E-HPC のモニタリングダッシュボードでは、[概要]、[ノードモニタリング]、[ストレージモニタリング]、[ジョブモニタリング] の 4 つのビューを通じて、計算ノード、共有ストレージ、ジョブリソースをリアルタイムで可視化できます。このデータを使用して、リソースのボトルネックを特定し、ジョブキューの状態を追跡し、情報に基づいたスケジューリングの決定を行うことができます。
前提条件
開始する前に、以下を確認してください。
[実行中] 状態のクラスター
デプロイモードが [パブリッククラウドクラスター] に設定されているクラスター
Slurm または PBS スケジューラを実行しているクラスター
クラスターにモニタリングコンポーネントがインストールされていること
(RAM ユーザーのみ) E-HPC コンソールでモニタリング情報を表示する権限。詳細については、「RAM ユーザーへの権限付与」をご参照ください。
クラスターモニタリングの表示
E-HPC コンソールにログインします。
上部のナビゲーションバーの左側で、リージョンを選択します。
左側のナビゲーションウィンドウで、[Cluster] をクリックします。
[クラスターリスト] ページで、モニタリングするクラスターのクラスター ID をクリックします。
左側のナビゲーションウィンドウで、[運用保守管理] > [モニタリング] を選択します。
タブをクリックして、対応するモニタリングデータを表示します。
[ノードモニタリング]、[ストレージモニタリング]、および [ジョブモニタリング] タブでは、時間範囲コントロールを使用してデータを絞り込みます。プリセットボタンの 1時間、4時間、12時間、または 1日 をクリックして表示します。特定の期間をクエリするには、カスタムの開始時刻と終了時刻を選択します。カスタムで指定できる最大範囲は 1 か月です。
各タブのメトリックの完全なリストについては、「メトリック」をご参照ください。
メトリック
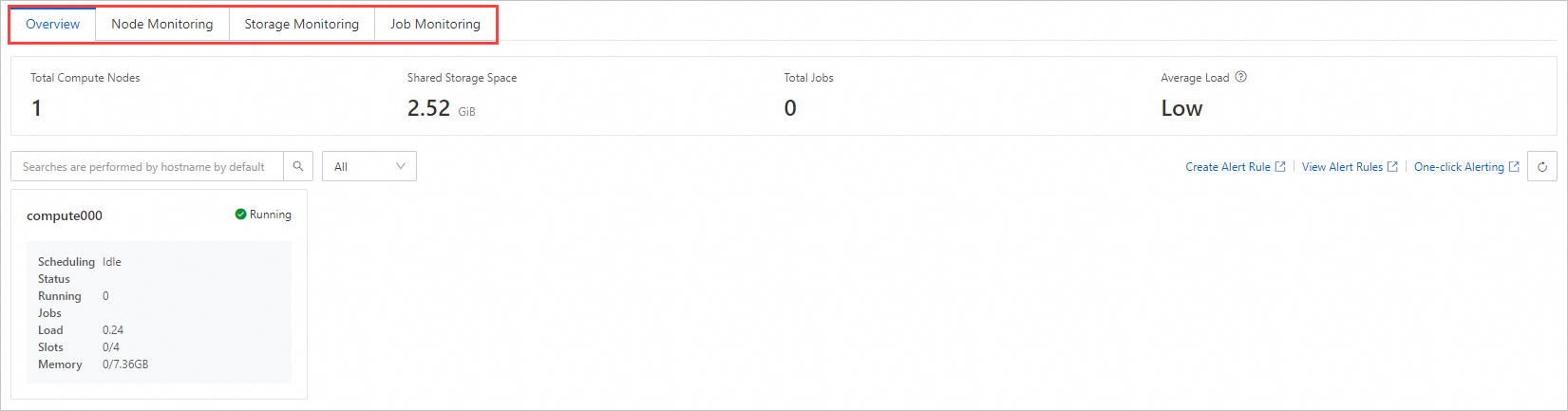
概要
[概要] タブには、クラスター全体のリソース状態の概要が表示されます。
[計算ノードの総数] — クラスター内の計算ノードの総数
[共有ストレージ容量] — 共有ストレージの総容量
合計ジョブ数 — すべての状態にわたるジョブの総数
[平均ロード] — すべての計算ノードにわたる平均システムロード
概要の下に、各計算ノードがスケジューリングステータスとリソース使用量とともにリスト表示されます。スケジューリングステータスの値は次のとおりです。
| ステータス | 説明 |
|---|---|
| アイドル | すべてのコアがアイドル状態です。ノードはフルキャパシティで利用可能であり、新しいジョブを受け入れる準備ができています。 |
| [実行中] | 一部のコアが使用中です。残りのコアは引き続き新しいジョブを受け入れることができます。 |
| [割り当て済み] | すべてのコアが占有されています。新しいジョブは、コアが利用可能になるまでキューに入れられます。 |
| [オフライン] | ノードは計算に参加しておらず、新しいジョブを受け入れません。 |
ノードモニタリング
[ノードモニタリング] タブには、計算ノードのパフォーマンスメトリックが表示されます。クラスターまたはキューでフィルターをかけてビューを絞り込みます。
| メトリクス | 説明 |
|---|---|
| CPU 使用率 | コンピュートノード全体で使用中の処理能力の割合です。継続的に 80~90 % を超える使用率はリソースの効率的な活用を示しますが、長期的にはパフォーマンス低下を招く可能性があります。一方、0~30 % の範囲は、リソースの過少利用またはスケジューリングの問題を示唆している場合があります。 |
| メモリ使用量 | コンピュートノードにおけるメモリ消費量です。バッファオーバーフローによるジョブ失敗を防ぐため、定期的に監視してください。使用量が一貫して高い場合は、メモリ容量の増加またはメモリ割り当ての最適化を実施してください。 |
| システム負荷 | コンピュートノードへのワークロードです。ノードあたりの負荷比率が高い場合、リソースに圧迫が生じていることを示します。負荷を軽減するには、ノードを追加(スケールアウト)するか、ジョブのスケジューリングを最適化してください。 |
