このトピックでは、MaxComputeを使用してIPアドレスのジオロケーションをクエリする方法について説明します。 IPアドレスのジオロケーションを照会するには、IPアドレスジオロケーションライブラリをダウンロードし、ライブラリをMaxComputeにアップロードし、ユーザー定義関数 (UDF) を作成してから、SQLステートメントを実行する必要があります。
前提条件
ワークフローでDataWorksを作成します。 この例では、DataWorksシンプルモードを使用します。 詳細については、「ワークフローの作成」をご参照ください。
背景情報
IPアドレスの位置情報を照会するには、TaobaoのIPアドレス位置情報ライブラリが提供するAPIを呼び出すHTTPリクエストを送信します。
MaxComputeではHTTPリクエストを送信できません。 次のいずれかの方法を使用して、MaxComputeでIPアドレスのジオロケーションを照会できます。
SQL文を実行して、IPアドレスジオロケーションライブラリのデータをオンプレミスのマシンにダウンロードします。 次に、HTTPリクエストを送信して、ジオロケーション情報を照会します。
説明この方法は非効率的です。 クエリ頻度は、1秒あたり10クエリ (QPS) 未満である必要があります。 そうでない場合、クエリ要求はTaobaoのIPアドレスジオロケーションライブラリによって拒否されます。
IPアドレスジオロケーションライブラリをオンプレミスのマシンにダウンロードします。 次に、ライブラリ内の地理位置情報を照会します。
説明この方法は非効率的であり、データウェアハウスを使用してデータを分析するシナリオには適していません。
IPアドレスの位置情報ライブラリを維持し、定期的にMaxComputeにアップロードします。 次に、IPアドレスジオロケーションライブラリ内のIPアドレスのジオロケーションを照会します。
説明この方法は効率的です。 IPアドレスの位置情報ライブラリを定期的に管理する必要があります。
IPアドレスの位置情報ライブラリをダウンロードする
IPアドレスの位置情報ライブラリを取得します。 この例では、サンプルIPアドレスのジオロケーションライブラリipdata.txt.utf8が使用されています。 このIPアドレス位置情報ライブラリは、UTF-8形式のライブラリデモです。
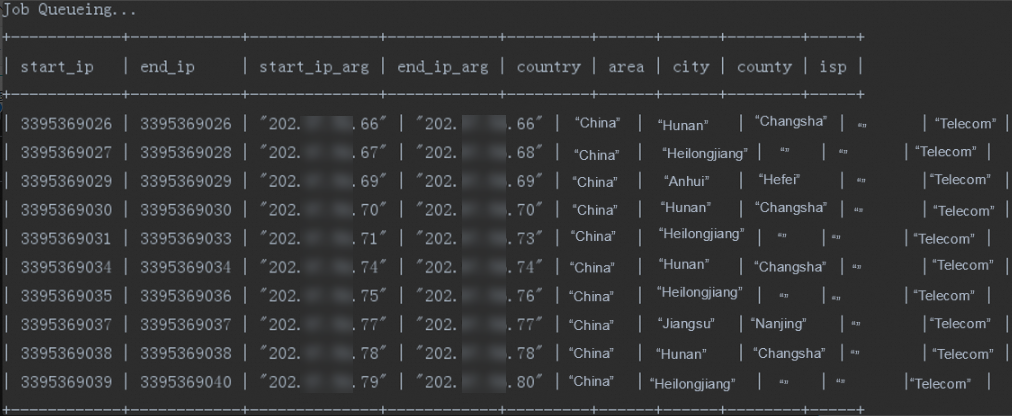
ipdata.txt.utf8ファイルをダウンロードします。 次の図は、ファイル内のデータを示しています。

次の内容では、サンプルIPアドレスのジオロケーションライブラリのデータについて説明します。
データはUTF-8形式です。
データレコードの最初の2つの文字列は、IPアドレス範囲の開始IPアドレスと終了IPアドレスで、10進整数リテラル形式です。 3番目と4番目の文字列は最初の2つの文字列に相当しますが、点線の10進表記で表されます。 10進整数リテラル形式は、IPアドレスが特定のIPアドレス範囲内にあるかどうかを確認するのに役立ちます。
説明独自のIPアドレスジオロケーションライブラリを使用することもできます。
IPアドレスの位置情報ライブラリをアップロードする
MaxComputeクライアントで次のステートメントを実行し、ipresourceという名前のテーブルを作成します。 このテーブルは、IPアドレスのジオロケーションデータを格納するために使用されます。
DROP TABLE IF EXISTS ipresource ; CREATE TABLE IF NOT EXISTS ipresource ( start_ip BIGINT ,end_ip BIGINT ,start_ip_arg string ,end_ip_arg string ,country STRING ,area STRING ,city STRING ,county STRING ,isp STRING );次のTunnelコマンドを実行して、ipdata.txt.utf8ファイルのデータをipresourceテーブルにアップロードします。
odps@ workshop_demo>tunnel upload D:/ipdata.txt.utf8 ipresource;上記のコマンドでは、D:/ipdata.txt.utf8はipdata.txt.utf8ファイルのオンプレミスパスです。 コマンドの詳細については、「Tunnelコマンド」をご参照ください。
次のステートメントを実行して、ファイル内のデータがアップロードされているかどうかを確認できます。
