このトピックでは、ワークフローを作成し、ワークフローにノードを作成し、依存関係を設定する方法について説明します。ワークフローが作成されると、データ開発機能を使用して、ワークスペース内のデータを分析および計算できます。
前提条件
開始する前に、ワークスペースにビジネスデータテーブル bank_data と結果テーブル result_table が作成されていることを確認してください。ビジネスデータテーブルにはデータが含まれている必要があります。詳細については、「テーブルの作成とデータのアップロード」をご参照ください。
背景情報
DataWorks のデータ開発機能は、ワークフローを使用してデータを処理し、依存関係を管理します。ワークフロー内でノードをドラッグアンドドロップすることで、ノードの依存関係を設定できます。ワークスペースには複数のワークフローを作成できます。詳細については、「ワークフローの作成」をご参照ください。
ワークフローの作成
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、データスタジオへ移動 をクリックします。
データ開発 ページで、ポインターを
 アイコンに移動し、ワークフローの作成 をクリックします。
アイコンに移動し、ワークフローの作成 をクリックします。ワークフローの作成 ダイアログボックスで、ワークフロー名 と 説明 を入力します。
作成 をクリックします。
ノードの作成と依存関係の設定
ワークフローにゼロロードノード (start) と ODPS SQL ノード (insert_data) を作成します。次に、insert_data が start に依存するように依存関係を設定します。
ゼロロードノードは、ワークフローの実行中にどのデータにも影響を与えないコントロールノードです。子孫ノードに対する運用保守 (O&M) コントロールにのみ使用されます。
他のノードがゼロロードノードに依存している場合、O&M エンジニアが手動でゼロロードノードを失敗に設定すると、その未実行の子孫ノードはトリガーされません。O&M 中に、これにより不正な上流データが伝播するのを防ぎます。
ワークフローでは、ゼロロードノードの先祖ノードは通常、ワークスペースのルートノードです。ワークスペースのルートノードは
ワークスペース名_rootというフォーマットを使用します。DataWorks は、ワークスペース名.ノード名 という構造を使用して、各ノードの出力を自動的に追加します。ワークスペース内の 2 つのノードが同じ名前を持つ場合、いずれかのノードの出力を変更する必要があります。
ワークフロー全体を制御するために、ルートノードとしてゼロロードノードを作成します。ワークフローを次のように設計します:
ワークフロー名をダブルクリックして開発パネルに移動します。全般 > ゼロロードノード をクリックします。
仮想ノード を右側の開発パネルにドラッグすることもできます。

ノードの作成 ダイアログボックスで、パス を選択し、ノード名 に start を入力し、確認 をクリックします。
同じ方法で ODPS SQL ノードを作成し、insert_data という名前を付けます。
線をドラッグして、start ノードを insert_data ノードの先祖ノードとして設定します。

ゼロロードノードの上流依存関係の設定
ワークフローでは、ゼロロードノードは通常、ワークフロー全体を制御するコントローラーとして機能し、ワークフロー内の他のすべてのノードの先祖ノードとなります。
ワークスペースのルートノード は、通常、ゼロロードノードの 先祖ノード です:
ゼロロードノード名をダブルクリックして、ノードの編集ページを開きます。
ノードの編集ページの右側で、スケジューリング をクリックします。
依存関係 エリアで、ワークスペースのルートノードを使用 をクリックして、ワークスペースのルートノードをゼロロードノードの先祖ノードとして設定します。
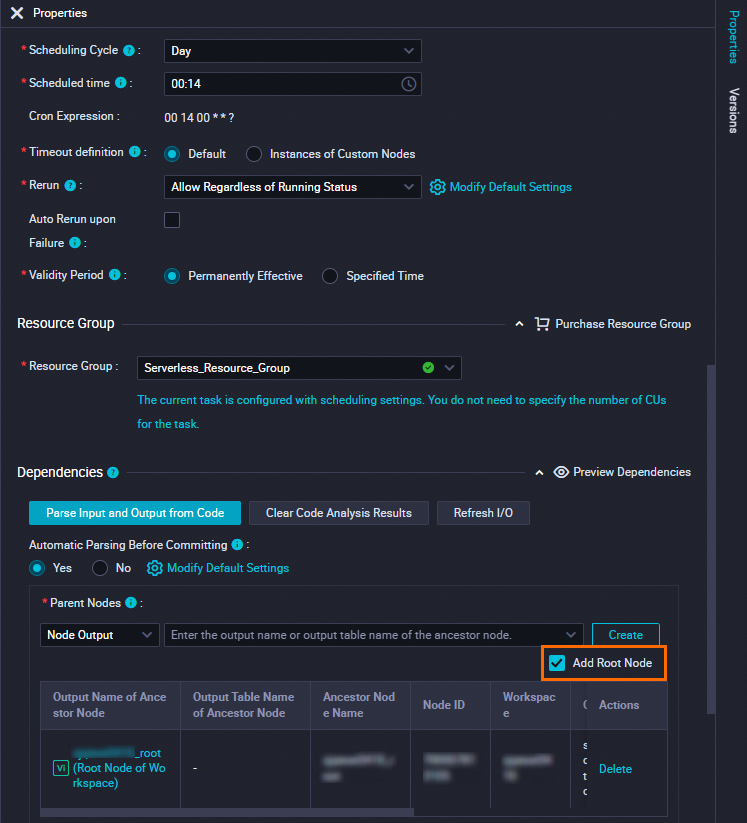
