このトピックでは、Intelを使用してg8i汎用インスタンスファミリーのElastic Compute Service (ECS) インスタンスにRetrieval Augment Generation (RAG) ソリューションをデプロイする方法について説明します。®Trust Domain Extensions (TDX) が有効になっています。
背景情報
RAGは、大言語モデル (LLM) が組織のプライベート知識ベースに格納されたデータに基づいて回答を提供できるようにする、最先端のAIアプリケーションフレームワークです。 RAGは、エンタープライズレベルのナレッジベース、チャットボット、AIアシスタントなどのシナリオで広く使用されています。 プライベートデータのセキュリティとプライバシーは主要な考慮事項であり、安全で信頼できる環境が必要です。
g8i汎用インスタンスファミリーのAlibaba Cloud ECSインスタンスとIntel ®TDX対応 (TDX対応インスタンスとも呼ばれます) は、このユースケースに最適です。 TDX対応インスタンスは、ハードウェアベースの信頼できる機密環境を提供し、実行時にテナントのシステムレベルのデータの機密性と整合性を確保します。
このトピックでは、Haystackソフトウェアスタックに基づいてRAGを利用したチャットボットをデプロイする方法に関するエンドツーエンドのガイドを提供します。 TDX対応のECSインスタンスは、各段階でユーザーデータのプライバシーとセキュリティを確保するために使用されます。 このトピックは、次の点でTDXを理解するのに役立ちます。
Alibaba CloudサーバーにデプロイされたTDX暗号化テクノロジーの理解を深めます。
TDX暗号化技術に基づくエンドツーエンドのデータセキュリティソリューションを理解します。
TDXフレームワークとスクリプトを取得して、TDX対応インスタンスをすばやく開始します。
アーキテクチャの説明
RAGは、事前トレーニングされたLLMを使用して、RAGが回答を生成するときに抽出された知識フラグメントを提供して、コンテンツを充実させ、回答の精度を向上させる。 RAGを使用すると、LLMは知識フラグメントを抽出し、そのフラグメントを使用して回答を生成できます。これにより、回答の多様性と精度が向上します。 知識抽出段階では、RAGは単語ベクトルの類似性を測定して、質問に最もよく一致するコンテンツを識別する。 回答生成段階では、選択された知識データがLLMに直接注入され、コンテキストによりよく適合する回答が生成される。
RAGワークフローは、次の部分で構成されます。
ドキュメント処理: アップロードされたドキュメントを暗号化し、TDX対応インスタンスでドキュメントを復号化し、ドキュメントを分割およびベクトル化してから、ドキュメントをデータベースに書き込みます。
データ検索: 検索モデルは、データベースから関連するセグメントを検索し、コンテンツと質問との関連性に基づいて、検索されたコンテンツをランク付けします。
回答生成: LLMは、プロンプトワードと取り出された文書コンテンツとを組み合わせることによって回答を生成する。
従来のRAGソリューション
従来のRAGフレームワークは、データがディスクに書き込まれるとき、およびデータがフロントエンドで照会されるときにセキュリティの脅威にさらされ、脅威はデータベースとLLMに存在します。次の図は、従来のRAGフレームワークを示しています。
TDX環境で展開されたRAGソリューション
次の図は、TDX対応インスタンスにデプロイされたRAGフレームワークを示しています。
溶液組成
RAGアーキテクチャは、クラウド展開とオンラインQ&A処理の2つのプロセスで構成されています。 クラウドでのRAGデプロイには、次の操作が含まれます。
サービスデプロイ者は、TDX対応インスタンスにRAGサービスをデプロイします。 RAGサービスは、ドキュメント分割モジュール、ベクターデータベースモジュール、ランキングモジュール、LLMモジュール、およびフロントエンドモジュールで構成されています。
