタンスが起動できない場合があります。
FreeBSD 13以降のパッチをインストールする必要はありません。 この例では、FreeBSD 12.3を使用して、FreeBSDカーネルソースコードを使用してカーネルパッチをインストールし、カーネルをコンパイルする方法を説明します。
FreeBSDカーネルソースコードパッケージをダウンロードして解凍します。
wget https://mirrors.aliyun.com/freebsd/releases/amd64/12.3-RELEASE/src.txz -O /src.txz cd / tar -zxvf /src.txzパッチをダウンロードします。
この例では、パッチ
0001-virtio.patchがダウンロードされます。cd /usr/src/sys/dev/virtio/ wget https://ecs-image-tools.oss-cn-hangzhou.aliyuncs.com/0001-virtio.patch patch -p4 < 0001-virtio.patchカーネルファイルをコピーし、カーネルをコンパイルしてインストールします。
make -j<N>コマンドのNは、並列に実行されるジョブの数を示します。 コンパイル環境に基づいてNを設定します。 たとえば、シングルvCPU環境の場合、-j<N> を-j2に設定することを推奨します。 これは、vCPUの数とNの値の比が1:2であることを示しています。cd /usr/src/ cp ./sys/amd64/conf/GENERIC . make -j2 buildworld KERNCONF=GENERIC make -j2 buildkernel KERNCONF=GENERIC make -j2 installkernel KERNCONF=GENERICカーネルのコンパイル後、ソースコードを削除します。
rm -rf /usr/src/* rm -rf /usr/src/.*
FreeBSDオペレーティングシステムを実行するECSインスタンスのシステムディスクがKVM環境にありません。 どうすればよいですか。
問題の内容
次の図に示すように、カーネルベースの仮想マシン (KVM) 環境でFreeBSDオペレーティングシステムを実行するECSインスタンスにVNC (Virtual Network Computing) を使用してログインした場合、インスタンスのシステムディスクが見つからず、ログインに失敗しました。
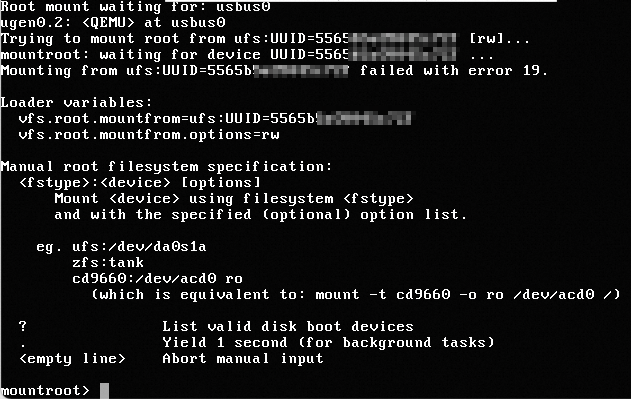
解決策
VNCインターフェイスに疑問符 (?) を入力して、ルートファイルシステムのufsidを表示します。
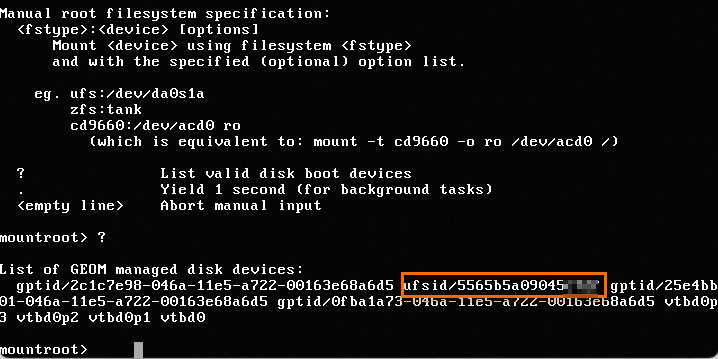
ufs:/dev/ufsid/5565b5a09045 ****と入力し、Enterキーを押してオペレーティングシステムにアクセスします。ユーザー名とパスワードを入力して、システムにログインします。
次のコマンドを実行して、
/etc/fstabファイルの設定を確認します。cat /etc/fstab次の図に示すコマンド出力は、ルートファイルシステムが
/etc/fstabファイル内のUUIDに基づいてマウントされるように構成されていることを示しています。 ただし、FreeBSDオペレーティングシステムは、UUIDに基づくデバイスのマウントをサポートしていません。 ufsidに基づいてマウントされるようにルートファイルシステムを構成する必要があります。
