PolarDB for MySQL は、そのインメモリ列インデックス (IMCI) に基づくネイティブの全文検索機能を提供します。既存のテーブルに直接、全文検索インデックスを作成できます。MATCH 関数と最適化された LIKE 演算子を使用して、ミリ秒単位であいまいクエリを実行できます。Elasticsearch などの外部検索エンジンソリューションとは異なり、IMCI はデータとインデックス間のトランザクションの一貫性を保証します。このアプローチにより、データ同期の遅延が回避され、全体的なアーキテクチャが簡素化されます。
コアコンセプト
PolarDB IMCI の全文検索を理解するには、以下の基本概念を把握する必要があります:
概念 | 説明 |
ドキュメント | インデックス作成可能な生データの単位。PolarDB IMCI では、列ストア内のデータの行を指します。 |
Term | トークナイザーによってドキュメントから抽出される基本的な言語単位。インデックス作成とクエリの最小単位です。 |
トークナイザー | 生のテキストを term のシーケンスに分割するコンポーネント。PolarDB IMCI は、さまざまな言語やビジネスシナリオに合わせて、 |
転置インデックス | フルテキスト検索のコアデータ構造。各 term とそれを含むドキュメントのリストとの間のマッピングを記録します。term 辞書とポスティングリストで構成され、テキストクエリを高速化します。 |
Term 辞書 | 高速な検索を提供するすべてのタームのコレクション。PolarDB IMCI は、有限状態トランスデューサ (FST) アルゴリズムを使用して辞書を構築します。クエリ時間の計算量は O(len(term)) であり、最小限のスペースしか使用しません。 |
ポスティングリスト | 特定のタームを含むすべてのドキュメント ID のリスト。IMCI では、ドキュメント ID は 64 ビットの行番号です。PolarDB IMCI は、Roaring Bitmap (RBM) アルゴリズムを使用してポスティングリストを圧縮および計算し、疎なデータと密なデータの両方で優れたパフォーマンスを発揮します。 |
次の表は、組み込みの PolarDB IMCI ソリューションと外部の「データベース + Elasticsearch」ソリューションを比較したものです。
比較項目 | PolarDB IMCI 全文検索 | 「データベース + Elasticsearch」ソリューション |
データの一貫性 | 強い一貫性。インデックスの更新とデータの書き込みは、原子性、一貫性、分離性、永続性 (ACID) の原則に従い、同じトランザクション内で完了します。データ遅延や不整合のリスクはありません。 | 結果整合性。データはデータベースから Elasticsearch に同期する必要があり、同期遅延が発生します。リアルタイムデータとトランザクションの原子性は保証されません。 |
アーキテクチャの複雑さ | シンプル。この機能はデータベースに組み込まれています。新しいコンポーネントは不要で、アーキテクチャは明確です。 | 複雑。別の Elasticsearch クラスターとデータ同期パイプラインをデプロイして維持する必要があり、システムの異種性が増します。 |
クエリメソッド | 統一。構造化データと非構造化データの両方を含むすべてのデータは、標準 SQL を使用してクエリされます。 | 断片的。クエリには SQL と Elasticsearch DSL の両方を使用する必要があります。これにより、最初に Elasticsearch をクエリし、次にデータベースをクエリするという 2 段階のクエリが頻繁に発生します。これにより、遅延とコードの複雑さが増します。 |
O&M コスト | 低い。PolarDB の運用保守および高可用性 (HA) システムを再利用します。追加の専門的な運用保守スキルやサーバーリソースは必要ありません。 | 高い。別のサーバーリソースと専門的な Elasticsearch 運用保守スキルが必要です。データのコピーを 2 つ保存すると、ストレージコストも増加します。 |
