Alibaba Cloud Elasticsearch 7.10 Enhanced Edition と Indexing Service を使用することで、クラウドホスト型の書き込み高速化と、トラフィックに基づく従量課金を実現できます(つまり、ピーク時の書き込みスループットに基づいてリソースを予約する必要はありません)。 これにより、非常に低コストで大規模な時系列ログを分析できます。 このトピックでは、Indexing Service に基づいてデータストリーム管理とログシナリオ分析を実装する方法について説明します。
背景情報
複雑なビジネスシナリオでは、大規模なサーバー、物理マシン、Docker コンテナー、モバイルデバイス、IoT センサーに、分散した多様な大規模なメトリックとログデータが含まれていることがよくあります。 基礎となるシステムからのさまざまなメトリックやログデータに加えて、ユーザーの行動や車両の軌跡など、大規模なビジネスデータが存在することもよくあります。 大規模な時系列データとログデータの書き込みにおけるパフォーマンスボトルネックに直面した場合、ビジネス要件に応じて Alibaba Cloud Elasticsearch 7.10 Enhanced Edition Indexing Service を使用することを選択できます。 この機能は、読み書き分離アーキテクチャと、書き込みに対して従量課金される Serverless モデルに基づいており、Elasticsearch クラスタのクラウドベースの書き込みホスティングと費用対効果の高い目標を達成します。
Alibaba Cloud Elasticsearch 7.10 Enhanced Edition と Indexing Service では、データストリーム管理を使用することをお勧めします。これは、複数のインデックスにわたって追加専用の時系列データを保存し、リクエストのために一意の名前付きリソースを提供するのに役立ちます。 また、関連付けられたインデックステンプレートとロールオーバーポリシーに基づいて自動アンホスティングを実装し、クラウドホスト型データの自動クリーンアップとコストの最適化を実現することもできます。 データストリーム管理は、ログ、イベント、メトリック、およびその他の継続的に生成されるデータシナリオに特に適しています。 さらに、Index Lifecycle Management(ILM)を使用してバッキングインデックスを定期的に管理し、コストとオーバーヘッドを削減することもできます。
Elasticsearch クラスタには、データストリーム(データストリーム)と独立したインデックス(インデックス)オブジェクトの両方を含めることができます。 ホストされていないシステムインデックスを除き、他のすべてのインデックスではデフォルトでクラウドホスティングが有効になっています。 独立したインデックスは、作成、削除、更新、およびクエリ操作をサポートしていますが、これらの操作を実行する前に、手動でクラウドホスティングをキャンセルする必要があります。 クラウドホスト型インデックスのデータストリーム管理をより適切に使用できるように、Alibaba Cloud Elasticsearch コンソールは、データストリーム管理、インデックス管理、およびインデックステンプレートの作成機能モジュールを提供し、Web インターフェースを介したデータストリームのワンストップ管理を実装します。
シナリオ
このトピックでは、収集された nginx サービスログデータを Indexing Service を使用した Alibaba Cloud Elasticsearch 7.10 Enhanced Edition インスタンスに書き込み、データストリーム管理とインデックスライフサイクル管理を通じてログデータ分析と取得を実装する方法を示します。