-- Query the number of data records in the ipresource table. select count(*) from ipresource;次のSQL文を実行して、ipresourceテーブルの最初の10個のデータレコードを取得します。
select * from ipresource limit 10;次の結果が返されます。
UDF の作成
DataWorks コンソールにログインします。 上部のナビゲーションバーで、目的のリージョンを選択します。 左側のナビゲーションウィンドウで、 を選択します。 表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[入力データ開発] をクリックします。
Pythonリソースを作成します。
ワークフローを右クリックし、. を選択します。
では、リソースの作成ダイアログボックスで、Nameパラメーターを設定し、MaxComputeにアップロードをクリックし、作成. をクリックします。
Pythonリソースに次のコードを入力します。
from odps.udf import annotate @annotate("string->bigint") class ipint(object): def evaluate(self, ip): try: return reduce(lambda x, y: (x << 8) + y, map(int, ip.split('.'))) except: return 0クリックし、
 リソースを送信するアイコン。
リソースを送信するアイコン。
関数を作成します。
作成したワークフローを右クリックし、. を選択します。
[関数の作成] ダイアログボックスで、[名前] パラメーターを設定し、[作成] をクリックします。
説明DataStudioのワークスペースに複数のMaxComputeエンジンがバインドされている場合は、この関数に使用するエンジンにEngine Instance MaxComputeパラメーターを設定します。
関数の [設定] タブで、パラメーターを設定します。
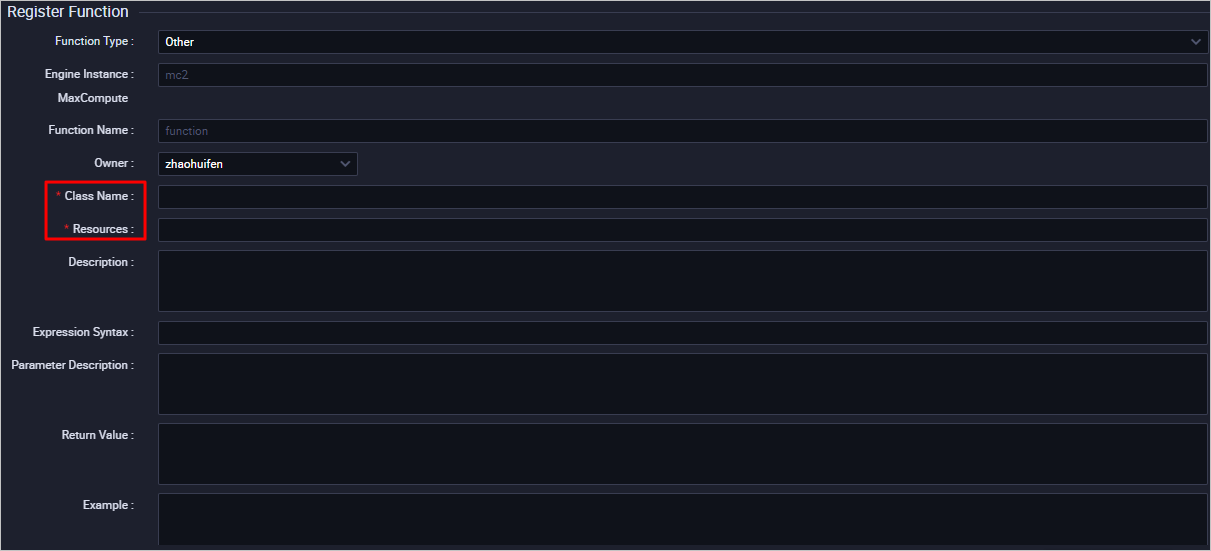
パラメーター
説明
関数タイプ
関数のタイプ。 有効な値: 数学演算関数、集計関数、文字列処理関数、日付関数、ウィンドウ関数、およびその他の関数。
エンジンインスタンスMaxCompute
デフォルト値が表示され、変更できません。
関数名
UDF の名前。 この名前を使用して、SQL文でUDFを参照できます。 関数名はグローバルに一意である必要があり、関数の作成後に変更することはできません。
所有者
このパラメーターの値は自動的に表示されます。
クラス名
必須。 関数を実装するクラスの名前。
説明リソースタイプがPythonの場合、Pythonリソース名. クラス名形式でクラス名を入力します。 を含めないでください。. pyリソース名の拡張子。
リソース
必須。 リソースのリスト。 ファジーマッチモードでワークスペース内の既存のリソースを検索できます。
複数のリソースをコンマ (,) で区切ります。
説明
関数の説明。
式構文
UDFの構文。 例:
test。パラメーターの説明
サポートされている入出力パラメーターのデータ型の説明。
戻り値
必要に応じて、 返される値。The value to return. 例: 1.
例
必要に応じて、 関数の例です。
上部ツールバーの
 アイコンをクリックして、UDFを保存します。
アイコンをクリックして、UDFを保存します。 UDFをコミットします。
 上部のツールバーのアイコン をクリックします。
上部のツールバーのアイコン をクリックします。では、送信ダイアログボックスで、情報を入力します。説明を変更するフィールドを選択します。
確認. をクリックします。
SQL文で作成したUDFを使用して、IPアドレスの位置情報を照会します。
ワークフローを右クリックし、.を選択します。
では、ノードの作成ダイアログボックスで、[名前] フィールドにノード名を入力し、確認. をクリックします。
ODPS SQLノードの [設定] タブで、次のステートメントを入力します。
select * from ipresource WHERE ipint('192.0.2.0') >= start_ip AND ipint('192.0.2.0') <= end_ip アイコンをクリックしてコードを実行します。
アイコンをクリックしてコードを実行します。操作ログ結果を表示します。