ドキュメント分割モジュール: アップロードされたドキュメントからテキストを抽出して分割します。
ベクトルデータベースモジュール: 文書分割モジュールによって生成されたフォーマットされたデータをベクトル化し、データをデータベースに格納する。 このアーキテクチャでは、Facebook AI類似性検索 (Faiss) とMySQLの組み合わせが使用されます。
ランキングモジュール: ベクトル化された質問をベクトルデータベース内のデータと比較し、LLMとの類似性が高いテキストを出力します。
LLMモジュール: ランキングモジュールからのテキスト出力と特定のプロンプトワードを使用して、最終的な回答を提供します。
フロントエンドモジュール: ユーザーが質問をし、LLMから回答を取得するインターフェイス。
サービス配置者は、分析するドキュメントをデータベースにアップロードします。
メリット
RAGソリューションは、従来のRAGソリューションの脅威に対処し、次の利点を提供できます。
TDXリモート認証 − トランスポート層セキュリティ (RA-TLS) ベースの通信スキームが構築される。 通信スキームでは、フロントエンドとバックエンドとの間のリモート認証が、ユーザ要求を保護するために実行される。
RAGは、ランタイムを保護するために、Trust Domain (TD) 仮想マシン (VM) で実行できます。
データは、データが常に機密である機密データベースに保存できます。
Linux Unified Key Setup (LUKS) は、データがディスクに書き込まれるときにデータを保護するために使用され、アップロードされたドキュメントとLLMを保護します。
セキュリティと保護
RAGソリューションは、主に次の側面でデータセキュリティとプライバシー保護を提供します。
メモリ暗号化: RAGフロントエンドおよびバックエンドサービスは、メモリが暗号化されているTD環境で実行されます。 これにより、悪意のある当事者がTD環境で実行されるプログラムのデータを盗むのを防ぎます。
RA-TLS通信: RAGフレームワークのDockerイメージが異なるTDX対応インスタンスにデプロイされている場合、RA-TLS通信スキームを使用してリモートノードのIDを確認し、データ送信中のデータセキュリティを確保できます。 RA-TLSについては、「RA-TLS拡張gRPC」をご参照ください。
Linux Unified Key Setup (LUKS) 暗号化およびObject Storage Service (OSS): データベース内のデータがディスクに書き込まれるときにデータを保護するために、LUKS暗号化テクノロジとOSSが使用されます。 これにより、悪意のある者がディスクからモデル情報を盗むのを防ぎます。
手順
手順1: TDX対応インスタンスの作成
ECSコンソールのインスタンス購入ページに移動します。
ECSインスタンスの作成のプロンプトに従ってパラメーターを設定します。
次のパラメータに注意してください。 ECSインスタンス購入ページで他のパラメーターを設定する方法については、「カスタム起動タブでインスタンスを作成する」をご参照ください。
インスタンス: 使用するモデルの安定性を確保するために、少なくともecs.g8i.4xlargeでメモリが64 GiBのインスタンスタイプを選択します。
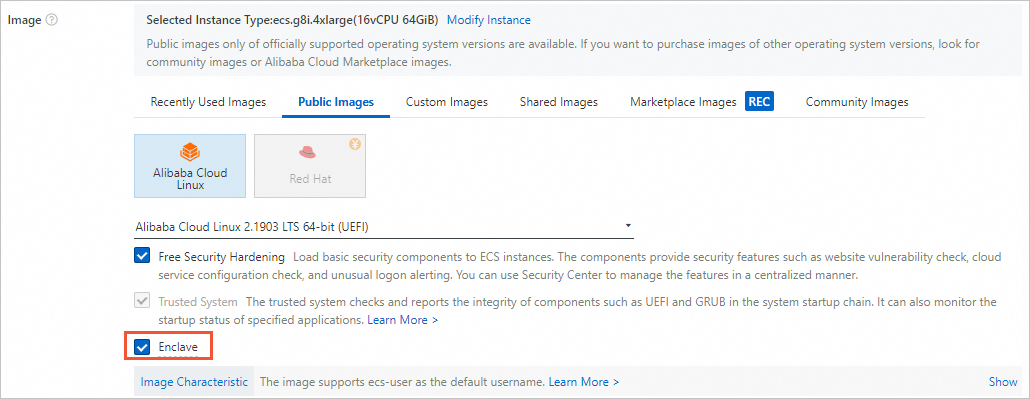
イメージ: イメージのバージョンとして [Alibaba Cloud Linux 3.2104 LTS 64ビット (UEFI)] を選択し、[機密VM] を選択します。
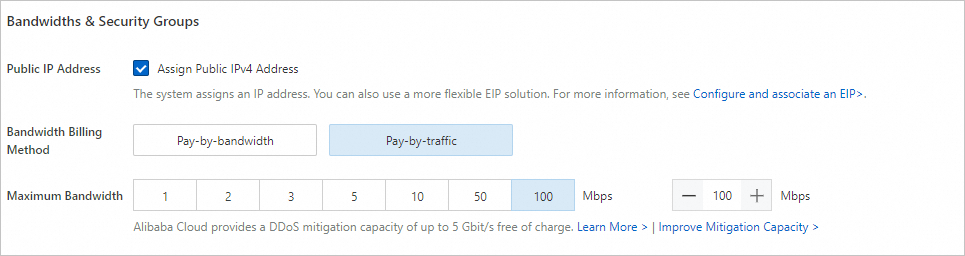
パブリックIPアドレス: モデルのデータダウンロードを高速化するには、[パブリックIPv4アドレスの割り当て] を選択し、帯域幅課金方法を [トラフィック課金] に設定し、最大帯域幅を100 Mbit/sに設定します。
