ワークフローオーケストレーション中にタスクを高速化するには、ファンインとファンアウトを使用してタスクを複数のサブタスクに分割し、サブタスクを並列実行してから結果を集計できます。Argo ワークフローは、動的 DAG ファンインとファンアウトをサポートしています。この機能を使用すると、クラスター内のコンピューティングリソースをオンデマンドでスケジュールし、ACS の弾力性を利用して数万の vCPU をスケジュールしてタスクを高速化できます。タスク完了後、リソースは自動的に解放され、コストを節約できます。
機能概要
大規模なタスクを大幅に高速化するには、大規模なタスクを数千のサブタスクに分割する必要がある場合があります。これらのサブタスクを同時に実行できるようにするには、数万の vCPU をスケジュールする必要があります。ただし、同時実行されるサブタスクはリソースを競合します。データセンターのオンプレミスコンピューティングリソースでは、リソース需要を満たすことができません。
たとえば、自動運転シミュレーションタスクのアルゴリズムを最適化した後、すべての運転シナリオをシミュレートするために回帰テストを実行する必要があります。各運転シナリオはサブタスクです。反復処理を高速化するには、すべての運転シナリオで同時にテストを実行する必要があります。
ファンインとファンアウトは、同時実行タスクを効率的に処理するために一般的に使用されます。タスクを分割(ファンイン)し、結果を集計(ファンアウト)することにより、複数の vCPU とコンピューティングインスタンスを完全に活用して大量のデータを処理できます。
前の図では、ワークフローオーケストレーション中に DAG を使用してファンインとファンアウトを実装できます。タスクを静的(静的 DAG)または動的(動的 DAG)にサブタスクに分割できます。
静的 DAG: サブタスクのカテゴリは固定されています。たとえば、データ収集シナリオでは、データベース 1 とデータベース 2 からデータを収集し、結果を集計する必要があります。
動的 DAG: タスクは動的にサブタスクに分割されます。分割は親タスクの出力によって異なります。
前の図では、タスク A は処理されるデータセットをスキャンします。サブタスク (Bn) は、サブディレクトリなどのサブデータセットを処理するために起動されます。各サブタスクはサブデータセットに対応します。Bn サブタスクが完了すると、タスク C は結果を集計します。サブタスクの数は、タスク A の出力によって異なります。タスク A で分割ルールを定義できます。