仕組み
PolarDB IMCI の全文検索機能は、転置インデックス技術に基づいています。非構造化テキストデータを構造化インデックスに変換し、キーワードクエリのパフォーマンスを大幅に向上させます。コアプロセスを次の図に示します:
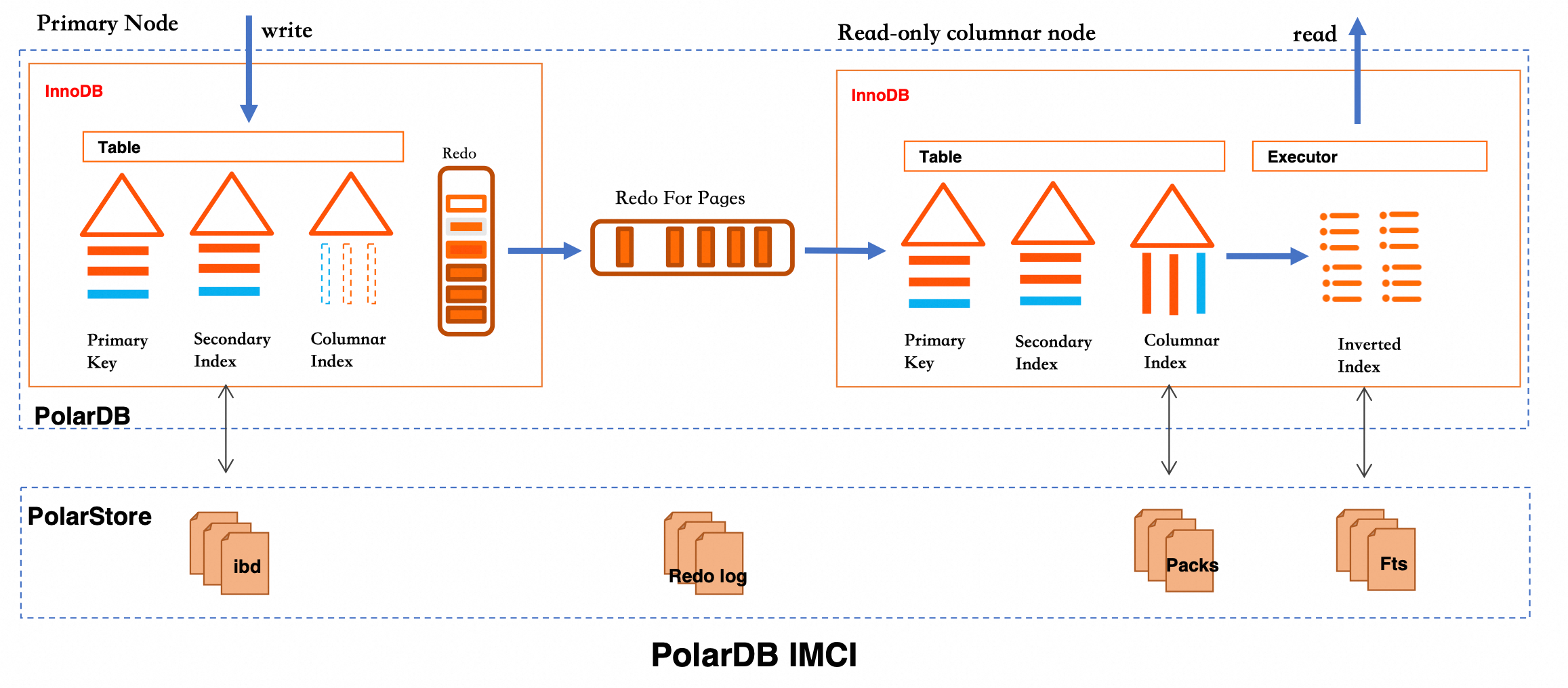
データが書き込まれると、InnoDB テーブルのコンテンツは列ストアインデックスを介して PolarStore の Pack ファイルに同期されます。クエリフェーズでは、エグゼキュータは列ストアデータに基づいて転置インデックスを構築し、Fts ファイルを使用して効率的な全文マッチングを実行します。このアーキテクチャは、行ストアと列ストアを連携させ、書き込みパフォーマンスと複雑なクエリ機能のバランスを取ります。
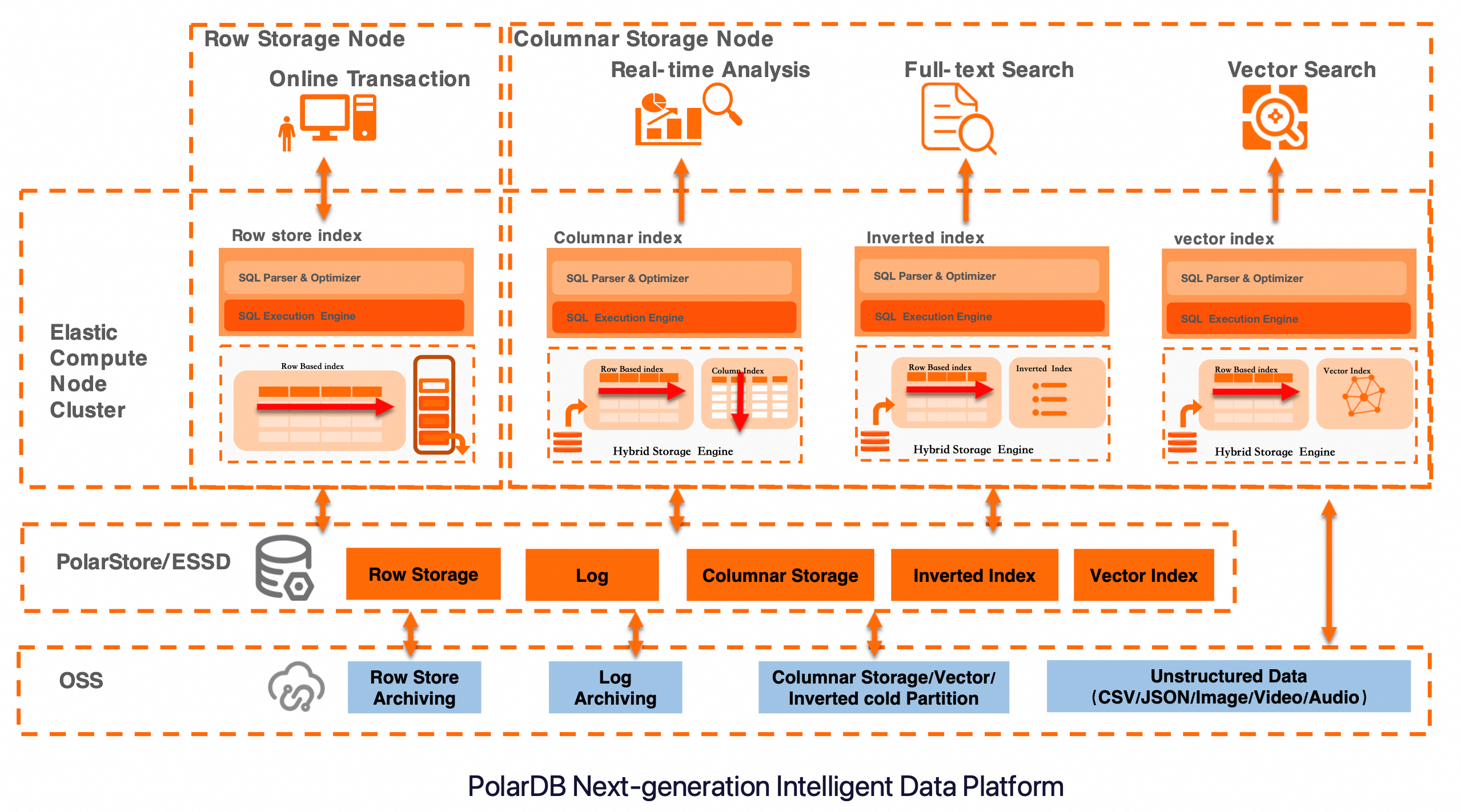
PolarDB IMCI は、複数のクエリモードをサポートする統一されたハイブリッドストレージアーキテクチャを使用します。図に示すように、全文検索はハイブリッドストレージエンジンに依存して、効率的なテキスト検索のための転置インデックスを構築および維持します。また、エラスティックコンピューティングノードと階層化ストレージを組み合わせて、高スループットの書き込みと低遅延のクエリのバランスを取ります。さらに、組み込みのベクトルインデックス機能を統合して、テキストとベクトルのマルチモーダル複合検索をさらにサポートします。このアーキテクチャは、E コマースの製品検索、ログ分析、ナレッジベース検索などのシナリオで広く使用されています。オンライン トランザクショナル プロセッシング (OLTP)、リアルタイム分析、全文検索、ベクトル検索を統合したワンストップのデータサービスプラットフォームをユーザーに提供します。
トークナイザー
トークン化は、テキストをタームに分割するプロセスです。これは全文検索の基盤です。適切なトークナイザーを選択することは、検索の精度とパフォーマンスにとって非常に重要です。IMCI は次のトークナイザーをサポートしています:
トークナイザー | 説明 |
token | スペースや句読点などの非英数字に基づいてテキストを分割します。スペースを区切り文字として使用する英語などの言語に適しています。 |
ngram | テキストを、事前定義された文字長 (n) の term の連続したシーケンスに分割します。 |
jieba |
|
ik |
|
json | JSONPath 式を使用して、JSON オブジェクトから特定のキーと値のペアまたは配列要素をタームとして抽出します。JSON データの詳細な検索に使用されます。 |
さらに、PolarDB IMCI は、トークン化の結果をテストするための `dbms_imci.fts_tokenize` 関数を提供します。この関数は、すべてのトークナイザーとそれに対応するプロパティをサポートします。トークン化の結果が異なると、MATCH と LIKE の間で予期しない、または一貫性のないクエリ結果が生じる可能性があります。そのような場合は、この関数を使用してトークン化の結果を検証できます。
ポスティングリスト
ポスティングリストは、本質的にはドキュメント ID のセットです。重要な技術は、ストレージのための効率的な圧縮と、積集合などの高性能な計算です。
PolarDB IMCI の全文検索インデックスでは、ポスティングリストは、特定のタームを含む列ストアインデックスの行番号のセットを、対応するターム頻度 (オプション) およびドキュメント頻度 (オプション) とともに格納します。各タームには、対応するポスティングリストがあります。
IMCI は、ドキュメント ID のセットであるポスティングリストを圧縮および計算するために、Roaring Bitmaps (RBM) アルゴリズムを使用します。