データディスク: データディスクのサイズを少なくとも100 GiBに設定することを推奨します。
セキュリティグループ: ポート22、80、および8502を開きます。
Python 3.8をインストールします。
インスタンスにはPython 3.6が付属していますが、このRAGソリューションにはPython 3.8以降が必要です。 Python 3.8の手動インストールが必要です。
Python 3.8パッケージをインストールします。
sudo yum install -y python38Python 3.8をデフォルトのPythonバージョンとして設定します。
sudo update-alternatives --config pythonプロンプトに従って
4を入力し、デフォルトのPythonバージョンとしてPython 3.8を選択します。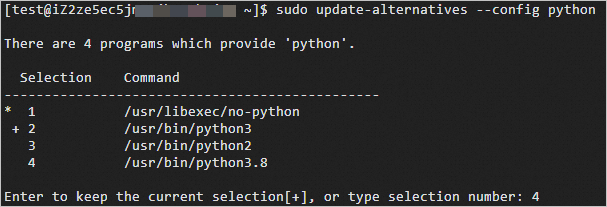
Pythonの対応するpipバージョンを更新します。
sudo python -m ensurepip --upgrade sudo python -m pip install --upgrade pip
手順2: Dockerイメージのデプロイ
作成したTDX対応インスタンスにDockerをインストールします。
詳細については、「LinuxインスタンスにDockerをインストールして使用する」トピックの「Dockerのインストール」セクションのAlibaba Cloud Linux 3の部分をご参照ください。
Confidential Computing Zoo (CCZoo) をECSインスタンスにダウンロードします。
CCZooは、Software Guard Extensions (SGX) とTDXを含むIntel Trusted Execution Environment (TEE) テクノロジを使用し、さまざまなシナリオでのエンドツーエンドのセキュリティソリューションの例を提供します。 これは、よりシンプルでケースバイケースの方法で機密のコンピューティングソリューションを開発するのに役立ちます。
説明<workdir>の値を実際のディレクトリに置き換えます。 この例では、/home/ecs-userが使用されます。cd <workdir> git clone https://github.com/intel/confidential-computing-zoo.gitDockerイメージをダウンロードまたはコンパイルします。
説明システムは、Dockerイメージをダウンロードまたはコンパイルするために長時間を必要とします。
Docker HubからDockerイメージをダウンロードします。
sudo docker pull intelcczoo/tdx-rag:backend sudo docker pull intelcczoo/tdx-rag:frontendDockerイメージをコンパイルします。
cd confidential-computing-zoo/cczoo/rag ./build-images.sh
手順3: 暗号化パーティションの作成
暗号化パーティションを作成します。
モデルファイルとドキュメントデータを保存する暗号化パーティションを作成します。
cd confidential-computing-zoo/cczoo/rag/luks_tools sudo yum install -y cryptsetup VFS_SIZE=30G VIRTUAL_FS=/home/vfs sudo ./create_encrypted_vfs.sh ${VFS_SIZE} ${VIRTUAL_FS}はいつですか? (大文字で「はい」と入力):メッセージが表示され、YESと入力します。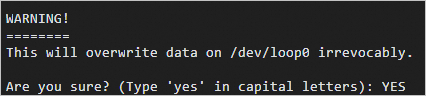