注意事項
データストリームの書き込みは時間フィールド @timestamp に依存するため、書き込まれるデータに @timestamp フィールドが含まれていることを確認してください。そうでない場合、データストリームの書き込み中にエラーが発生します。 ソースデータに @timestamp フィールドがない場合は、ingest パイプライン を使用して _ingest.timestamp を指定し、メタデータ値を取得して、@timestamp フィールドデータを取り込むことができます。
Indexing Service は、Serverless 保護メカニズムを提供します。 使用する前に、制限を参照して構成を事前に最適化し、使用中に非準拠の状況を回避してください。
Indexing Service Enhanced Edition インスタンスがユーザー クラスタとデータを同期する場合、apack/cube/metadata/sync タスクに依存します(
GET _cat/tasks?vコマンドを使用して取得できます)。 このタスクを手動でクリアすることはお勧めしません。 クリアした場合は、POST /_cube/meta/syncコマンドを使用してできるだけ早く復旧してください。そうしないと、ビジネスの書き込みに影響します。
手順
ステップ 1:Indexing Service インスタンスを作成する
Indexing Service を使用した Alibaba Cloud Elasticsearch 7.10 Enhanced Edition インスタンスを作成します。
データストリームを使用する前に、インデックステンプレートを作成して、データストリームバッキングインデックスの構造を構成する必要があります。
データストリームを作成し、データを書き込みます。
データストリームまたは独立したインデックスのクラウドホスティングを管理します。
ノードの可視化ページで、当日の合計書き込みトラフィックと書き込みホスト型インデックスの総数を表示します。
Kibana コンソールで、Indexing Service で実装されたデータストリーム管理に基づいて、リアルタイムのログストリームとリアルタイムのデータメトリックを表示します。
ステップ 1:Indexing Service インスタンスを作成する
Enhanced Edition 7.10 バージョンを購入し、高度な拡張機能である Indexing Service を有効にします。 手順については、「Alibaba Cloud Elasticsearch インスタンスを作成する」をご参照ください。
Indexing Service を有効にすると、書き込み Serverless モジュールは、実際の書き込みトラフィックとホストされているストレージスペースに応じて従量課金されます。 詳細については、「Alibaba Cloud ES の課金」をご参照ください。
ステップ 2:インデックステンプレートを作成する
ビジネスで Put Mapping 操作が頻繁に発生する場合は、大量の計算リソースを消費してホスティング サービスの安定性に影響を与えるのを避けるため、データを書き込む前にインデックステンプレートを定義して、Put Mapping 操作がクラスタの安定性に与える影響を軽減することをお勧めします。
Alibaba Cloud Elasticsearch コンソール にログインします。
目的のクラスタに移動します。
上部のナビゲーションバーで、クラスタが属するリソースグループとクラスタが存在するリージョンを選択します。