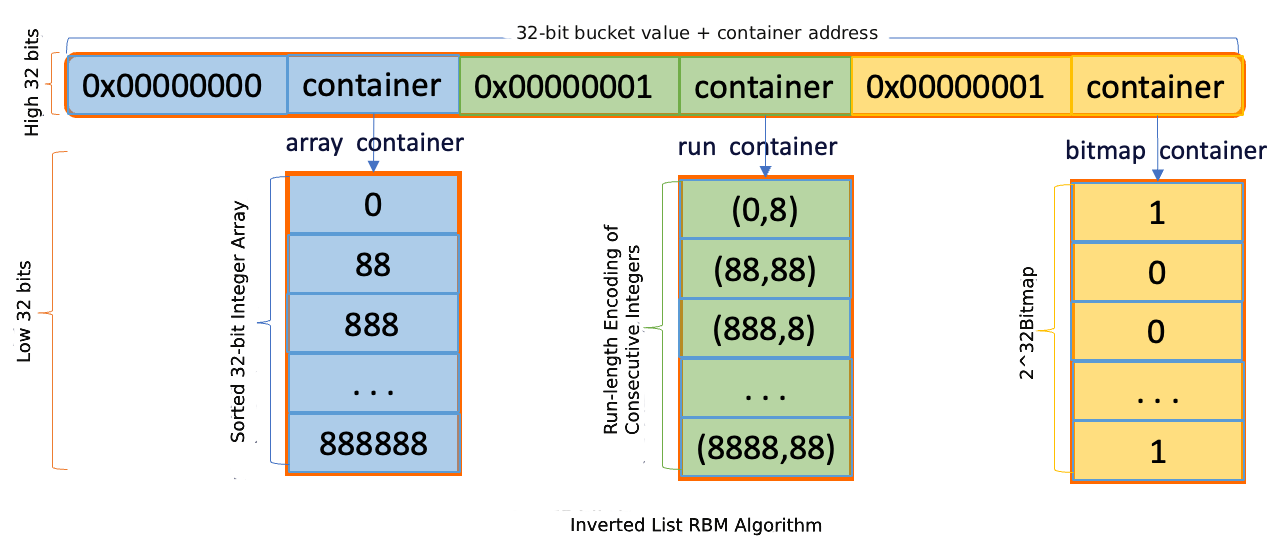
RBM の実装は CRoaring ライブラリに基づいており、データ密度に基づいてストレージ戦略を動的に選択します。
ポスティングリスト内のドキュメント ID の数が事前設定されたしきい値より少ない場合、ストレージに
std::arrayを使用します。数がしきい値を超えると、
roaring::Roaring64Map型に切り替えて、高い圧縮率を維持しながら大規模な疎または密なデータを処理します。
パフォーマンスの特徴:
インデックス構築中に O(logN) の複雑さでの検索をサポートします。
SIMD 命令を使用して、積集合や和集合などのセット操作を高速化します。
データがディスクに書き込まれる際のスペースの再編成をサポートし、断片化を削減します。
クエリ中に高速なフィルタリングとイテレータの最適化のために
minimum/maximum値を使用します。
Term 辞書
転置インデックスのコアとなる考え方は、辞書を使用してタームに対応するポスティングリストをすばやく見つけることです。タームをポスティングリストにマッピングする辞書の設計は非常に重要です。一般的な設計には、トライ木、B+ 木、有限状態トランスデューサ (FST) があります。
IMCI は、FST アルゴリズムを使用してターム辞書を構築し、時間とスペースの効率のバランスを取ります。
スペース効率: term の共通のプレフィックスとサフィックスを共有することで、ストレージスペースを効果的に圧縮します。
時間効率: term のクエリの時間計算量は O(L) です。ここで、L は term の長さです。
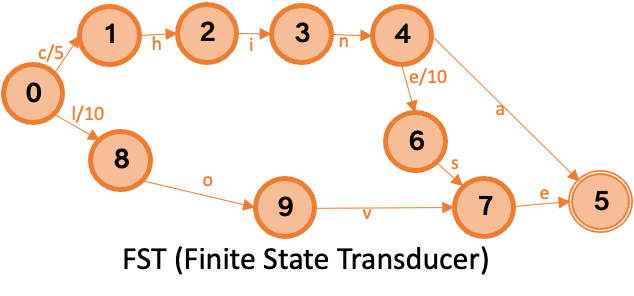
たとえば、順次入力されるターム China、Chinese、love について、それぞれのポスティングリストのアドレスオフセットが 5、10、15 であると仮定します。結果として得られる辞書を次の図に示します。この図は、FST がプレフィックスとサフィックスを共有することでスペースを節約するだけでなく、異なる遷移がそれぞれ一意の関連値を持つことを保証することを示しています。クエリは初期状態 0 から始まり、ターム内の各文字の出力ノードをたどります。出力ノードが存在する場合、関連値が累積されます。`Chinese` の場合、最終的な関連値は 15 であり、最後の文字は終了状態にあります。これは、タームが辞書に存在することを意味します。さらに、FST のプレフィックス計算は文字ではなくバイトに基づいているため、UTF-8 などのエンコーディングもサポートします。
インデックス構築
PolarDB IMCI は、シングルパス インメモリ インデックス作成 (SPIMI) アルゴリズムを使用して転置インデックスを構築します。データを一度スキャンし、トークン化し、ターム辞書とポスティングリストをバッチで生成します。このプロセスは、ローカルインデックスの効率的でメモリ制御された構築をサポートします。
全文検索インデックスを構築する際、PolarDB IMCI は対応する列から列ストアデータを継続的に読み取ります。次に、データの各行をトークン化してタームのセットを取得します。各タームとそれに対応する行番号がハッシュテーブルに追加されます。メモリ使用量が累積されます。セグメントサイズのしきい値を超えると、ハッシュテーブル内のタームとポスティングリストを使用して辞書が構築されます。その後、メモリがリセットされ、すべての列ストアデータが処理されるまで次の行が処理されます。ハッシュテーブル (std::unordered_map) から辞書 (FST) を構築する主なプロセスは次のとおりです:まず、ハッシュテーブルがターム (キー) でソートされます。次に、ハッシュテーブル内のすべてのポスティングリストが順番にディスクにシリアル化され、それらの相対的なディスクオフセットが記録されます。次に、タームとそのポスティングリストのオフセットが追加され、FST アルゴリズムを使用して辞書が構築されます。最後に、辞書が圧縮されてディスクに書き込まれ、セグメント情報 (辞書サイズ、辞書開始アドレス、ポスティングリスト開始アドレス、行番号範囲を含む) がメタデータに記録されます。
