Elasticsearch クラスターは、同じノードでインデックス作成と検索の両方を処理するため、書き込みトラフィックがバースト的または予測不能な場合でも、ピーク時の書き込みスループットに合わせてクラスターのサイズを決定する必要があります。Indexing Service を備えた Alibaba Cloud Elasticsearch Kernel-enhanced Edition クラスターは、すべての書き込み操作をマネージドクラウドサービスにオフロードし、クラスターのリソースを検索用に解放します。読み書き分離アーキテクチャに基づき、Indexing Service は、標準クラスターで書き込み負荷の高いワークロードを実行するコストの一部で、高スループット、低レイテンシーのインデックス作成を実現します。
Indexing Service は、中国 (香港) リージョンで利用可能です。他のリージョンでの提供開始にご期待ください。
ユースケース
Indexing Service は、1秒あたりの書き込みトランザクション数 (TPS) が高く、書き込みトラフィックの変動が大きく、秒間クエリ数 (QPS) が低い時系列データ分析向けに設計されています。一般的なワークロードは次のとおりです。
ログの取得と分析
メトリックのモニタリングと分析
インテリジェントなIoTハードウェアのデータ収集、モニタリング、分析
Indexing Service が有効になっている Kernel-enhanced Edition クラスターとご利用のクラスター間のデータ同期は、apack/cube/metadata/sync タスクに依存します。GET _cat/tasks?v を実行して、タスクステータスを確認します。このタスクを手動でクリアしないでください。タスクがクリアされた場合は、データ書き込みの中断を避けるため、POST /_cube/meta/sync を実行してすぐに復元してください。
仕組み
従来の Elasticsearch クラスターは、同じノードでインデックス作成と検索の両方を処理し、書き込みスループットとクラスター容量を密接に結合します。書き込みトラフィックが急増すると、検索レイテンシーを含め、クラスター全体に影響が出ます。
Indexing Service はこれらの懸念を分離します。
書き込みパス: Indexing Service はすべての書き込みトラフィックを受信し、専用の書き込みホスティング環境でインデックス作成を処理します。
読み取りパス: ご利用のクラスターは、書き込みホスティング環境からレプリケートされたデータに対して検索クエリを処理します。
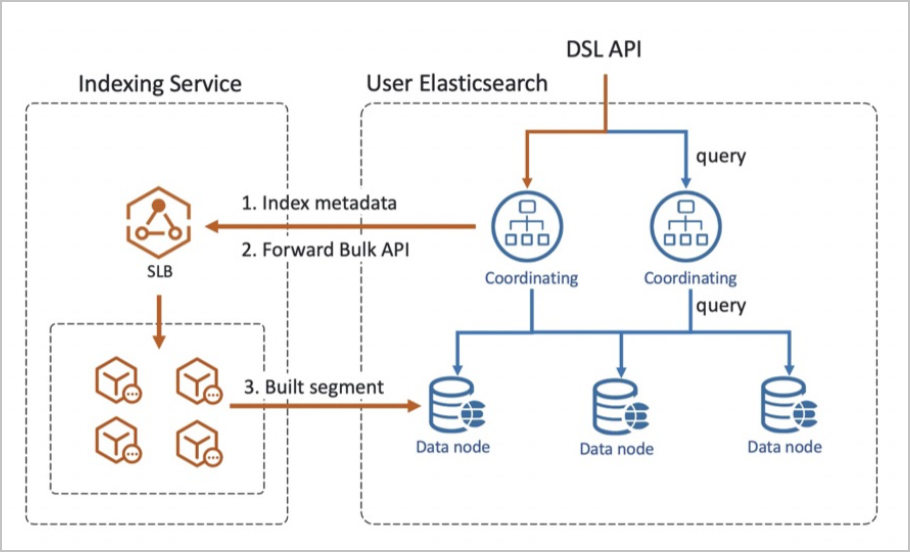
このアーキテクチャにより、ピーク時の書き込みスループットに合わせてクラスターのサイズを決定する必要がなくなります。Indexing Service はバックグラウンドで書き込みリソースをプロビジョニングおよびスケーリングし、ご利用のクラスターは検索パフォーマンスに集中できます。
書き込みホスティング環境を強化する3つの主要テクノロジーは次のとおりです。
| テクノロジー | 説明 |
|---|---|
| インデックスの物理レプリケーション | セグメントレベルでクラスター間でデータをリアルタイムにレプリケートし、書き込みホスティングクラスターとご利用のクラスターを同期させます。 |
| コンピューティングとストレージの分離 | 書き込みコンピューティングとストレージを分離し、各層の独立したスケーリングを可能にします。 |
| faster-bulk | Alibaba Cloud のカーネル最適化により、バルクインデックス作成スループットが大幅に加速されます。 |
メリット
| メリット | 詳細 |
|---|---|
| 低コスト | 書き込み操作の計算リソースは平均60%削減されます。ピーク容量ではなく、実際の書き込み量に応じて支払います。 |
| 弾力的なスケーリング | 書き込みリソースはトラフィックの変動に合わせて自動的にスケーリングされます。データ移行は不要です。 |
| 運用およびメンテナンス (O&M) なし | Indexing Service はクラウド内のすべての書き込み操作を管理し、書き込み関連のクラスター管理オーバーヘッドを排除します。 |
| 高パフォーマンス | 物理レプリケーション、コンピューティングとストレージの分離、faster-bulk を通じたプロフェッショナルグレードの書き込み最適化。 |
| 低レイテンシー | セグメントレベルのクラスター間物理レプリケーションにより、飽和した書き込み条件でのデータレイテンシーは数百ミリ秒の範囲に保たれます。 |
| 高可用性 | リージョン間のマルチクラスターバックアップによる地理的ディザスタリカバリをサポートします。クラスター障害が発生した場合、インデックスを別の機能しているクラスターに転送してホスティングできます。 |
課金
Indexing Service は、以下の要素からなる書き込みホスティング料金を請求します。
書き込みトラフィック料金: 書き込みホスティング環境への書き込みトラフィック量に基づきます。
ストレージ料金: ホスティングに使用されるストレージスペースに基づきます。
書き込みホスティング料金は、ご利用のクラスターがサブスクリプション課金または従量課金を使用しているかどうかにかかわらず適用されます。料金詳細については、「Elasticsearch の課金」をご参照ください。
Indexing Service は、ご利用のクラスターで書き込み操作を処理するために必要なリソースを削減し、クラスター全体のコストを削減します。
使用制限
Indexing Service は、書き込みスループット、ドキュメント数、インデックス構成に制限を設けています。