前提条件
ワークフローが OSS ボリューム内のオブジェクトをローカルファイルとして読み取れるように、OSS ボリュームをマウントします。詳細については、ボリュームの使用を参照してください。
手順
動的 DAG ファンインおよびファンアウトワークフローを作成して、オブジェクトストレージサービス (OSS) バケット内の大きなログファイルを複数のサブファイルに分割します。複数のサブタスクを起動して、各サブファイル内のキーワードの数をカウントし、結果をマージします。
サンプルファイルを、PV がマウントされている OSS パスにアップロードします。
次の YAML コンテンツに基づいてワークフローを作成します。詳細については、ワークフローの作成を参照してください。
動的 DAG を使用してファンインとファンアウトを実装します。
分割タスクを作成して大きなファイルを分割した後、タスクの標準出力に JSON 文字列が生成されます。文字列には、各サブタスクの partId が含まれています。例:
["0", "1", "2", "3", "4"]すべてのマップタスクは、
{{item}}を入力パラメーターとして起動します。各マップタスクは、withParamを使用して分割タスクの出力を参照し、JSON 文字列を解析して{{item}}を取得します。- name: map template: map arguments: parameters: - name: partId value: '{{item}}' depends: "split" withParam: '{{tasks.split.outputs.result}}'
詳細については、Argo ワークフローを参照してください。
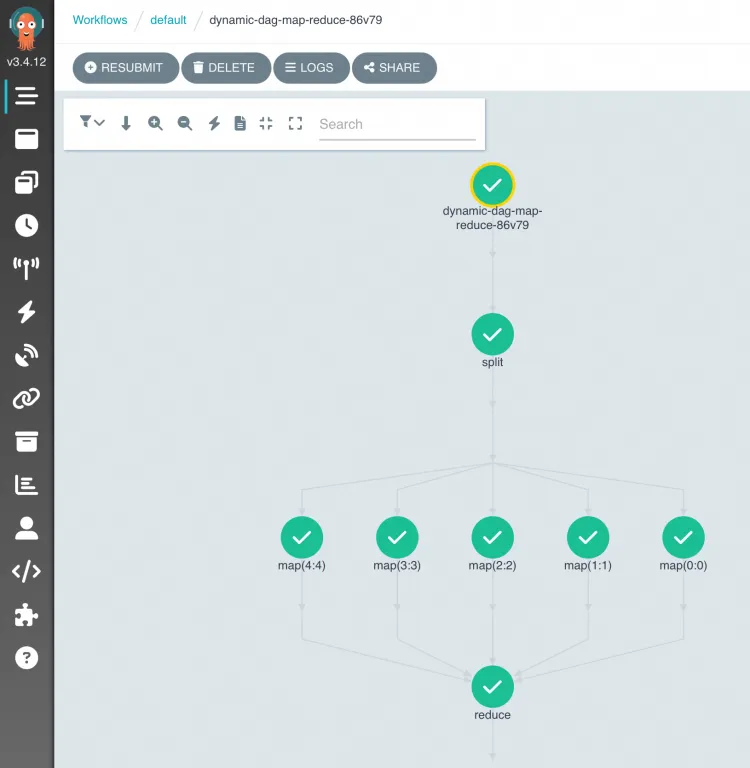
ワークフローの実行が開始されたら、Argo コンソールに移動して DAG プロセスと結果を表示できます。
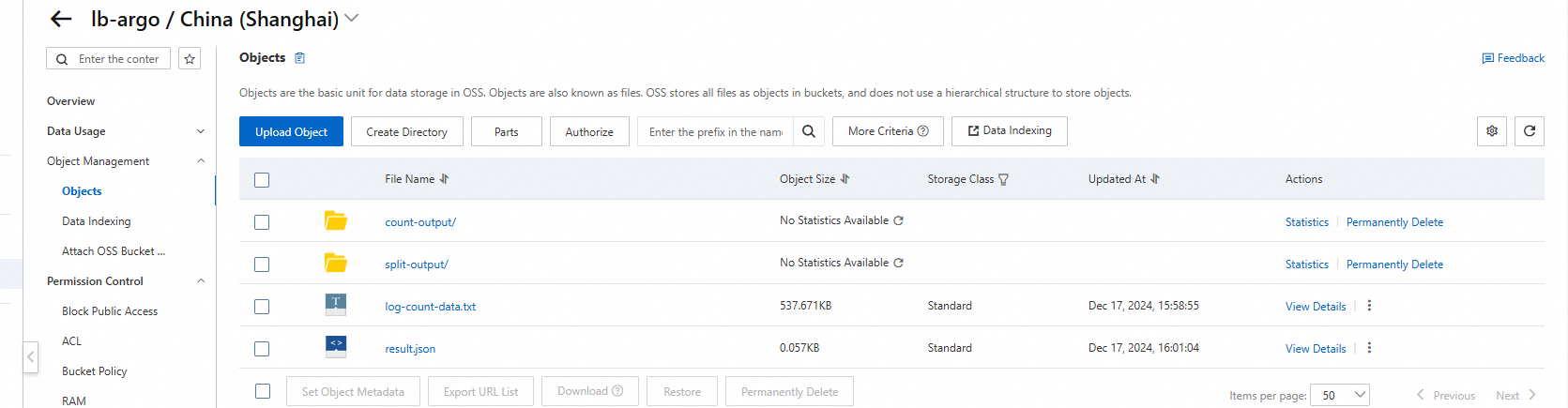
OSS バケットのファイルリストで出力ファイルを表示します。log-count-data.txt はログファイル、split-output と count-output は中間ファイル、result.json は結果ファイルです。
ソースコードを表示するには、argo-workflow-examplesを参照してください。
お問い合わせ
この製品に関するご提案やご質問がある場合は、DingTalk グループ 35688562 に参加してお問い合わせください。