PolarDB は、外部ソートを回避するためにグローバル辞書を構築しません。グローバル辞書では、プレフィックスベースの分割とタームインデックスの構築も必要になります。代わりに、列ストアの追記専用モデルを考慮して、軽量な構築方法を使用します。次の図に示すように、メモリのしきい値に基づいて複数のローカル辞書を構築します。メモリが十分にある場合は、メモリのしきい値をできるだけ大きくすることで、同じタームのより多くのインスタンスが同じ転置セグメントに収まるようになり、スペースの節約とクエリパフォーマンスの向上に役立ちます。
上記で説明した通常のインデックス構築プロセスに加えて、PolarDB IMCI の全文検索インデックスは、システムがアイドル状態のときに転置インデックスの非同期マージもサポートします。 PolarDB IMCI の列ストアインデックスは、標準テーブルのセカンダリインデックスとして機能します。挿入中、データは常に挿入順に列ストアストレージエンジンに追加されます。削除中は、削除マーク方式が使用されます。更新は、削除とそれに続く挿入に変換されます。`array InsertMask` を使用して、可視性チェックのために列ストアデータ内の各行の挿入バージョンをマークします。`lsm DeleteMask` は、既存の行を削除対象としてマークします。コンパクションやリサイクルなどの非同期バックグラウンド操作は、データの再編成とスペースの再利用を実行します。 列ストアエンジンの一部として、PolarDB IMCI の全文検索インデックスは、非同期の転置コンパクションタスクも使用して、削除マークが付けられたデータを定期的にクリーンアップし、スペースを効果的に節約し、クエリパフォーマンスを向上させます。転置マージは、転置セグメントレベルで行われます。複数の転置セグメントが新しいセグメントにマージされますが、元のセグメントは変更されません。このプロセスにより、クエリに使用される転置スナップショットオブジェクトが無効になるのを防ぎます。マージが完了すると、新しい転置スナップショットが生成され、新しいクエリは新しいスナップショットを使用します。 ローカルインデックス構築方法と削除マーク設計のおかげで、大規模なバッチ挿入はグローバルな再構築をトリガーしません。増分部分のみを構築する必要があります。更新コストも、削除マークを付けるだけで済むため非常に低くなります。頻繁な更新があるシナリオでも、書き込みパフォーマンスは影響を受けません。さらに、バックグラウンドでの定期的な非同期マージにより、よりコンパクトな転置インデックスを作成してクエリパフォーマンスを向上させることができます。列ストアの同時クエリ機能と組み合わせることで、このアプローチは、大規模なデータシナリオでもミリ秒レベルの応答要件を満たすことができます。
インデックス取得
PolarDB IMCI の全文検索インデックスは、公式の MySQL MATCH 関数と LIKE 演算子をサポートしています。
MATCH関数PolarDB IMCI では、行ストアに全文検索インデックスが作成されているかどうかに関係なく、すべての全文検索に
MATCH関数を使用できます。行ストアにインデックスが作成されていない場合、クエリは直接列ストアノードにルーティングされます。インデックスが存在する場合、クエリはコスト評価に基づいてインテリジェントにルーティングされます。最適化フェーズでの補助テーブルの同期やキャッシュの読み込みなど、MySQL ネイティブの全文検索インデックスでの時間のかかる操作が列ストアのパフォーマンスに影響を与えないように、PolarDB はクエリルーティングの早い段階でこれらのプロセスをスキップします。実行中、IMCI は 2 つの検索方法を提供します:
FtsTableScan演算子とMATCH式です。前者は転置インデックスを介して一致する行を直接取得し、高選択性のシナリオに適しています。後者は行番号に基づいてインデックスを検索し、先行する条件によってすでに大量のデータが除外されている状況に適しています。これら 2 つの方法の実行効率は、他の述語のフィルタリング効果に依存します。したがって、列ストアオプティマイザーは、統計に基づいてフィルタリング率を推定し、最適な戦略を動的に選択します。演算子方式が選択されると、システムは自動的にMATCH関数をFtsTableScan + Filter演算子に書き換えます。全文検索インデックスは非同期で構築されるため、新しいデータの可視性に短い遅延が発生する可能性があります。デフォルトでは、列ストアエグゼキュータは、インデックス付けされていないデータに対してフルテーブルスキャンを実行してクエリ結果を補完し、完全性を保証します。また、このステップをスキップするかどうかを制御するパラメーターも提供されており、高い同時実行性、大容量データのシナリオでパフォーマンスと一貫性の間の柔軟なトレードオフを可能にします。ユーザーは、インデックス構築パラメーターを調整してデータ同期頻度を高速化し、フルスキャンの範囲を縮小して、クエリ効率をさらに向上させることもできます。
LIKE高速化特定の条件下で、PolarDB IMCI は
LIKEとMATCHの間の変換をサポートします。LIKEをMATCHに変換するのは、主にクエリを高速化して、フルテーブルスキャンでの行ごとの文字列比較のオーバーヘッドを削減するために使用されます。現在、この変換は、列ストアの全文検索インデックスが
ngramトークナイザーを使用し、ngramトークンの長さがLIKEパターン文字列の長さ以下である場合にのみ有効です。これらの条件下で、オプティマイザーはLIKE '%abc%'のような述語をFtsTableScan + Filter演算子に書き換え、転置インデックスを使用して候補行をすばやくフィルタリングできます。ただし、
ngramトークン化のマッチングメカニズムとLIKE演算子の間にはセマンティックな違いがあります。たとえば、"abbc"はab、bb、bcにトークン化されます。これは"abc"のabとbcと重複し、誤って一致として識別される可能性があります。したがって、元のLIKE式は、結果の正確性を保証するために、後続のフィルター条件として正確な検証のために保持されます。このメカニズムは、セマンティックの正確さと実行効率を効果的にバランスさせながら、クエリのパフォーマンスを大幅に向上させます。
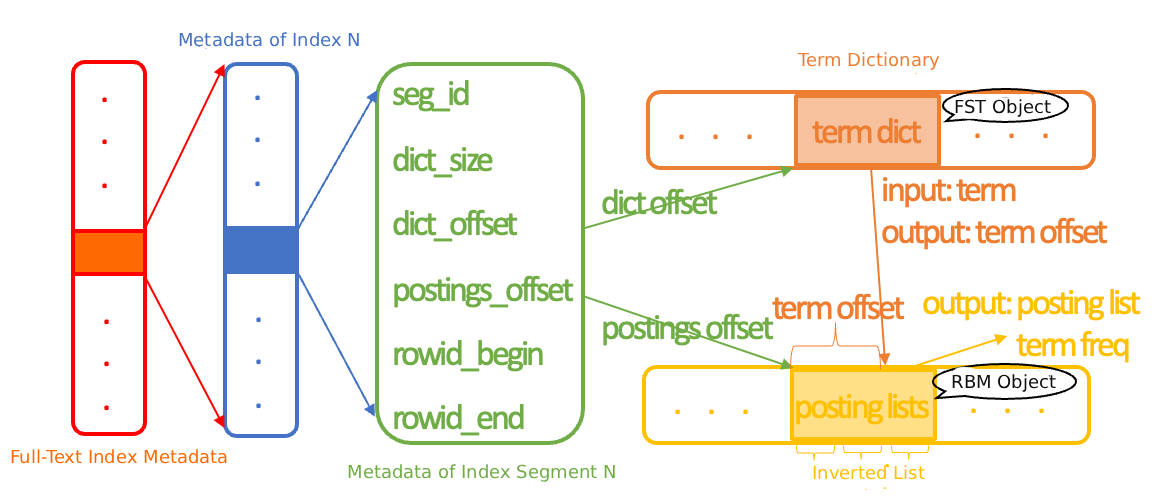
PolarDB IMCI の転置インデックスは、複数の転置セグメントで構成されています。各セグメントには、独立したメタデータ、ターム辞書、および一連のポスティングリストが含まれており、各タームは 1 つのポスティングリストに一意に対応します。辞書とポスティングリストの開始アドレスを記録するメタデータは小さく、デフォルトでメモリに常駐してインデックスアクセスを高速化します。
インデックス検索はセグメントごとに実行されます。主なプロセスには、辞書データの読み取り、FST オブジェクトの構築、辞書内のターゲットタームの検索、そして対応するポスティングリストを読み取って RBM オブジェクトを構築することが含まれます。
2 つの特定のクエリモードがあります。
演算子クエリ:すべての転置セグメントのメタデータを走査し、辞書の開始アドレスを取得し、辞書データをロードして辞書オブジェクトを構築し、ターゲットタームを検索します。一致が見つかった場合、タームのポスティングリストオフセットとセグメントの開始アドレスを組み合わせて、完全なポスティングリストオブジェクトを読み取ります。
式クエリ:行番号に基づいて行が属する転置セグメントのセットを決定し、メタデータ内の行番号範囲を使用してさらにフィルタリングします。次に、一致した転置セグメントに対して、演算子クエリと同様の辞書検索とポスティングリスト読み取りプロセスを実行します。