[Elasticsearch Clusters] ページで、クラスタを見つけて ID をクリックします。
左側のナビゲーションウィンドウで、 を選択します。
[インデックステンプレート管理] タブをクリックします。
[インデックステンプレートの作成] をクリックします。
オプション:[インデックステンプレートの作成] パネルで、インデックスライフサイクルポリシーを構成します。
説明データストリームバッキングインデックスのライフサイクルポリシーを管理する必要がない場合は、[このステップをスキップ] をクリックします。
次の表にいくつかのパラメータを示します。 記載されていないパラメータについては、ページの具体的な説明を参照してください。
パラメータ
値の例
説明
[インデックスライフサイクルポリシー]
新しいインデックスライフサイクルポリシーを作成する
[新しいインデックスライフサイクルポリシーを作成する]:新しいインデックスライフサイクルポリシーを作成します。
説明Indexing Service アーキテクチャでは、インデックスライフサイクルのカスタムフリーズはサポートされていません。
[既存のインデックスライフサイクルポリシーを選択する]:クラスタにビジネスロジックのポリシーがある場合は、ドロップダウンボックスをクリックして選択します。
[ポリシー名]
nginx_policy
新しいインデックスライフサイクルポリシーを作成する場合は、カスタム名を入力する必要があります。 既存のインデックスライフサイクルポリシーを選択する場合は、ドロップダウンリストから既存のライフサイクルポリシーを選択する必要があります。
ホスティングがキャンセルされるまでの期間
3 日
デフォルトでは、3 日後にホスティングがキャンセルされます。 特定のビジネスシナリオに基づいて、ホスティングをキャンセルする時間を評価します。
[削除時間]
7 日
インデックスが自動的に削除されるまでに保持される日数を設定します。
このステップのサンプルコマンド:
{ "policy": { "phases": { "hot": { "min_age": "0s", "actions": { "cube_unfollow": { "max_age": "3d", "force_merge": true, "force": false, "read_only": true }, "rollover": { "max_size": "30gb", "max_age": "1d", "max_docs": 10000 }, "set_priority": { "priority": 1000 } } }, "delete": { "min_age": "7d", "actions": { "delete": { "delete_searchable_snapshot": true } } } } } }上記で新しく作成されたインデックスライフサイクルポリシーは、ホストされているインデックスが次のいずれかの条件を満たすと、ロールオーバーがトリガーされて新しいバッキングインデックスが生成され、元のインデックスは 7 日後に自動的に削除されることを示しています。
書き込まれたドキュメントの数が 1,000,000 を超えています。
インデックスサイズが 30 GB に達しています。
作成から 1 日が経過しています。
[保存して次へ] をクリックして、インデックステンプレート情報を構成します。
パラメータ
値の例
説明
[テンプレート名]
nginx_telplate
定義されたテンプレート名。
[インデックスパターン]
nginx-*
ワイルドカード (*) 式を使用してデータストリーム名とインデックス名に一致するように、インデックスパターンを定義します。 スペースと文字