ufsidに基づいてマウントされるルートファイルシステムを設定します。
次のコマンドを実行して、
/etc/fstabファイルを開きます。vi /etc/fstabIキーを押して挿入モードに入ります。
UUID=5565b5a09045 ****を/dev/ufsid/5565b5a09045 ****に変更します。Escキーを押して
:wqと入力し、enterキーを押して変更を保存して終了します。
次のコマンドを実行して、変更を有効にするためにシステムを再起動します。
reboot
フェドラ画像に関するFAQ
SSH-rsa署名アルゴリズムを使用するsshキーペアを使用して、Fedora 33 64ビットを実行するECSインスタンスに接続できないのはなぜですか。
SSH-rsa署名アルゴリズムを使用するsshキーペアを使用してFedora 33 64ビットを実行するECSインスタンスに接続すると、インスタンスに接続できない場合があります。 以下のいずれかの方法を使用して問題を解決できます。
SSH-rsa署名アルゴリズムを使用するsshキーペアを、Elliptic Curve Digital signature algorithm (ECDSA) などの異なる署名アルゴリズムを使用するSSHキーペアに置き換えます。
システムでupdate-crypto-policies -- set LEGACYコマンドを実行し、
POLICYをLEGACYに変更します。 その後、SSH-rsa署名アルゴリズムを使用するsshキーペアを引き続き使用できます。
Fedora CoreOSイメージを使用して特定のインスタンスファミリーのインスタンスを作成した後、lscpuコマンド出力のCPU数は、選択したインスタンスタイプのvCPU数の半分にすぎないことがわかりました。 これはなぜですか。
Fedora CoreOSイメージを使用してg5などの特定のインスタンスファミリーのインスタンスを作成した後、インスタンスに対してlscpuコマンドを実行してCPU情報を表示します。 コマンド出力では、
[オンラインCPU(s)] リストの値で示されるvCPUの総数は、選択したインスタンスタイプのvCPUの数の半分にすぎません。 たとえば、2つのvCPUを持つインスタンスタイプを使用してインスタンスを作成した場合、次の図に示すように、オンラインCPUリストの値は1つのvCPUのみを示します。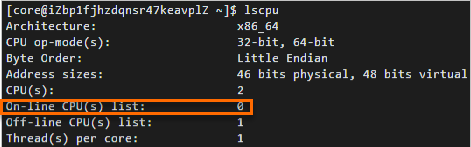 説明
説明オンラインCPUリストの値は、vCPUシリアル番号を示します。 上の図では、シリアル番号が0のvCPUは1つだけ使用できます。これは、Fedora CoreOSカーネルでは、脆弱なシステムの同時マルチスレッド (SMT) を無効にするために、緩和ブートパラメーターがデフォルトで
auto,nosmtに設定されているためです。auto、nosmtに設定されている軽減パラメーターを表示するには、cat /proc/cmdlineコマンドを実行します。SMTの詳細については、「脆弱性に対処するために必要なときにSMTを自動的に無効にする」および「SMTを無効にするポリシー」をご参照ください。
その他
FAQ for Linuxタイムゾーンとタイムゾーン
LinuxカスタムイメージをNVMeベースのシステムディスクに適応させるにはどうすればよいですか?
移行済みインスタンスで発生するダウンタイムの問題を解決するにはどうすればよいですか。
LinuxサーバーにGRand Unified Bootloader (GRUB) をインストールするにはどうすればよいですか?