パフォーマンスを向上させるために、IMCI は辞書キャッシュ機能をサポートしています。独立した Least Recently Used (LRU) キャッシュメカニズムを使用し、スケジューリングモジュールがメモリクォータを動的に調整します。個々のポスティングリストは通常小さく、ほとんどが 1 回の 4 KB の I/O しか必要とせず、数も多いため、キャッシュヒット率と利点は限定的です。したがって、メモリリソースの浪費を避けるために、ポスティングリストのキャッシュはデフォルトで無効になっています。
この設計により、メモリ使用量と I/O オーバーヘッドを合理的にバランスさせながら、クエリ効率が保証されます。
シナリオ
PolarDB IMCI の全文検索機能は、テキストコンテンツの高速検索を必要とするさまざまなビジネスシナリオに適しています。
E コマースの商品検索とサイト内検索
E コマースプラットフォームでは、ユーザーはキーワードを使用して製品をすばやく見つけることがよくあります。
LIKEを使用した従来のあいまい一致はパフォーマンスが悪く、高い同時実行性下での応答時間の要件を満たすことができません。外部の Elasticsearch に依存するソリューションは高速化できますが、データ同期の遅延により、検索結果に掲載が終了した、価格が変更された、または在庫切れの製品が含まれることが多く、ユーザーエクスペリエンスに影響を与えます。PolarDB IMCI は、ネイティブの全文検索機能を提供します。製品のタイトル、説明、属性などのテキストフィールドに効率的な転置インデックスを構築できます。クエリはデータベース内で直接キーワードマッチングを実行するため、システム間の遅延が回避され、検索結果が価格や在庫などの製品のリアルタイムのステータスと強く一致することが保証されます。これにより、検索できるものは購入できることが保証されます。
ログ分析と可観測性
運用保守およびトラブルシューティング中、開発者および運用保守エンジニアは、大量のログからエラースタックをすばやく特定したり、リクエストリンクを追跡したり、異常な動作を分析したりする必要があります。従来の ELK スタックは強力ですが、コンポーネントが多く、デプロイが複雑で、メンテナンスコストが高く、データの書き込みから検索可能になるまでの間に顕著な遅延があります。
PolarDB IMCI を使用すると、ログテーブルの
messageまたはcontentフィールドに直接全文検索インデックスを作成し、標準 SQL を使用してミリ秒レベルのログ検索を実現できます。追加のログ分析プラットフォームを設定することなく、インタラクティブなクエリとコンテキスト追跡を実行できます。これにより、技術スタックが大幅に簡素化され、ストレージと運用保守の負担が軽減され、問題の特定がより効率的になります。ドキュメントとナレッジベースの取得
社内のナレッジベース、製品マニュアル、よくある質問、またはヘルプセンターでは、ユーザーが必要な情報をすばやく見つけられるようにすることが中核的な要件です。外部の検索エンジンに依存する場合、デュアルライトロジックを維持する必要があるだけでなく、非同期のコンテンツ更新のリスクもあります。
PolarDB IMCI でドキュメント本文に全文検索インデックスを作成し、
jiebaやikなどの中国語トークナイザーを使用してトークン化の精度を向上させることで、コンテンツのストレージと検索を同じデータベース内で統合できます。コンテンツは更新後すぐに検索可能になります。権限モデルは既存のシステムを再利用し、追加の同期メカニズムは必要ありません。これにより、更新がすぐに有効になることが保証されます。ユーザーペルソナと行動分析
効果的なユーザーエンゲージメントは、ユーザーのコメント、タグ、投稿から興味や好みを抽出するなど、非構造化テキストの詳細な分析に依存します。従来の方法では、データをデータウェアハウスや分析システムにエクスポートする必要があり、複雑で時間のかかるプロセスです。
PolarDB IMCI は、JSON フィールドで