\/?"<>|は使用できません。[データストリームの作成]
有効
データストリームモードを有効にします。 有効にしないと、インデックスパターンでデータストリームを生成できません。 詳細については、「データストリーム」をご参照ください。
[優先度]
100
テンプレートの優先度を定義します。 値が高いほど、優先度が高くなります。
[インデックスライフサイクルポリシー]
nginx_policy
参照できるインデックスライフサイクルポリシーは 1 つだけです。
[コンテンツテンプレートの構成]
設定の構成は次のとおりです:
{ "index.number_of_replicas": "1", "index.number_of_shards": "6", "index.refresh_interval": "5s" }重要データストリームに書き込まれる各ドキュメントには、@timestamp フィールドが必要です。 インデックステンプレートで @timestamp フィールドのマッピングを指定することをお勧めします。 指定しない場合、フィールドは Elasticsearch で date または date_nanos タイプのフィールドとしてマッピングされます。
構成フォーマットは、Elastic の公式構成に厳密に従います。
このステップのサンプルコマンド値:
PUT /_index_template/nginx_telplate { "index_patterns": [ "nginx-*" ], "data_stream": { }, "template": { "settings": { "index.number_of_replicas": "1", "index.number_of_shards": "6", "index.refresh_interval": "5s", "index.lifecycle.name": "nginx_policy", "index.apack.cube.following_index": true } }, "priority": 100 }重要コマンドを使用してテンプレートを作成する場合は、index.apack.cube.following_index を true に設定してください。
クラウドホスト型クラスタの index.refresh_interval パラメータはすでに最適なデフォルトで構成されており、手動構成は有効になりません。 index.refresh_interval の手動構成を有効にする必要がある場合は、最初にクラウドホスティング機能をキャンセルする必要があります。
[OK] をクリックします。作成したテンプレートがインデックステンプレートリストに表示されます。
ステップ 3:データストリームを作成する
[インデックス管理ハブ] ページで、[データストリーム管理] タブをクリックします。
[データストリームの作成] をクリックします。
[データストリームの作成] パネルで、[既存のインデックステンプレートのプレビュー] をクリックし、対応するインデックステンプレートに一致するデータストリーム名を入力します。
この手順のサンプルコマンド値:
PUT /_data_stream/nginx-log重要データストリームを作成する前に、データストリームが一致できるインデックステンプレートが必要です。これには、データストリームのバッキングインデックスを設定するためのマッピングと設定が含まれます。
データストリーム名はハイフン (-) で終わることができますが、ワイルドカードのアスタリスク (*) はサポートしていません。