RSAキーを使用してインスタンスに接続できない場合はどうすればよいですか。
インスタンスのオペレーティングシステムに障害が発生した後、kdump情報を収集する方法を教えてください。
/proc/cpuinfoファイルのCPU周波数とインスタンスに指定された周波数との間の不一致を解決するにはどうすればよいですか。
kdumpサービスがECSベアメタルインスタンスでクラッシュダンプファイルを生成できない場合はどうすればよいですか。
この問題の原因と解決策については、一部のECSインスタンスでクラッシュダンプファイルが生成されない場合はどうすればよいですか。
Linuxオペレーティングシステムカーネルのライトバックプロセス中にソフトロックアップエラーが発生します。 どうすればよいですか。
以前のバージョンのLinuxカーネルがデータをファイルキャッシュに書き戻すと、ソフトロックアップエラーが発生します。 この問題を解決する方法については、「Linuxオペレーティングシステムカーネルのライトバックプロセス中にソフトロックアップが発生する問題の解決策」をご参照ください。
ECSインスタンスからcgroupsを削除すると、ソフトロックアップエラーが発生します。 どうすればよいですか。
この問題を解決する方法については、「ECSインスタンスのcgroupsを削除するとソフトロックアップエラーが発生する」をご参照ください。 どうすればよいですか。
ECSインスタンスがダウンします。 どうすればよいですか。
ECSインスタンスがダウンし、「メモリ不足とkillableプロセスなし」というエラーメッセージが表示されます。 どうすればよいですか。
ECSインスタンスがダウンし、「kmallocに残っているオブジェクト」メッセージがアラートログに表示されます。 どうすればよいですか。
ECSインスタンスがダウンし、「RIP:get_target_pstate_use_performance」エラーメッセージがログに表示されます。 どうすればよいですか。
ECSインスタンスがダウンし、「VFS: unknown-blockにルートfsをマウントできません」というメッセージがログに表示されます。 どうすればよいですか。
FTPサービスにはパブリックイメージが付属していますか?
いいえ、FTPサービスにはパブリックイメージが付属していません。 FTP サービスはご自身で設定する必要があります。 詳細については、「WindowsインスタンスでFTPサイトを手動で構築する」および「CentOS 7インスタンスでFTPサイトを手動で構築する」をご参照ください。
ECSが仮想メモリを無効にし、スワップパーティションをデフォルトで未設定のままにするのはなぜですか。
物理メモリが不足している場合、メモリマネージャは、長期間非アクティブであったメモリデータをスワップパーティションまたは仮想メモリファイルに保存します。 このメカニズムは、使用可能なメモリの量を増やすのに役立ちます。
ただし、メモリ使用量がすでに多く、I/Oパフォーマンスが低い場合、このメカニズムは代わりに使用可能なメモリの量を減らします。 Alibaba Cloud ECSクラウドディスクは、ストレージに分散ファイルシステムを使用し、データごとに一貫性の高い複数のレプリカを提供します。 このメカニズムは、ユーザーデータのセキュリティを保証しますが、I/O 操作の数を 3 倍にすることにより、ローカルディスクのストレージと I/O パフォーマンスを低下させます。
そのため、Windowsでは仮想メモリが無効になっており、システムリソースが不足している場合にI/Oパフォーマンスがさらに低下しないように、デフォルトではスワップパーティションがLinux用に構成されていません。
パブリックイメージでkdumpサービスを有効にするにはどうすればよいですか?
デフォルトでは、kdumpサービスはパブリックイメージで無効になっています。 インスタンスがダウンしているときにインスタンスがコアファイルを生成し、そのファイルを使用して障害の原因を分析できるようにする場合は、次の手順を実行してkdumpサービスを有効にします。 次の例では、CentOS 7.2パブリックイメージが使用されています。 操作は、オペレーティングシステムのバージョンによって異なる場合があります。
コアファイルを生成するディレクトリを設定します。
vim /etc/kdump.confコマンドを実行して、kdump設定ファイルを開きます。
path コマンドを実行して、コアファイルを生成するディレクトリを設定します。 この例では、ディレクトリは /var/crash で、次の path コマンドが使用されます。
path /var/crash/etc/kdump.conf ファイルを保存して閉じます。
kdump サービスを有効にします。