ノードを保存してコミットします。
重要ノードをコミットする前に、ノードの 再実行 と 親ノード のプロパティを設定します。
ツールバーの
 アイコンをクリックしてノードを保存します。
アイコンをクリックしてノードを保存します。ツールバーの
 アイコンをクリックします。
アイコンをクリックします。コミット ダイアログボックスで、変更の説明 を入力します。
確認 をクリックします。
ODPS SQL ノードの編集と実行
このセクションでは、insert_data ODPS_SQL ノードで SQL コードを使用して、さまざまな学歴を持つ住宅ローンを組んでいる独身者の数をクエリし、その結果を保存する方法について説明します。これらの結果は、子孫ノードでさらなる分析や表示に使用できます。
ODPS SQL ノードのエディターを開き、次のコードを入力します。
構文の詳細については、「SQL の概要」をご参照ください。
INSERT OVERWRITE TABLE result_table -- result_table テーブルにデータを挿入します。 SELECT education , COUNT(marital) AS num FROM bank_data WHERE housing = 'yes' AND marital = 'single' GROUP BY education;コード内の bank_data を右クリックし、入力の削除 を選択します。
「テーブルの作成とデータのアップロード」で作成された bank_data テーブルは、定期的にスケジュールされたノードによって生成されるものではありません。ノードがこのようなテーブルからデータを選択する場合、コードエディターでテーブル名を右クリックして入力を削除できます。また、コードの先頭にルールコメントを追加することもできます。これにより、自動パーサーがこの依存関係を識別するのを防ぎます。
 説明
説明DataWorks のスケジューリングの依存関係により、ノードはスケジュールされた先祖ノードによって定期的に更新されるテーブルデータを取得できます。これにより、下流のデータ取得が正しく行われることが保証されます。したがって、プラットフォームは DataWorks のスケジューリングシステムによって更新されないテーブルを監視できません。ノードが select 文を使用して、定期的にスケジュールされたノードによって生成されないテーブルからデータをクエリする場合、select 文によって自動的に生成された先祖ノードの依存関係を手動で削除する必要があります。
ツールバーの
 アイコンをクリックしてコードを保存します。
アイコンをクリックしてコードを保存します。 アイコンをクリックします。
アイコンをクリックします。コードが実行された後、ページの下部で実行ログと結果を表示できます。
ワークフローのコミット
ODPS_SQL ノード insert_data を実行してデバッグした後、ワークフローページに戻ります。
 アイコンをクリックします。
アイコンをクリックします。コミット ダイアログボックスで、コミットするノードを選択し、変更の説明 を入力し、強制変更 するかどうかを選択し、I/O の不整合に関するアラートを無視 を選択します。
コミット をクリックします。
ワークフローがコミットされた後、ワークフロー の下のノードリストでノードのコミットステータスを表示できます。ノード名の左側に
 アイコンが表示されている場合、ノードはコミットされていません。
アイコンが表示されている場合、ノードはコミットされていません。 アイコンが表示されている場合、ノードはコミットされています。
アイコンが表示されている場合、ノードはコミットされています。
次のステップ
ワークフローの作成とコミットの方法を学習しました。次のチュートリアルに進み、同期タスクを作成してさまざまなタイプのデータソースにデータを書き込む方法を学びます。詳細については、「同期タスクの作成」をご参照ください。