Enter passphrase for /home/vfs:メッセージが表示されたら、暗号化されたパーティションのパスワードを入力します。
暗号化されたパーティションが作成された後、システムはループデバイス番号を出力します。 この例では、次の図に示すように、ループデバイス番号は
/dev/loop1です。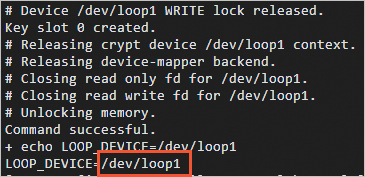
ループデバイスの環境変数LOOP_DEVICEを設定します。
<the bound loop device>の値を、前の手順で取得したループデバイス番号に置き換えます。export LOOP_DEVICE=<the bound loop device>ブロックループデバイスをExt4ファイルシステムにフォーマットします。
/home/encrypted_storageディレクトリを作成し、現在のユーザーに権限を付与します。 この例では、ecs-userが使用されます。sudo mkdir /home/encrypted_storage sudo chown -R ecs-user:ecs-user /home/encrypted_storage/ブロックループデバイスをExt4ファイルシステムにフォーマットします。
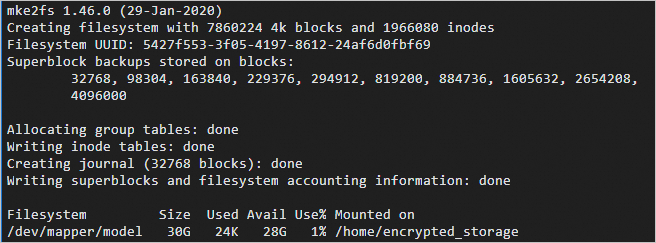
./mount_encrypted_vfs.sh ${LOOP_DEVICE} formatEnter passphrase for /home/vfs:メッセージが表示されたら、手順1.bで指定したパスワードを入力します。
次の図のコマンド出力は、ブロックループデバイスがフォーマットされていることを示しています。
ステップ4: ドキュメントデータとバックエンドモデルのダウンロード
Alibaba Cloudは、サードパーティモデルの合法性、セキュリティ、または正確性を保証するものではありません。 アリババクラウドは、それによって生じたいかなる損害についても責任を負いません。
サードパーティモデルのユーザー契約、使用法の仕様、および関連する法律および規制を遵守する必要があります。 あなたは、サードパーティ制モデルの使用があなたの唯一のリスクにあることに同意します。
デフォルトでは、次のデータとバックエンドモデルが使用されます。
ドキュメントデータ:
<workdir>/confidential-computing-zoo/cczoo/rag/data/data.txtのサンプルコンテンツ。バックエンドLLM: Llama-2-7b-chat-hf。
ランキングモデル: ms-marco-MiniLM-L-12-v2。
エンコーダモデル: dpr-ctx_encoder-single-nq-baseとdpr-question_encoder-single-nq-base。
この例では、ModelScopeコミュニティおよびHugging Face Webサイトから必要なモデルをダウンロードする方法について説明します。 他のモデルをダウンロードする場合は、次の手順を参照として使用できます。
アップロードされたモデルまたはデータをOSSから取得することもできます。 詳しくは、「オブジェクトのダウンロード」をご参照ください。
ossutil64 cp oss://<your dir>/<your file or your data> /home/encrypted_storage/home/encrypted_storageディレクトリに切り替えます。cd /home/encrypted_storagemodelscopeランタイムライブラリをインストールし、ライブラリの環境変数を設定します。
pip install modelscope export MODELSCOPE_CACHE=/home/encrypted_storageLlama-2-7b-chat-hfモデルをダウンロードします。
