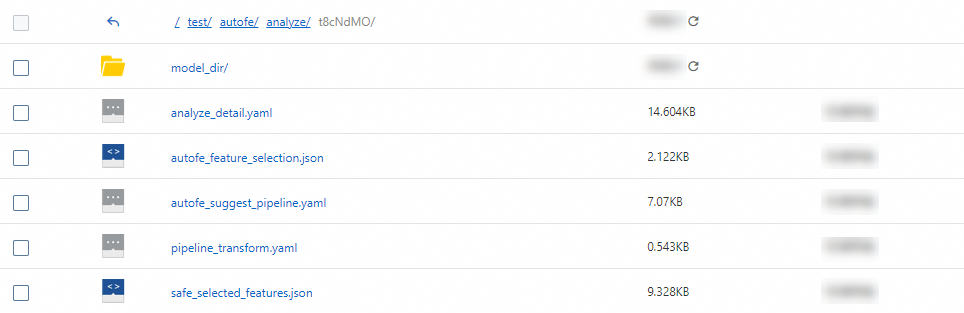
このトピックでは、Auto Feature Engineering (AutoFE) を使用して FeatureStore で新しい特徴量を生成する方法について説明し、いくつかの提案と洞察を提供します。AutoFE によって生成されたパイプラインモデルを使用して、トレーニングデータセットとテストデータセットの特徴量を変換できます。これにより、機械学習またはディープラーニングモデルのパフォーマンスが向上します。
AutoFE の概要
AutoFE は、提供されたデータを分析することにより、一連の特徴量エンジニアリング操作を推奨します。この一連の操作を直接使用して特徴量エンジニアリングを実行したり、推奨される操作に基づいて特徴量エンジニアリングプロセスをカスタマイズしたりできます。
AutoFE は、次の特徴を提供します。
group by feature_x や group by (feature_x, feature_y) などの操作を実行して、統計的特徴量を取得します。たとえば、AutoFE はサンプルデータに基づいて都市別の売上特徴量を生成できます。これは、都市を数値特徴量にマッピングすることと同じです。
特徴量の組み合わせを分析して、組み合わせ特徴量を取得します。例: crosscount(feature_x, feature_y)。
加算、減算、乗算、除算の操作を実行して、派生特徴量を取得します。例: feature_x +-*/ feature_y。
Gradient Boosting Decision Tree (GBDT) アルゴリズムを使用して、生成された特徴量を情報量、重要度、および特徴量の相関に基づいてソートし、特徴量選択を行います。
フローチャート
前処理
AutoFE は、MaxCompute プロジェクト、Object Storage Service (OSS) バケット、Hadoop 分散ファイルシステム (HDFS) ファイルシステム、ローカルファイルなどのデータストアから読み取ったデータを前処理し、特定の要件とデータ量に基づいてデータをサンプリングします。FeatureStore の AutoFE は MaxCompute プロジェクトのみをサポートします。AutoFE のスタンドアロン版は、すべてのデータストアをサポートします。
特徴量選択
特徴量の数が 800 を超えると、後続の特徴量分析およびモデルトレーニングステップのパフォーマンスに影響します。GBDT アルゴリズムを使用して、生の特徴量を評価およびフィルターすることをお勧めします。
特徴量分析
AutoFE は、特徴量に対して統計分析、組み合わせ生成、およびスケーラブルな自動特徴量エンジニアリング (SAFE) 選択を実行して、新しい特徴量セットを生成します。
統計分析: AutoFE は、平均値、標準偏差、最大値、最小値、歪度、尖度など、複数の重要な統計メトリックに基づいて特徴量データの統計分析を実行します。
組み合わせ生成: AutoFE は GBDT モデルをトレーニングし、ツリーパスに基づいて特徴量を組み合わせ、情報利得率を計算して特徴量をソートし、特徴量の組み合わせを推奨します。