jsonトークナイザーを使用するか、長いテキストフィールドでjiebaトークナイザーを使用してインデックスを構築することをサポートします。これにより、年齢や地域などの構造化属性と、「アウトドアスポーツが好き」や「コストパフォーマンスを気にする」などのテキストセマンティクスを 1 つの SQL クエリで組み合わせて複合分析を行うことができます。データ移行なしでリアルタイムのユーザーセグメンテーションと行動分析を実行でき、詳細な運用とパーソナライズドレコメンデーションに役立ちます。
パフォーマンス テスト
ESRally は、Elastic が公式にリリースした Elasticsearch のベンチマークツールです。このセクションでは、その組み込みの http_logs データセットを使用して、PolarDB IMCI 列ストア全文検索インデックスの検索パフォーマンスをテストおよび評価します。また、PolarDB for MySQL の IMCI 機能で複雑な E コマースクエリを高速化するソリューションを参照して、実際のシナリオでのパフォーマンスをさらに理解することもできます。
データセットの準備
データセットの取得:
データセットの詳細については、「Elasticsearch Rally Hub」をご参照ください。以下にデータセットの取得方法を示します。約 1.7 GB の rally-track-data-http_logs.tar という名前の圧縮パッケージが取得されます。展開後のサイズは約 32 GB で、合計 2 億 4700 万行です。
git clone https://github.com/elastic/rally-tracks.git cd rally-tracks ./download.sh http_logsテーブルの作成:
データセットには、MySQL の JSON 型と互換性のない JSON データが数行含まれています。varchar(512) を使用して JSON データを格納できます。データをインポートした後、仮想列を使用して JSON からリクエストフィールドを解析できます。
CREATE TABLE http_logs( logs varchar(4096) );データのインポート:
LOAD DATA を使用してデータセットをデータベースにインポートできます。
LOAD DATA INFILE '/home/xxx/http_logs/documents-181998.json' INTO TABLE http_logs COLUMNS TERMINATED BY '\n'; ... ...フィールドの追加:
仮想列を使用して JSON からリクエストフィールドを解析し、全文検索インデックスのテストに使用できます。
ALTER TABLE http_logs ADD COLUMN request varchar(1024) AS (CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END);列ストアインデックスの作成:
列ストア転置インデックスは、列ストアインデックスの一部です。最初に列ストアインデックスを作成する必要があります。
ALTER TABLE http_logs comment 'columnar=1';転置インデックスの作成:
DDL 文を使用して列のコメントを変更し、列ストア転置インデックスを作成できます。DDL 文は数秒で完了し、転置インデックスはバックグラウンドで非同期に構築されます。
ALTER TABLE http_logs modify COLUMN request varchar(1024) AS (CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END) comment 'imci_fts(type=2 mode=1)';転置インデックスの表示:
作成後、次のコマンドを実行して NUM_PACKS と NEXT_PACK_ID を表示できます。NUM_PACKS は列ストアデータブロックの数を示し、NEXT_PACK_ID は転置インデックスが構築されたデータブロック番号を示します。2 つの値が近い場合、転置インデックスは構築されています。