クラスターレベルの使用制限
これらはハードリミットです。これらを超過すると HTTP 429 が返されます。
| 項目 | 制限 | 超過時のエラー |
|---|---|---|
| 書き込みトラフィック | 200 MB/秒 | Inflow Quota Exceed。上限の引き上げをリクエストするには、チケットを送信チケットを送信してください。 |
| 1秒あたりの書き込みドキュメント数 | 200,000 ドキュメント/秒 | Write QPS Exceed。上限の引き上げをリクエストするには、チケットを送信チケットを送信してください。 |
| Put Mapping リクエスト | 50 TPS | PutMappingRequest blocked。 |
頻繁な Put Mapping リクエストは、大量の計算リソースを消費し、ホスティングサービスの安定性に影響を与える可能性があります。Put Mapping 操作を最小限に抑えるため、データを書き込む前にインデックステンプレートを定義してください。
シャードレベルの使用制限
これらはソフトリミットです。制限に達した場合でもサービスは継続されますが、品質は保証されません。
| 項目 | ソフトリミット | エラーコード |
|---|---|---|
| 書き込みトラフィック (プライマリキーなし) | 10 MB/秒/シャード | write_size blocked |
| 書き込みトラフィック (プライマリキーあり) | 5 MB/秒/シャード | write_size blocked |
| 1秒あたりの書き込みドキュメント数 | 5,000 ドキュメント/秒/シャード | — |
| インデックスあたりのシャード数 | 300 シャード | — |
構成の使用制限
Indexing Service は以下のパラメーターを自動的に管理します。これらのパラメーターに対するクライアント側の構成は有効になりません。
| パラメーター | デフォルト値 | 備考 |
|---|---|---|
index.refresh_interval | 30s | Indexing Service によって自動構成されます。 |
index.translog.durability | async | 非同期トランスログ書き込みを有効にするには、async に設定します。 |
index.merge.policy.max_merged_segment | 1024mb | 自動構成。 |
index.translog.flush_threshold_size | 2gb | 自動構成。 |
index.translog.sync_interval | 100s | 自動構成。 |
インデックスレベルの使用制限
| 項目 | 制限 |
|---|---|
ライフサイクル freeze パラメーター | インデックスライフサイクル内で変更することはできません。 |
| Shrink 操作 | ホストされているインデックスは、Index Lifecycle Management (ILM) の Shrink 操作と互換性がありません。Shrink 操作は、インデックスがホストされていない場合にのみ実行してください。「Shrink」をご参照ください。 |
| ホスティングの自動キャンセル | インデックスがホストされてから3日後にホスティングは自動的に無効になります。この期間は、ご利用のデータライフサイクルの要件に合わせて変更してください。 |
| Ingest Node の前処理 | インデックス作成前にドキュメントを前処理するために Ingest Node を使用する場合、前処理はホスティング環境ではなく、ご利用のクラスターで実行されます。この構成では、非常に複雑な処理ロジックを避けてください。詳細については、「Ingest Node」をご参照ください。 |
パフォーマンス試験
以下の結果は、同一のハードウェア仕様における Indexing Service を備えた Kernel-enhanced Edition と Standard Edition クラスター間の書き込みパフォーマンスを比較したものです。
これらの結果は、以下に説明するテスト環境とデータセットに基づいています。実際のパフォーマンスは、ご利用のデータ特性、インデックス構成、ワークロードパターンによって異なります。
テスト環境
試験結果
| 仕様 (データノード3台) | クラスターエディション | 書き込みTPS | 書き込み可視化遅延 |
|---|---|---|---|
| 2 コア、8 GB | Standard Edition | 24,883 | 5 秒 |
| 2 コア、8 GB | Indexing Service を備えた Kernel-enhanced Edition | 226,649 | 6 秒 |
| 4 コア、16 GB | Standard Edition | 52,372 | 5 秒 |
| 4 コア、16 GB | Indexing Service を備えた Kernel-enhanced Edition | 419,574 | 6 秒 |
| 8 コア、32 GB | Standard Edition | 110,277 | 5 秒 |
| 8 コア、32 GB | Indexing Service を備えた Kernel-enhanced Edition | 804,010 | 6 秒 |
Standard Edition と比較したパフォーマンス向上
| 仕様 (3ノード) | 書き込みTPSの向上 |
|---|---|
| 2 コア、8 GB | 910% |
| 4 コア、16 GB | 801% |
| 8 コア、32 GB | 729% |