SAFE 選択: AutoFE は、バケットを使用して各列の情報量を計算し、情報量の低い特徴量をフィルターで除外し、GBDT モデルをトレーニングし、特徴量の重要度を計算し、重要度の低い特徴量をフィルターで除外します。
詳細については、「SAFE: Scalable Automatic Feature Engineering Framework for Industrial Tasks」をご参照ください。
モデルトレーニング
AutoFE は、特徴量分析に基づいて構成とデータを生成し、パイプラインプロセスをトレーニングし、オフラインとオンラインの両方で使用できるモデルを生成します。
特徴量変換
AutoFE はパイプラインモデルをロードし、トレーニングデータとテストデータの特徴量を変換し、特徴量エンジニアリングの結果を生成します。
課金
AutoFE は無料でご利用いただけます。ただし、AutoFE が前処理、特徴量選択、統計分析、モデルトレーニングなどの操作を実行すると、サブスクリプションまたは従量課金の MaxCompute プロジェクトでデータコンピューティングとモデルトレーニングタスクが開始されます。したがって、MaxCompute に関連するパブリックリソースの使用に対して料金が請求されます。詳細については、「概要」をご参照ください。
前提条件
このトピックで説明する操作を実行する前に、次の表で説明する要件が満たされていることを確認してください。
関連サービス | 説明 |
MaxCompute | |
DataWorks |
|
Platform for AI (PAI) | |
OSS |
開始する前に
pai_online_project.finance_record テーブルからデータを同期する
テストを容易にするために、Alibaba Cloud は MaxCompute プロジェクト pai_online_project にシミュレートされたテーブルを提供します。SQL 文を実行して、MaxCompute プロジェクト pai_online_project から MaxCompute プロジェクトにテーブルのデータを同期できます。次のステップを実行します。
DataWorks コンソールにログインします。
左側のナビゲーションウィンドウで、[データ開発と O&M] > [データ開発] を選択します。
DataStudio ページで、作成した DataWorks ワークスペースを選択し、[データ開発へ] をクリックします。
[作成] にポインターを合わせ、[ノードの作成] > [MaxCompute] > [ODPS SQL] を選択します。[ノードの作成] ダイアログボックスで、次の表で説明するノードパラメーターを構成します。
パラメーター
説明
エンジンインスタンス
作成した MaxCompute エンジンインスタンスを選択します。
ノードタイプ
[ノードタイプ] ドロップダウンリストから [ODPS SQL] を選択します。
パス
[ビジネスフロー] > [ワークフロー] を選択します。
名前
カスタム名を指定します。