kdumpサービスを有効にするには、オペレーティングシステムに基づいて次のいずれかの方法を使用します。
方法 1: 次のコマンドを実行して、kdump サービスを有効にします。
systemctl enable kdump.servicesystemctlstartkdump.service方法 2: 次のコマンドを実行して、kdump サービスを有効にします。
chkconfig kdump onservice kdump start方法3: Cloud Assistantがインスタンスにインストールされている場合は、の手順に基づいてkdumpサービスを有効にします。移行済みインスタンスのダウンタイムの問題を解決するにはどうすればよいですか。 kdump サービスを有効にします。
NTPサービスがインストールされているLinuxインスタンスにIPv6アドレスが割り当てられると、インスタンスの時刻をUTC時刻と同期できなくなります。 どうすればよいですか。
問題の内容
Linuxインスタンスで
ntpq -pコマンドを実行して時刻を同期すると、次の図に示すようにタイムアウトエラーが発生します。
解決策
説明このソリューションは、CentOS 7以前、Ubuntu 20.04以前、Anolis OS RHCK、Anolis OS ANCK、Alibaba Cloud Linux、およびDebianのオペレーティングシステムを実行するインスタンスに適用できます。
Linuxインスタンスに接続します。
詳細については、「パスワードまたはキーを使用したLinuxインスタンスへの接続」をご参照ください。
次のコマンドを実行して、/etc/ntp.conf設定ファイルを変更します。
vi /etc/ntp.confIキーを押して挿入モードに入ります。
次の図に示すように、
restrict -6 ::1をファイルに追加します。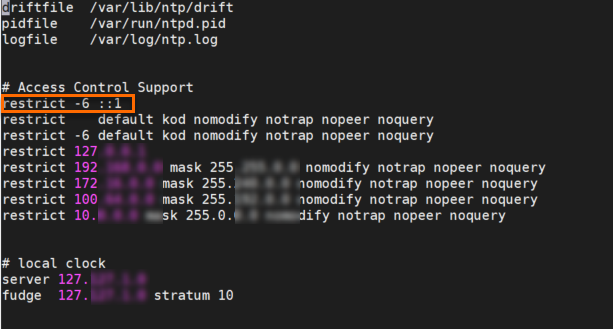
Escキーを押します。 次に、
:wqと入力し、enterキーを押して変更を保存して終了します。次のコマンドを実行して、NTPサービスを再起動します。
systemctl restart ntp
、カスタムイメージを使用する実行中のインスタンスのディスクまたはENIをホットスワップできません。 これはなぜですか。
問題の内容
ディスクまたはelastic network Interface (ENI) のホットスワップでは、実行中 状態のインスタンスにディスクをアタッチし、ディスクをデタッチし、ENIをバインドし、ENIをバインド解除します。 カスタムイメージを使用する実行中インスタンスのディスクまたはENIをホットスワップすることはできません。
Alibaba Cloud上のインスタンスのディスクとENIをホットスワップできます。 ただし、インスタンスのオペレーティングシステムカーネルが操作をサポートしていない場合、ホットスワップ操作が失敗する可能性があります。 インスタンスのオペレーティングシステムカーネルが操作をサポートしていない場合、次の問題が発生する可能性があります。
ディスクをインスタンスにアタッチまたはENIをバインドした後、ディスクまたはENIはオペレーティングシステムで見つかりません。
ディスクをデタッチしたり、インスタンスからENIをバインド解除したりすることはできません。
解決策
ECSインスタンスとECSベアメタルインスタンスのオペレーティングシステムカーネルは、ホットスワップを可能にするさまざまな機能をサポートしています。 すべてのインスタンスのオペレーティングシステムカーネルで、PCI (Peripheral Component Interconnect) ホットスワップおよびACPI (Advanced Configuration and Power Management Interface) ホットスワップ機能を有効にすることを推奨します。 デフォルトでは、PCIホットスワッピングとACPIホットスワッピングは、CentOS 5などの初期バージョンを除くすべてのオペレーティングシステムで有効になっています。 カーネルでPCIホットスワップまたはACPIホットスワップが有効になっているかどうかを確認するには、次の手順を実行します。
Linuxインスタンスに接続します。
詳細については、「パスワードまたはキーを使用したLinuxインスタンスへの接続」をご参照ください。
次のコマンドを実行して、インスタンスのカーネルバージョンを表示します。
uname -r次の図に示すコマンド出力は、カーネルのバージョンが
3.10.0-1127.19.1.el7.x86_64であることを示しています。
次のコマンドを実行して、
/bootディレクトリ内のファイルを確認します。ll /bootコマンド出力に表示される