SHOW imci indexes; SHOW imci indexes fulltext;
パフォーマンス テスト
転置インデックスが構築された後、MATCH 関数を使用して、頻度の高いものから低いものまでのタームの検索パフォーマンスをテストできます。次のセクションでは、同じデータセットでの LIKE、MATCH、および Doris MATCH_ANY のクエリパフォーマンスの比較を示します。
次の表は、ホットデータでのシングルスレッドテストの結果を示しています。
クエリ | 高頻度 term | 比較的高頻度の term | 比較的低頻度の term | 低頻度 term |
LIKE | 1 分 21.96 秒 | 1 分 18.44 秒 | 1 分 24.59 秒 | 1 分 31.19 秒 |
SMID LIKE | 25.46 秒 | 22.80 秒 | 21.98 秒 | 21.60 秒 |
MATCH (独自の FTS ライブラリ) | 2.43 秒 | 0.25 秒 | 0.01 秒 | 0.00 秒 |
Doris MATCH_ANY (CLucene ライブラリ) | 3.49 秒 | 0.24 秒 | 0.03 秒 | 0.03 秒 |
上の表に示すように、MATCH は LIKE よりも大幅な改善を提供し、データがホットかコールドかにはほとんど影響されません。
よくある質問
Q1:PolarDB IMCI の全文検索は、MySQL InnoDB のような従来のデータベースの組み込み全文検索インデックスと比較してどのような利点がありますか?
PolarDB IMCI には、パフォーマンス、機能、スケーラビリティの点で利点があります。
パフォーマンス:列ストアとベクトル化実行エンジンに基づいており、FST や RBM などのアルゴリズムと組み合わせることで、そのクエリパフォーマンスは従来の行ストアインデックスよりも優れています。高い同時実行性、大規模データシナリオで高速な応答を提供できます。
機能:
jiebaやikなどの中国語トークナイザーと、jsonトークナイザーが組み込まれており、複雑なビジネスシナリオのニーズに対応します。書き込みパフォーマンスへの影響:最適化されたインデックス構築と更新メカニズムは、高頻度の書き込み (INSERT/UPDATE) シナリオでのパフォーマンスへの影響が、従来のデータベースの全文検索インデックスよりもはるかに小さいです。
水平方向のスケーラビリティ:PolarDB のストレージとコンピューティングが分離されたアーキテクチャの恩恵を受け、優れた水平方向のスケーラビリティを備えています。
Q2: ビジネスデータに適したトークナイザーを選択するにはどうすればよいですか?
データ型とクエリのニーズに基づいて選択します:
中国語テキストの処理:
jiebaまたはikトークナイザーを使用します。これらはセマンティックなトークン化を実行し、中国語検索の精度を向上させます。英語または記号で区切られたテキストの処理:
tokenトークナイザーを使用します。スペースや句読点に基づいてテキストを分割します。あいまい一致または任意の部分文字列検索の実装:
ngramトークナイザーを使用します。テキストをバイグラムやトライグラムなどの固定長のフレーズに分割し、非効率なLIKE '%keyword%'クエリの代替に適しています。JSON フィールド内の特定のコンテンツの検索:
jsonトークナイザーを使用します。現在、JSON 配列の値または JSON オブジェクトのキーに転置インデックスを作成することをサポートしています。
どのトークナイザーが最適かわからない場合は、dbms_imci.fts_tokenize 関数を使用して、さまざまなトークナイザーがサンプルテキストをどのように処理するかをプレビューできます。これにより、ビジネスの期待に最も合うトークン化戦略を選択するのに役立ちます。