[OK] をクリックします。システムは自動的にデータストリームとバッキングインデックスを生成します。
各データストリームが正常に作成されると、次のように、統一された形式のバッキングインデックスが自動的に生成されます。
.ds-<data-stream>-<yyyy.MM.dd>-<generation>パラメータ
説明
.ds
非表示のインデックス名識別子。データストリームによって生成されるバッキングインデックスの名前はすべて、デフォルトで .ds で始まります。
<data-stream>
データストリーム名。
<yyyy.MM.dd>
バッキングインデックスが作成された日付。
<generation>
各データストリームは、デフォルトで 000001 から始まる 6 桁の累積整数を生成します。生成値が大きいバッキングインデックスには、より新しいデータが含まれています。
データを書き込みます
データの書き込み中に、@timestamp フィールドを含める必要があります。そうしないと、書き込みは失敗します。このシナリオでは、filebeat+kafka+logstash アーキテクチャを使用してログを収集し、Elasticsearch インスタンスに書き込みます。@timestamp フィールドは、収集プロセス中に自動的に生成されます。サンプルコマンド:
POST /nginx-log/_doc/ { "@timestamp": "2099-03-07T11:04:05.000Z", "user": { "id": "vlb44hny" }, "message": "Login attempt failed" }
ステップ 4:ホストされているインデックスを管理する
[インデックス管理ハブ] ページで、[インデックス管理] タブをクリックして、クラウドホスティング状態のインデックスを表示します。
パラメータ
説明
ホストされているインデックスのみを表示
システムは、デフォルトでクラスター内のすべてのインデックスを表示します(システムインデックスを除く)。 [ホストされているインデックスのみを表示] を選択すると、システムはホストされているインデックスのみを表示し、ホストされているデータにすばやくアクセスできるようにします。
クラウドホスト型インデックスの合計サイズ
現時点で書き込み操作のためにクラウドでホストされているインデックスの合計サイズです。
重要クラウドホスト型インデックスの合計サイズは、リアルタイムで変化する値であり、インデックスの過去の合計サイズではありません。
インデックスの数
現時点で書き込み操作のためにクラウドでホストされているインデックスの総数です。この値は、現在のシステムのリアルタイム値です。
重要インデックスの数は、リアルタイムで変化する値であり、インデックスの過去の総数ではありません。
書き込みホスティングステータス
有効:このインデックスのクラウド書き込みホスティングが有効になっています。デフォルトで有効になっています。
無効:このインデックスのクラウド書き込みホスティングがキャンセルされました。手動での無効化はサポートされていますが、無効化後の再有効化はサポートされていません。
説明インデックスのクラウド書き込みホスティングを手動で無効にすると、データはユーザークラスターに直接書き込まれます。無効にする前に、インデックスへのデータ書き込みが継続されているかどうかを確認し、ユーザークラスターの負荷状態を確認してください。そうしないと、ユーザークラスターの負荷が高くなるリスクがあります。
独立したインデックスのクラウド書き込みホスティング中は、インデックスデータはクラウドホスティングサービス Indexing Service に完全に保存され、クラウドホスティングのコストが増加します。ビジネス使用シナリオ(インデックスにまだデータが書き込まれているかどうかなど)に基づいて、インデックスの書き込みホスティングを手動で無効にする必要があるかどうかを評価してください。