| ディスク使用率 | ディスクストレージの消費状況です。ディスク使用率が 100 % になると、書き込み操作が失敗します。このしきい値に達する前に、不要なデータを削除するか、ストレージ容量を拡張してください。 |
| ディスク読み取りおよび書き込み | データの読み取りおよび書き込みレートです。単位:KB/s。これらのレートを活用して I/O パフォーマンスを評価し、ジョブのスループットに影響を与えるボトルネックを検出してください。 |
| ネットワークトラフィック | 仮想プライベートネットワーク (VPN) 上でコンピュートノード間で転送されるデータです。帯域幅に関する課題を早期に検知するため、トラフィックのピーク期間を監視してください。 |
ストレージモニタリング
[ストレージモニタリング] タブには、クラスターにアタッチされている Apsara File Storage NAS (NAS) ファイルシステムのメトリックが表示されます。
| メトリック | 説明 |
|---|---|
| ストレージ容量 | NAS ファイルシステムのストレージ使用量。ストレージの枯渇を防ぐために、モニタリングアラートを設定し、定期的なデータクリーンアップを実行し、プロアクティブに容量を拡張します。 |
| ファイル | NAS ファイルシステム内のファイルの総数。ファイル数が多いと管理が複雑になり、取得パフォーマンスに影響を与える可能性があります。ファイル数がしきい値を超えた場合は、不要なファイルをクリーンアップします。 |
| IOPS | 選択した時間範囲における 1 秒あたりの平均読み取りおよび書き込み操作数。単位:requests/s。 |
| レイテンシー | 選択した時間範囲における操作ごとの平均読み取りおよび書き込みレイテンシー。単位:ミリ秒。 |
| スループット | 選択した時間範囲における平均読み取りおよび書き込みスループット。単位:KiB。 |
| [メタデータ QPS] | 選択した時間範囲における 1 秒あたりの平均メタデータリクエスト数。単位:requests/s。 |
NAS ストレージのメトリックについて詳しくは、「パフォーマンスモニタリング」および「NAS ファイルシステムのパフォーマンスに関するよくある質問」をご参照ください。
ジョブモニタリング
[ジョブモニタリング] タブには、ジョブのリソース消費とキューの状態が表示されます。クラスター、キュー、プロジェクト、またはユーザーでフィルターをかけます。
| メトリック | 説明 |
|---|---|
| ジョブ | 現在実行中のジョブ数です。利用可能なリソースに対して実行中のジョブが急増すると、リソース競合が発生する可能性があります。スケジューリングを最適化するか、不要なジョブを削除することで、スループットを向上させることができます。 |
| キュー内のジョブが必要とする合計コア数 | キューで待機しているジョブによってリクエストされた合計 CPU コア数です。この値が利用可能なコア数を超えると、キュー内のジョブの待機時間が長くなります。コアを追加するか、ジョブの優先度を調整することで、待機時間を短縮できます。 |
| ジョブの待機時間 | ジョブがキューで待機する平均時間です。待機時間が増加している場合は、リソース競合を示しています。優先度の高いジョブを優先的に処理することで、全体的な使用率を向上させることができます。 |
| 実行中のジョブが使用している合計コア数 | 現在実行中のジョブが使用している合計 CPU コア数です。このメトリックを CPU 使用率と合わせて使用することで、割り当てられたコアがアクティブに使用されているかを確認できます。 |
| ジョブの CPU 使用率 | ジョブによってリクエストされた CPU コア数に対する、実際に使用された CPU コア数の比率です。使用率が低い場合は、ジョブ構成が非効率であるか、ワークロードに異常がある可能性を示しています。ジョブの仕様とワークロードのパターンを見直すことで、効率を向上させることができます。 |
| ジョブのメモリ使用量 | ジョブによってリクエストされたメモリに対する、実際に使用されたメモリの比率です。メモリ使用量が過度に高いことによるバッファオーバーフローやメモリ不足を防ぐには、メモリリクエストを調整するか、実際の使用量に合わせてノードスペックをスペックアップする必要があります。 |