Spark は、Java Database Connectivity (JDBC) コネクタを使用して PostgreSQL にアクセスすることをネイティブにサポートしています。一部のバージョンの Serverless Spark は、起動時に PostgreSQL JDBC ドライバーを自動的にロードします。これにより、Serverless Spark SQL セッション、Spark バッチ処理ジョブ、または Notebook を使用して、データを直接読み書きできます。
前提条件
Serverless Spark ワークスペースが作成されていること。詳細については、「ワークスペースの作成」をご参照ください。
PostgreSQL インスタンスが作成されていること。
セルフマネージド PostgreSQL インスタンス、または RDS for PostgreSQL や PolarDB for PostgreSQL などの Alibaba Cloud データベースを使用できます。
このトピックでは、Alibaba Cloud RDS for PostgreSQL インスタンスを例として使用します。詳細については、「RDS for PostgreSQL インスタンスをすばやく作成する」をご参照ください。
使用上の注意
JDBC ドライバーのバージョン要件:
以下のいずれかの Serverless Spark エンジンバージョンを使用する場合、PostgreSQL JDBC ドライバーを準備する必要はありません。Serverless Spark には、ドライバー (バージョン 42.7.6) が組み込まれています。
esr-4.4.0 以降
esr-3.4.0 以降
esr-2.8.0 以降
上記のバージョンよりも低いエンジンバージョンを使用する場合は、PostgreSQL JDBC Driver を手動でダウンロードし、OSS にアップロードして、[セッションマネージャー] の [Spark 設定] セクションに次のパラメーターを入力する必要があります。
spark.emr.serverless.user.defined.jars oss://<bucket>/path/to/postgresql-<version>.jar
ネットワーク構成: Serverless Spark と PostgreSQL サービス間のネットワーク接続が確立されていることを確認してください。詳細については、「EMR Serverless Spark と他の VPC 間のネットワーク接続を確立する」をご参照ください。
説明セキュリティグループルールを追加するときは、必要なポートを開いてください。この例では、TCP ポート
5432を開く必要があります。
手順
方法 1: SQL セッションを使用する
SQL セッションを作成します。 [セッションマネージャー] で SQL セッションを作成し、事前設定された [ネットワーク接続] を選択します。詳細については、「SQL セッションの作成」をご参照ください。
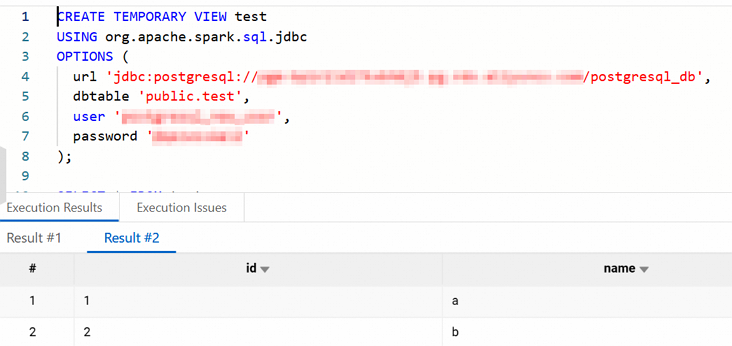
SQL ジョブを作成します。 [データ開発] で、 ジョブを作成し、テスト用に次の SQL 文を使用します。
CREATE TEMPORARY VIEW test USING org.apache.spark.sql.jdbc OPTIONS ( url 'jdbc:postgresql://<jdbc_url>/<database>', dbtable '<schema>.<table>', user '<username>', password '<password>' ); SELECT * FROM test;次の表にパラメーターを示します。
パラメーター
説明
urlJDBC 接続文字列。PostgreSQL ホストアドレス、ポート、データベース名が含まれます。
フォーマット
jdbc:postgresql://<jdbc_url>/<database>を使用し、プレースホルダーを実際の値に置き換えます。dbtable読み取るデータベーステーブルの名前。フォーマット
<schema>.<table>を使用します。userPostgreSQL データベースのユーザー名。
説明ユーザーはターゲットテーブルに対する読み取り権限を持っている必要があります。
passwordPostgreSQL データベースのパスワード。
テーブルの内容が正しく返された場合、接続は成功です。
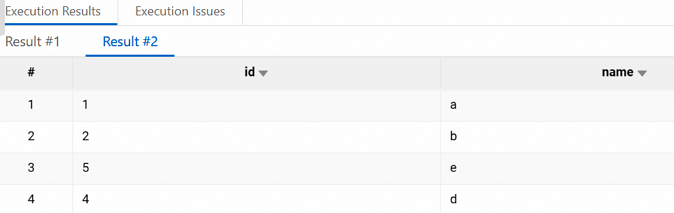
データを挿入します。 次のコマンドを使用して、テーブルにデータを挿入します。