説明nginx-log データストリームにはインデックスロールオーバーポリシーが設定されているため、クラウドホスティング サービスには最近生成されたバッキングインデックス(このシナリオでは .ds-nginx-log-2021.04.26-000004)のみが保存され、古いバッキングインデックスはクラウドホスティングから自動的に無効になります。
インデックスホスティングをキャンセルします。
独立したインデックスまたはロールオーバーポリシーのないインデックスは無期限にクラウドホスティングサービスに保持され、手動で無効にする必要があります。無効にすると、対応するインデックスの書き込みホスティングステータスは [無効] になります。
重要クラウドホスティングをキャンセルした後、クラウド Indexing Service 書き込みホスティング機能を再度有効にすることはできません。
Elasticsearch クラスターには、データストリーム(Data Stream)と独立したインデックス(Index)オブジェクトの両方を含めることができます。ホストされていないシステムインデックスを除き、他のすべてのインデックスはデフォルトでホスティングが有効になっています。
[インデックス管理] タブで、対応するインデックスの右側の列に [有効] と表示されている [書き込みホスティングステータス] トグルスイッチをクリックします。
[ホスティングのキャンセル] ダイアログボックスで、[OK] をクリックします。
このステップのサンプルコマンド:
POST /.ds-nginx-log-xxx/_cube/unfollow
ステップ 5:クラスタ情報を表示する
ノード可視化ページに移動すると、Indexing Service のリアルタイム書き込みトラフィックとデータ量の情報が表示されます。
[Indexing Service] セクションで、[1 日の合計書き込みトラフィック] をクリックして、[1 時間あたりの平均書き込みスループット] の曲線チャートを表示します。
説明Indexing Service の合計書き込みトラフィックのモニタリングは、リアルタイムではない 1 時間間隔で表示される静的なトレンドモニタリングチャートであり、モニタリングデータの表示遅延は最大 1 時間です。たとえば、14:00 から 14:59 の間に書き込まれた合計トラフィックは、モニタリングページの 14:00 のポイントで取得するには、15:10 以降まで待つ必要があります。
[モニタリングの詳細を表示] をクリックして、Grafana モニタリングにジャンプし、より詳細なモニタリングデータを確認します。
[Indexing Service] ページで、[合計ホストデータ量] をクリックして、[1 日の合計ホストデータ量] を表示します。
説明Indexing Service の合計書き込みトラフィックのモニタリングは、リアルタイムではない 1 時間間隔で表示される静的なトレンドモニタリングチャートであり、モニタリングデータの表示遅延は最大 1 時間です。たとえば、14:00 から 14:59 の間に書き込まれた合計データ量は、モニタリングページの 14:00 のポイントで取得するには、15:10 以降まで待つ必要があります。
ステップ 6:ログを分析する
Elasticsearch クラスターの Kibana コンソールにログインし、プロンプトに従って Kibana コンソールのホームページに移動します。