config-3.10.0-1127.19.1.el7.x86_64の情報は、config-3.10.0-1127.19.1.el7.x86_64ファイルがシステムカーネルの構成ファイルであることを示しています。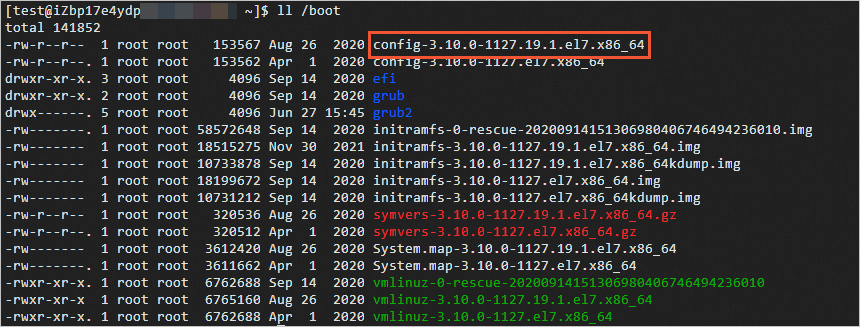
次のコマンドを実行して、システムカーネルの構成を確認します。
cat /boot/config-3.10.0-1127.19.1.el7.x86_64次の設定項目が
yに設定されている場合、オペレーティングシステムはホットスワップ機能をサポートします。CONFIG_HOTPLUG_PCI_PCIE=y CONFIG_HOTPLUG_PCI=y CONFIG_HOTPLUG_PCI_ACPI=y次のいずれかの設定項目が
not setに設定されている場合、対応するホットスワップ機能はカーネルでサポートされていないため、カーネル設定を変更する必要があります。次のいずれかの設定項目が
mに設定されている場合、設定項目はモジュールにコンパイルされます。 たとえば、次の図に示すように、CONFIG_HOTPLUG_PCI_ACPI設定項目はmに設定されます。 これは、CONFIG_HOTPLUG_PCI_ACPIがモジュールにコンパイルされることを示します。 対応する機能を使用するには、モジュールを読み込む必要があります。CONFIG_HOTPLUG_PCI_PCIE=y CONFIG_HOTPLUG_PCI=y CONFIG_HOTPLUG_PCI_ACPI=mたとえば、カーネルバージョン2.6のCentOS 5.xオペレーティングシステムを使用している場合、
CONFIG_HOTPLUG_PCI_ACPI設定項目に対応するモジュールはacpiphp.koです。 モジュールをロードするには、modprobe acpiphpコマンドを実行する必要があります。 モジュールの読み込みに失敗した場合は、新しいカーネルバージョンにアップグレードするか、インスタンスを停止してから、ホットスワップ操作を実行します。重要インスタンスのカーネルバージョンまたはオペレーティングシステムバージョンを任意にアップグレードしないことを推奨します。 カーネルバージョンをアップグレードする方法の詳細については、「Linuxインスタンスのカーネルアップグレード中の起動失敗を回避する方法」をご参照ください。
オペレーティングシステムのカーネルエラーが発生した後にインスタンスがシャットダウンされた場合はどうすればよいですか?
問題の内容
インスタンスのオペレーティングシステム内で予期しないカーネルエラー (カーネルパニック) が発生すると、2番目のカーネル (キャプチャカーネル) が読み込まれ、メモリダンプが実行され、Kdumpログファイルが生成されます。 ECS Bare Metalインスタンスタイプの互換性の問題により、2番目のカーネルの起動中にディスクの識別が失敗します。 その結果、Kdumpログの収集が失敗し、2番目のカーネルの開始に失敗します。 インスタンスは停止状態です。 ECSコンソールでインスタンスを再起動する必要があります。
ECS Bare Metalインスタンスタイプの詳細については、「インスタンスファミリーの概要」をご参照ください。
原因
ECSベアメタルインスタンスは、オペレーティングシステムに付属のKdumpサービスを使用してダンプファイルを生成できない場合があります。
この問題は、第6世代ECSベアメタルインスタンスに次のイメージを使用する場合に発生します。
CentOS 8.3以前
Ubuntu 16または18
デビアン10
カーネルバージョンが
4.19.91-24.al7より前のAlibaba Cloud Linux 2 (この問題は、カーネルバージョン4.19.91-24.al7以降のAlibaba Cloud Linux 2で修正されています) 。
この問題は、第7世代ECSベアメタルインスタンスでDebian 10イメージを選択したときに発生します。
解決策
CentOSイメージ
オペレーティングシステムを新しいバージョンに置き換えることをお勧めします。 詳細については、「インスタンスのオペレーティングシステム (システムディスク) の交換」をご参照ください。
Alibaba Cloud Linux 2イメージ
カーネルのバージョンを
4.19.91-24.al7以降にアップグレードするには、次の手順を実行することを推奨します。インスタンスに接続します。
詳細については、「パスワードまたはキーを使用したLinuxインスタンスへの接続」をご参照ください。
次のコマンドを実行して、カーネルのバージョンを照会します。
uname -r次のコマンドを実行して、カーネルバージョンをアップグレードします。
sudo yum update kernel次のコマンドを実行して、新しいカーネルバージョンを有効にするためにECSインスタンスを再起動します。
sudo reboot