python3.8 -c "from modelscope import snapshot_download; model_dir = snapshot_download('shakechen/Llama-2-7b-chat-hf')" mv shakechen/Llama-2-7b-chat-hf Llama-2-7b-chat-hfhuggingface_hubランタイムライブラリをインストールし、ライブラリの環境変数を設定します。
pip install -U huggingface_hub export HF_ENDPOINT=https://hf-mirror.comランキングモデルやエンコーダモデルなどの事前トレーニング済みモデルをダウンロードします。
huggingface-cli download --resume-download --local-dir-use-symlinks False cross-encoder/ms-marco-MiniLM-L-12-v2 --local-dir ms-marco-MiniLM-L-12-v2 huggingface-cli download --resume-download --local-dir-use-symlinks False facebook/dpr-ctx_encoder-single-nq-base --local-dir dpr-ctx_encoder-single-nq-base huggingface-cli download --resume-download --local-dir-use-symlinks False facebook/dpr-question_encoder-single-nq-base --local-dir dpr-question_encoder-single-nq-base
ステップ5: RAGサービスの有効化
ragディレクトリに切り替えます。
cd <workdir>/confidential-computing-zoo/cczoo/ragデータベースサービスコンテナを起動します。
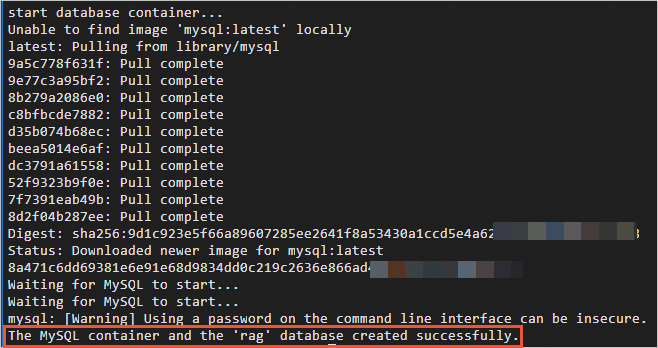
sudo ./run.sh db次の図に示す出力と同様の出力が表示された場合、データベースサービスコンテナが起動されます。
バックエンドサービスコンテナを起動します。
sudo ./run.sh backendスクリプトが実行されると、
data.txtファイルのコンテンツが分割され、データベースに保存されます。 データベースのIPアドレス (オンプレミスコンピューターのパブリックIPアドレス) 、デフォルトのデータベースアカウント (root) 、およびプロンプトに従って123456されるデフォルトのデータベースパスワードを入力します。常に機密データベース機能を使用してデータベース内の機密データを暗号化する方法については、「概要」をご参照ください。
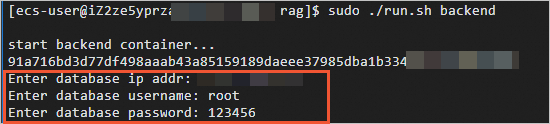
次の図に示すような出力が表示された場合、バックエンドサービスコンテナが起動されます。

ターミナルセッションを作成し、フロントエンドサービスコンテナを開始します。
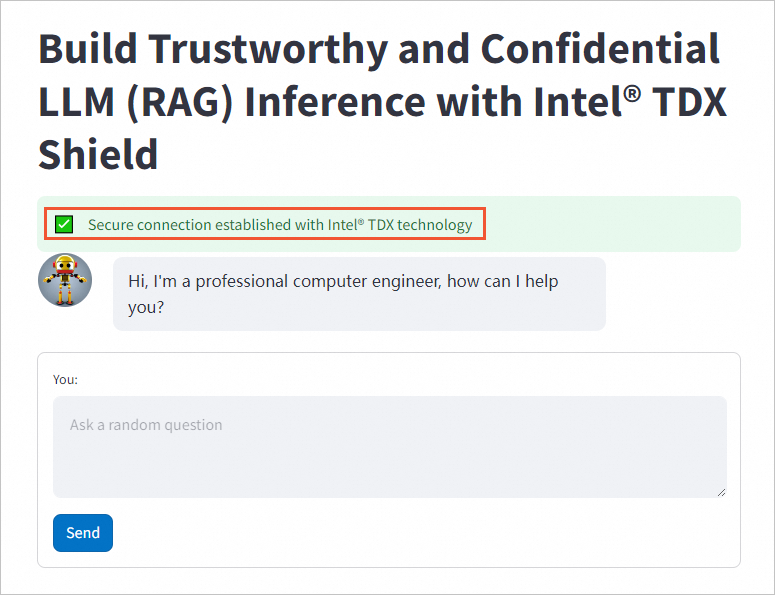
cd <workdir>/confidential-computing-zoo/cczoo/rag sudo ./run.sh frontend次の図に示す出力と同様の出力が表示される場合、フロントエンドサービスコンテナが起動されます。
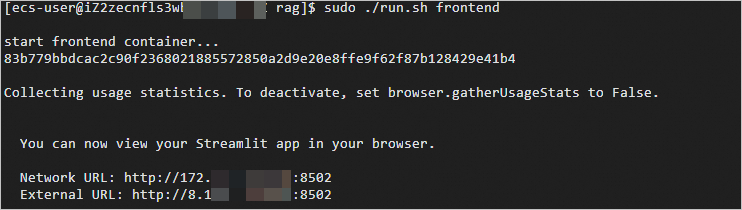
前の手順で取得した外部URLをオンプレミスのコンピューターのブラウザーに入力して、AI会話を開始します。
緑の背景のメッセージは、フロントエンドとバックエンドの間に安全な接続が確立されていることを示します。 RAGフレームワークのカスタム変更と問題については、「Haystack」をご参照ください。