Kibana コンソールへのログイン方法の詳細については、「Kibana コンソールにログインする」をご参照ください。
説明この例では、Elasticsearch V7.10.0 クラスターを使用しています。 他のバージョンのクラスターでの操作は異なる場合があります。 コンソールでの実際の操作が優先されます。
インデックスパターンを作成します。
左上隅の
 をクリックします。
をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[スタック管理] ページの [Kibana] セクションで、[インデックスパターン] をクリックします。
[インデックスパターンの作成] をクリックします。
[インデックスパターンの作成] ページで、[インデックスパターン名] テキストボックスにインデックスパターン名を入力します。
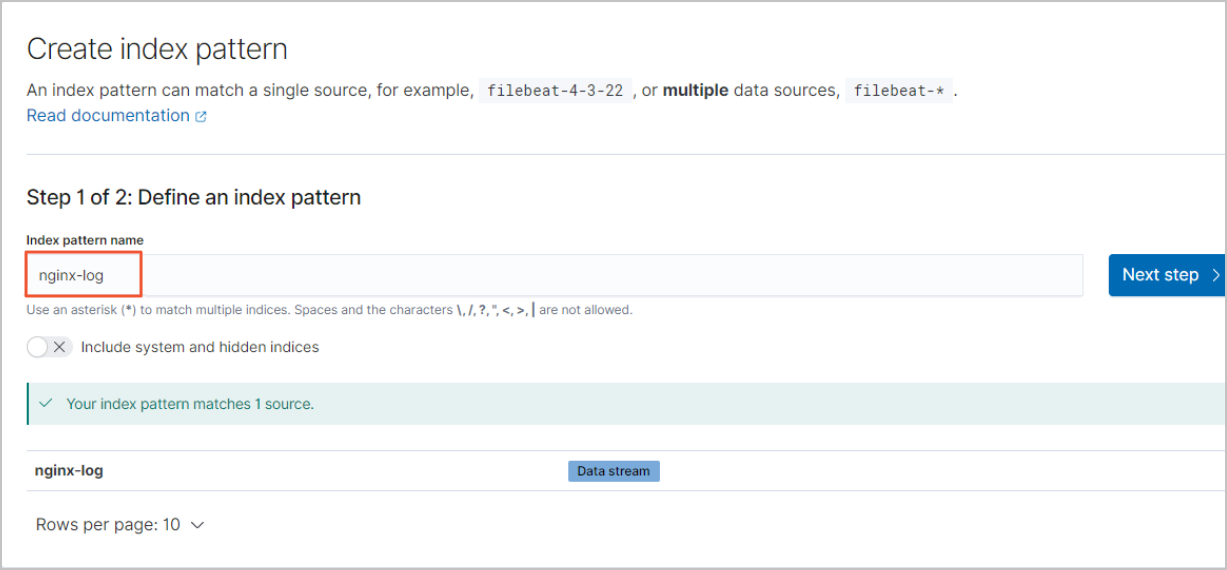 説明
説明インデックスパターン名 は、データストリーム名またはバッキングインデックス名のいずれかとして指定できます。
[設定] を構成します。
左上隅の
をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[ログ] ページで、[設定] タブをクリックします。
[ログインデックス] テキストボックスに、データストリーム名を入力します。
このトピックでは、データストリーム名 nginx-log を例として使用します。 他のフィールドのデフォルト構成はデータストリームデータの要件を満たしているため、変更する必要はありません。
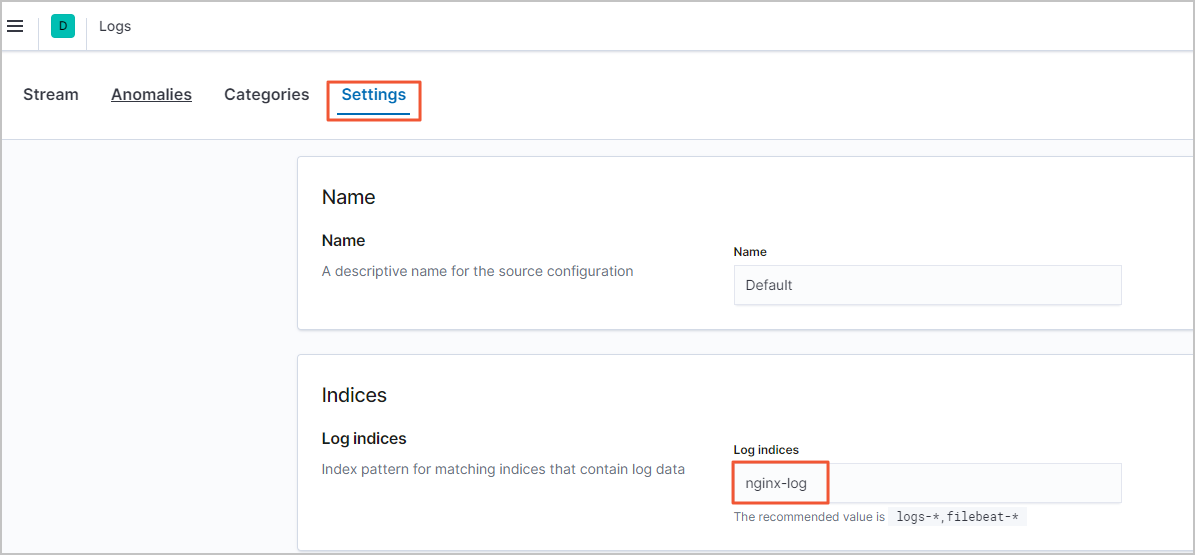
右下隅にある [適用] をクリックします。
リアルタイムログストリームデータを取得します。
[ログ] ページで、[ストリーム] タブをクリックします。
ページの右側にある [ライブストリーム] をクリックします。
[ストリーム] タブで、取得したリアルタイムデータストリームを表示します。
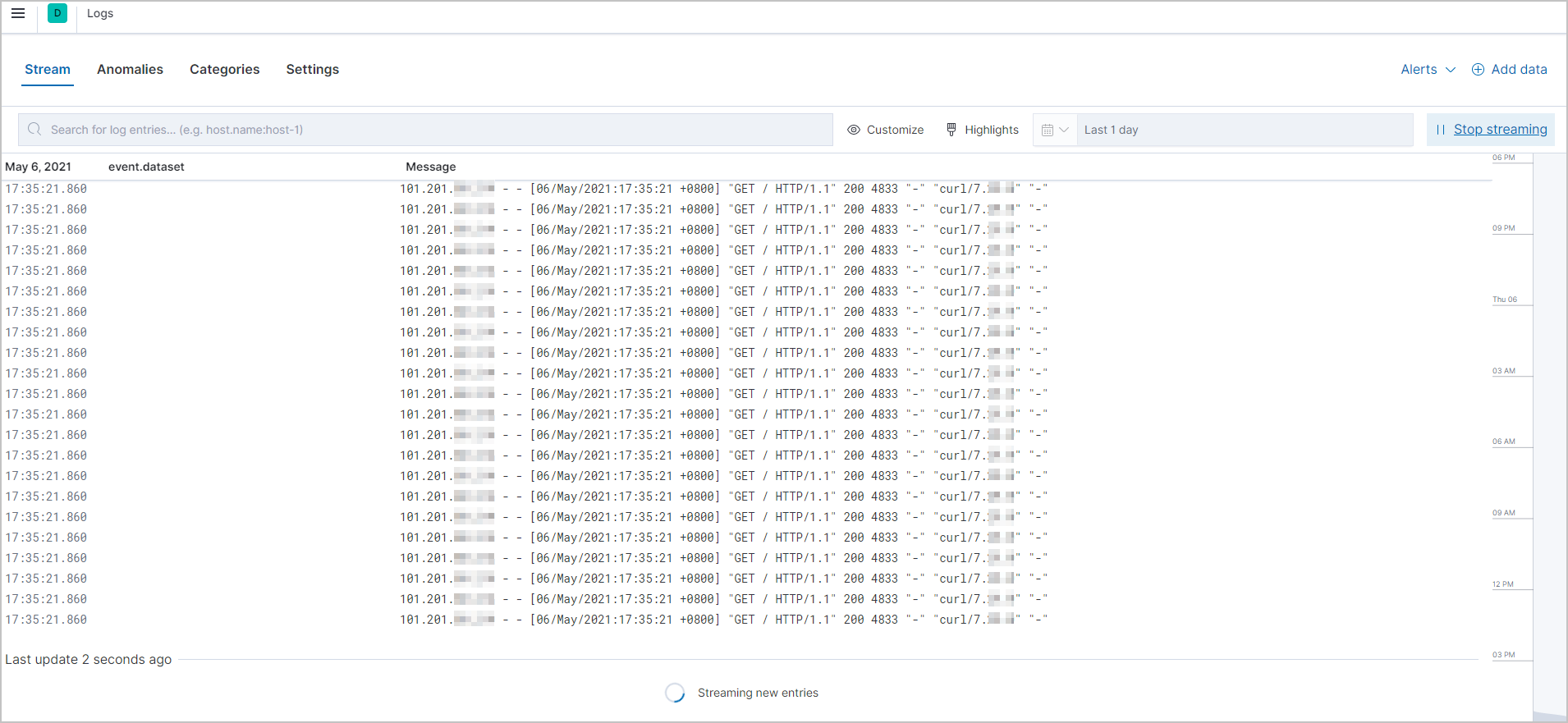
リアルタイムデータメトリックを取得します。
左上隅の
をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[ディスカバー] ページで、対応するインデックスを選択して、そのインデックスのリアルタイムデータメトリックを取得します。

詳細については、「Kibana ガイド」をご参照ください。
よくある質問
Q: インデキシング サービス インスタンスの書き込みホスト型インデックスの書き込みパラメーター(リフレッシュやマージなど)を構成すると、効果はありますか?
A: いいえ、効果はありません。インデキシング サービス インスタンスの書き込みホスト型インデックスは、すでにデフォルトの書き込みパラメーター構成を使用しており、ユーザー側の構成は効果がありません。デフォルトの書き込みパラメーター構成は次のとおりです。
"index.merge.policy.max_merged_segment" : "1024mb", // マージされたセグメントの最大サイズ
"index.refresh_interval" : "3s", // リフレッシュ間隔
"index.translog.durability" : "async", // トランザクションログの耐久性
"index.translog.flush_threshold_size" : "2gb", // トランザクションログのフラッシュしきい値サイズ
"index.translog.sync_interval" : "100s" // トランザクションログの同期間隔