[確認] をクリックします。
作成したノードのタブで、次の SQL 文を実行して、pai_online_project プロジェクトから MaxCompute プロジェクトに finance_record テーブルのデータを同期します。
CREATE TABLE IF NOT EXISTS finance_record like pai_online_project.finance_record STORED AS ALIORC LIFECYCLE 90; INSERT OVERWRITE TABLE finance_record SELECT * FROM pai_online_project.finance_record
手順
Data Science Workshop (DSW) インスタンスの開発環境に移動します。
PAI コンソールにログインします。
上部のナビゲーションバーで、DSW インスタンスが存在するリージョンを選択します。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。[ワークスペース] ページで、デフォルトのワークスペースの名前をクリックします。
デフォルトのワークスペースの左側のナビゲーションウィンドウで、[モデルトレーニング] > [Data Science Workshop (DSW)] を選択します。
[Data Science Workshop (DSW)] ページで、開きたい DSW インスタンスを見つけ、[アクション] 列の [開く] をクリックして、DSW インスタンスの開発環境に移動します。
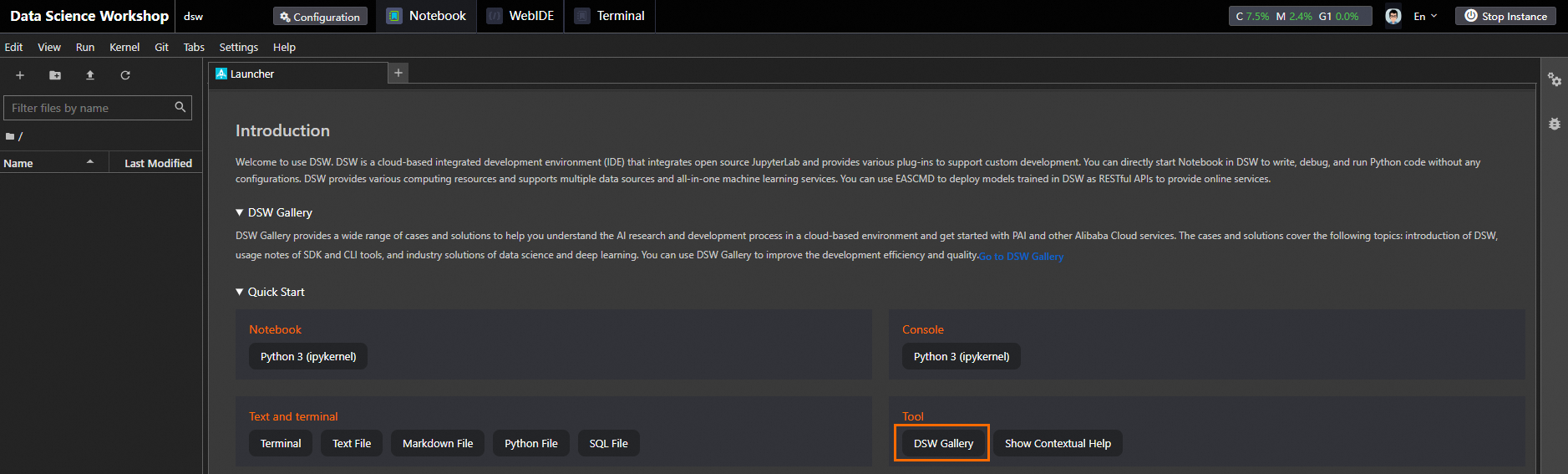
[Notebook] タブの [Launcher] タブで、[クイックスタート] セクションの [DSW ギャラリー] をクリックして、DSW ギャラリーページに移動します。
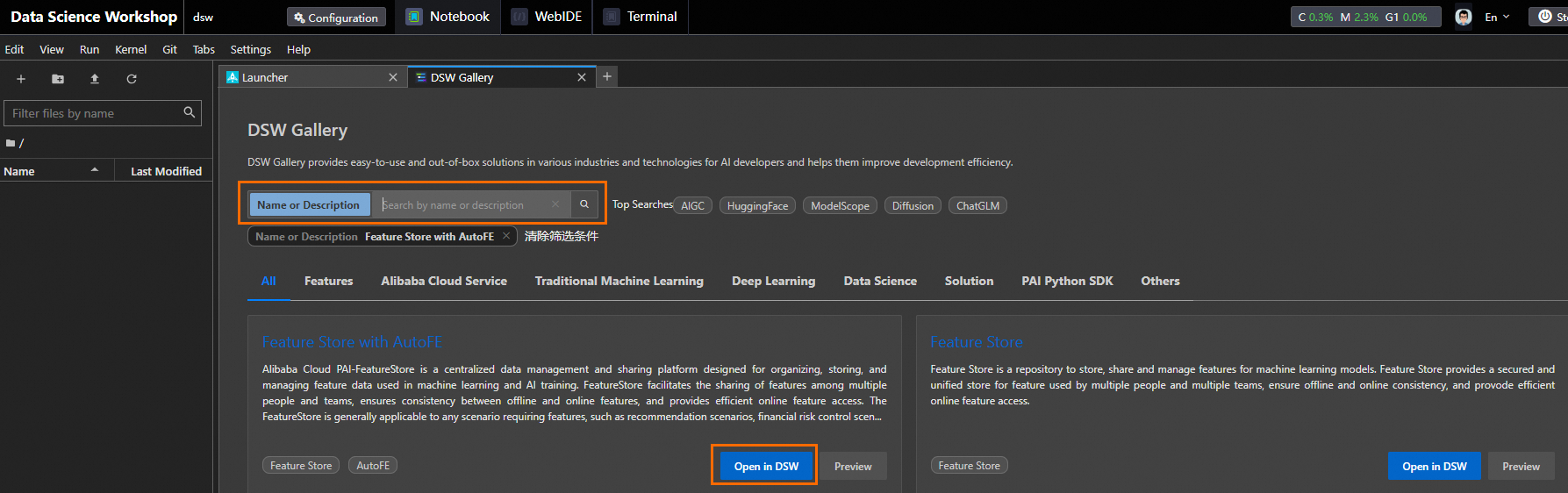
DSW ギャラリーページで [Feature Store With AutoFE] を検索し、[DSW で開く] をクリックします。システムは、必要なリソースとチュートリアルファイルを DSW インスタンスにダウンロードし始めます。ダウンロードが完了すると、チュートリアルファイルが自動的に開きます。
チュートリアルファイル [feature_store_with_autofe.ipynb] で、チュートリアルコンテンツを表示し、チュートリアルを実行します。
チュートリアルファイルでパラメーターを構成し、
 をクリックしてステップのコマンドを実行します。各ステップのコマンドを順番に実行します。
をクリックしてステップのコマンドを実行します。各ステップのコマンドを順番に実行します。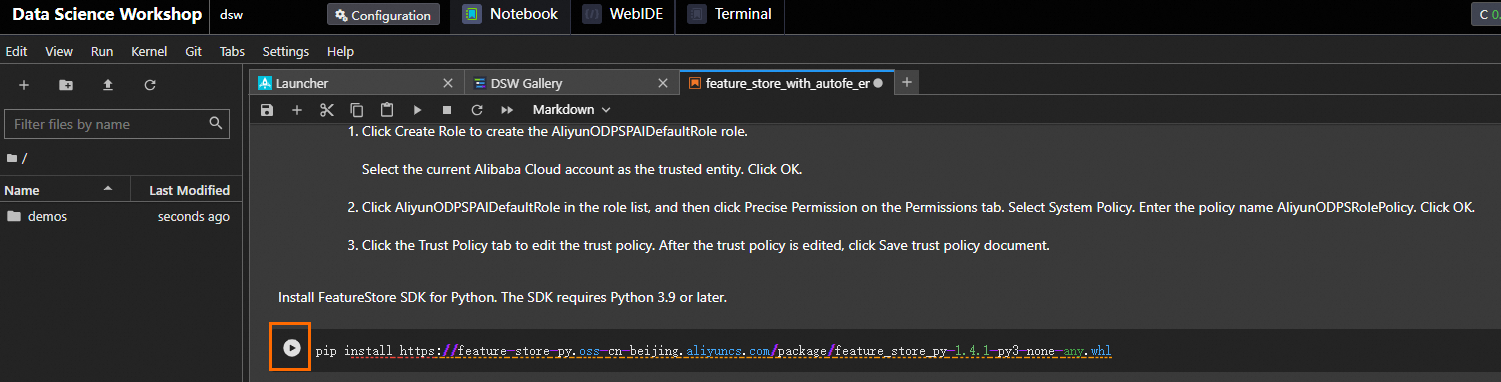
コマンドが実行されたら、OSS コンソールに移動してテスト結果を表示します。
OSS バケットのパスを取得するには、ステップ 4 で構成した
output_config_oss_dirパラメーターの値を表示します。