INSERT INTO test VALUES(4, 'd'),(5, 'e'); SELECT * FROM test;挿入されたデータが正しく返された場合、書き込み操作は成功です。
方法 2: Notebook セッションを使用する
[セッションマネージャー] で Notebook セッションを作成し、事前設定された [ネットワーク接続] を選択します。詳細については、「Notebook セッションの作成」をご参照ください。
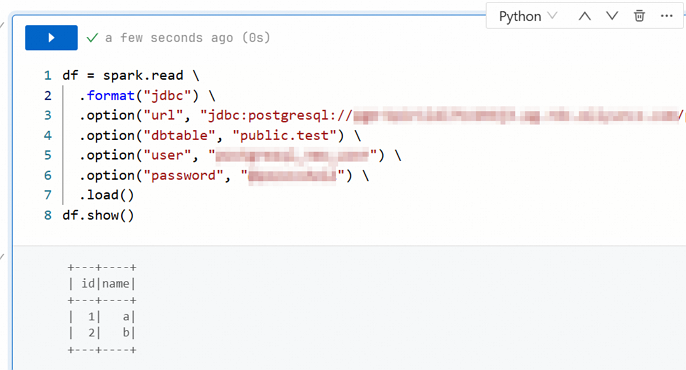
Notebook ジョブを作成します。 [データ開発] で、 ジョブを作成し、テスト用に次の Python コードを使用します。
df = spark.read \ .format("jdbc") \ .option("url", "jdbc:postgresql://<jdbc_url>/<database>") \ .option("dbtable", "<schema>.<table>") \ .option("user", "<username>") \ .option("password", "<password>") \ .load() df.show()テーブルの内容が正しく返された場合、接続は成功です。
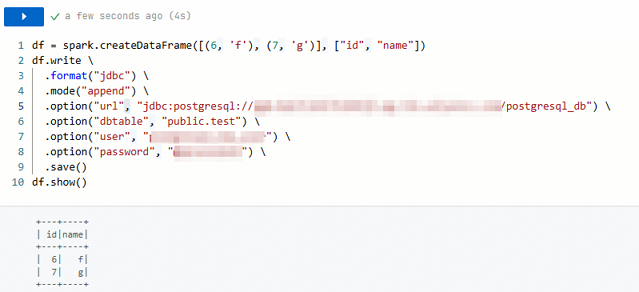
データを挿入します。 次のコードを使用して、テーブルにデータを挿入します。
df = spark.createDataFrame([(6, 'f'), (7, 'g')], ["id", "name"]) df.write \ .format("jdbc") \ .mode("append") \ .option("url", "jdbc:postgresql://<jdbc_url>/<database>") \ .option("dbtable", "<schema>.<table>") \ .option("user", "<username>") \ .option("password", "<password>") \ .save() df.show()mode("append")パラメーターは、書き込みモードを `append` に設定します。これにより、既存のデータを上書きまたは削除することなく、新しいデータがターゲットテーブルに追加されます。挿入されたデータが正しく返された場合、書き込み操作は成功です。
方法 3: Spark バッチジョブを使用する
テストコードを記述します。 次の Scala コードをコンパイルし、JAR ファイルにパッケージ化します。
package spark.test import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("test") .getOrCreate() val newRows = spark.createDataFrame(Seq((6, "f"), (7, "g"))).toDF("id", "name") newRows.write.format("jdbc") .mode("append") .option("url", "jdbc:postgresql://<jdbc_url>/<database>") .option("dbtable", "<schema>.<table>") .option("user", "<username>") .option("password", "<password>") .save() spark.read.format("jdbc") .option("url", "jdbc:postgresql://<jdbc_url>/<database>") .option("dbtable", "<schema>.<table>") .option("user", "<username>") .option("password", "<password>") .load() .show() spark.stop() } }バッチジョブを作成します。[データ開発] で タスクを作成し、テスト用に次のパラメーターを設定します。
メイン JAR リソース: パッケージ化された JAR ファイルのパスを選択または入力します。
メインクラス:
spark.test.Main。ネットワーク接続: 事前設定されたネットワーク接続を選択します。
結果を表示します。タスクの実行後、[実行記録] エリアで [ログの表示] をクリックし、[ドライバーログ] の [Stdout] タブで対応する PostgreSQL テーブルの内容を表示します。